jalviewX
File EnsemblGene.java
Coverage histogram
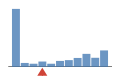
47% of files have more coverage
Classes
| Class | Line # | Actions | ||||
|---|---|---|---|---|---|---|
| EnsemblGene | 52 | 160 | 60 | 177 |
Contributing tests
This file is covered by 85 tests.
.
Source view
| 1 | /* | |
| 2 | * Jalview - A Sequence Alignment Editor and Viewer ($$Version-Rel$$) | |
| 3 | * Copyright (C) $$Year-Rel$$ The Jalview Authors | |
| 4 | * | |
| 5 | * This file is part of Jalview. | |
| 6 | * | |
| 7 | * Jalview is free software: you can redistribute it and/or | |
| 8 | * modify it under the terms of the GNU General Public License | |
| 9 | * as published by the Free Software Foundation, either version 3 | |
| 10 | * of the License, or (at your option) any later version. | |
| 11 | * | |
| 12 | * Jalview is distributed in the hope that it will be useful, but | |
| 13 | * WITHOUT ANY WARRANTY; without even the implied warranty | |
| 14 | * of MERCHANTABILITY or FITNESS FOR A PARTICULAR | |
| 15 | * PURPOSE. See the GNU General Public License for more details. | |
| 16 | * | |
| 17 | * You should have received a copy of the GNU General Public License | |
| 18 | * along with Jalview. If not, see <http://www.gnu.org/licenses/>. | |
| 19 | * The Jalview Authors are detailed in the 'AUTHORS' file. | |
| 20 | */ | |
| 21 | package jalview.ext.ensembl; | |
| 22 | ||
| 23 | import jalview.api.FeatureColourI; | |
| 24 | import jalview.api.FeatureSettingsModelI; | |
| 25 | import jalview.datamodel.AlignmentI; | |
| 26 | import jalview.datamodel.DBRefEntry; | |
| 27 | import jalview.datamodel.GeneLociI; | |
| 28 | import jalview.datamodel.Sequence; | |
| 29 | import jalview.datamodel.SequenceFeature; | |
| 30 | import jalview.datamodel.SequenceI; | |
| 31 | import jalview.datamodel.features.SequenceFeatures; | |
| 32 | import jalview.io.gff.SequenceOntologyFactory; | |
| 33 | import jalview.io.gff.SequenceOntologyI; | |
| 34 | import jalview.schemes.FeatureColour; | |
| 35 | import jalview.schemes.FeatureSettingsAdapter; | |
| 36 | import jalview.util.MapList; | |
| 37 | ||
| 38 | import java.awt.Color; | |
| 39 | import java.io.UnsupportedEncodingException; | |
| 40 | import java.net.URLDecoder; | |
| 41 | import java.util.ArrayList; | |
| 42 | import java.util.Arrays; | |
| 43 | import java.util.List; | |
| 44 | ||
| 45 | import com.stevesoft.pat.Regex; | |
| 46 | ||
| 47 | /** | |
| 48 | * A class that fetches genomic sequence and all transcripts for an Ensembl gene | |
| 49 | * | |
| 50 | * @author gmcarstairs | |
| 51 | */ | |
| 52 | public class EnsemblGene extends EnsemblSeqProxy | |
| 53 | { | |
| 54 | private static final String GENE_PREFIX = "gene:"; | |
| 55 | ||
| 56 | /* | |
| 57 | * accepts anything as we will attempt lookup of gene or | |
| 58 | * transcript id or gene name | |
| 59 | */ | |
| 60 | private static final Regex ACCESSION_REGEX = new Regex(".*"); | |
| 61 | ||
| 62 | private static final EnsemblFeatureType[] FEATURES_TO_FETCH = { | |
| 63 | EnsemblFeatureType.gene, EnsemblFeatureType.transcript, | |
| 64 | EnsemblFeatureType.exon, EnsemblFeatureType.cds, | |
| 65 | EnsemblFeatureType.variation }; | |
| 66 | ||
| 67 | /** | |
| 68 | * Default constructor (to use rest.ensembl.org) | |
| 69 | */ | |
| 70 | 18 |  public EnsemblGene() public EnsemblGene() |
| 71 | { | |
| 72 | 18 | super(); |
| 73 | } | |
| 74 | ||
| 75 | /** | |
| 76 | * Constructor given the target domain to fetch data from | |
| 77 | * | |
| 78 | * @param d | |
| 79 | */ | |
| 80 | 0 | public EnsemblGene(String d) |
| 81 | { | |
| 82 | 0 | super(d); |
| 83 | } | |
| 84 | ||
| 85 | 1108 | @Override |
| 86 | public String getDbName() | |
| 87 | { | |
| 88 | 1108 | return "ENSEMBL"; |
| 89 | } | |
| 90 | ||
| 91 | 0 | @Override |
| 92 | protected EnsemblFeatureType[] getFeaturesToFetch() | |
| 93 | { | |
| 94 | 0 | return FEATURES_TO_FETCH; |
| 95 | } | |
| 96 | ||
| 97 | 0 | @Override |
| 98 | protected EnsemblSeqType getSourceEnsemblType() | |
| 99 | { | |
| 100 | 0 | return EnsemblSeqType.GENOMIC; |
| 101 | } | |
| 102 | ||
| 103 | 0 | @Override |
| 104 | protected String getObjectType() | |
| 105 | { | |
| 106 | 0 | return OBJECT_TYPE_GENE; |
| 107 | } | |
| 108 | ||
| 109 | /** | |
| 110 | * Returns an alignment containing the gene(s) for the given gene or | |
| 111 | * transcript identifier, or external identifier (e.g. Uniprot id). If given a | |
| 112 | * gene name or external identifier, returns any related gene sequences found | |
| 113 | * for model organisms. If only a single gene is queried for, then its | |
| 114 | * transcripts are also retrieved and added to the alignment. <br> | |
| 115 | * Method: | |
| 116 | * <ul> | |
| 117 | * <li>resolves a transcript identifier by looking up its parent gene id</li> | |
| 118 | * <li>resolves an external identifier by looking up xref-ed gene ids</li> | |
| 119 | * <li>fetches the gene sequence</li> | |
| 120 | * <li>fetches features on the sequence</li> | |
| 121 | * <li>identifies "transcript" features whose Parent is the requested | |
| 122 | * gene</li> | |
| 123 | * <li>fetches the transcript sequence for each transcript</li> | |
| 124 | * <li>makes a mapping from the gene to each transcript</li> | |
| 125 | * <li>copies features from gene to transcript sequences</li> | |
| 126 | * <li>fetches the protein sequence for each transcript, maps and saves it as | |
| 127 | * a cross-reference</li> | |
| 128 | * <li>aligns each transcript against the gene sequence based on the position | |
| 129 | * mappings</li> | |
| 130 | * </ul> | |
| 131 | * | |
| 132 | * @param query | |
| 133 | * a single gene or transcript identifier or gene name | |
| 134 | * @return an alignment containing a gene, and possibly transcripts, or null | |
| 135 | */ | |
| 136 | 0 | @Override |
| 137 | public AlignmentI getSequenceRecords(String query) throws Exception | |
| 138 | { | |
| 139 | /* | |
| 140 | * convert to a non-duplicated list of gene identifiers | |
| 141 | */ | |
| 142 | 0 | List<String> geneIds = getGeneIds(query); |
| 143 | ||
| 144 | 0 | AlignmentI al = null; |
| 145 | 0 | for (String geneId : geneIds) |
| 146 | { | |
| 147 | /* | |
| 148 | * fetch the gene sequence(s) with features and xrefs | |
| 149 | */ | |
| 150 | 0 | AlignmentI geneAlignment = super.getSequenceRecords(geneId); |
| 151 | 0 | if (geneAlignment == null) |
| 152 | { | |
| 153 | 0 | continue; |
| 154 | } | |
| 155 | ||
| 156 | 0 | if (geneAlignment.getHeight() == 1) |
| 157 | { | |
| 158 | // ensure id has 'correct' case for the Ensembl identifier | |
| 159 | 0 | geneId = geneAlignment.getSequenceAt(0).getName(); |
| 160 | ||
| 161 | 0 | findGeneLoci(geneAlignment.getSequenceAt(0), geneId); |
| 162 | ||
| 163 | 0 | getTranscripts(geneAlignment, geneId); |
| 164 | } | |
| 165 | 0 | if (al == null) |
| 166 | { | |
| 167 | 0 | al = geneAlignment; |
| 168 | } | |
| 169 | else | |
| 170 | { | |
| 171 | 0 | al.append(geneAlignment); |
| 172 | } | |
| 173 | } | |
| 174 | 0 | return al; |
| 175 | } | |
| 176 | ||
| 177 | /** | |
| 178 | * Calls the /lookup/id REST service, parses the response for gene | |
| 179 | * coordinates, and if successful, adds these to the sequence. If this fails, | |
| 180 | * fall back on trying to parse the sequence description in case it is in | |
| 181 | * Ensembl-gene format e.g. chromosome:GRCh38:17:45051610:45109016:1. | |
| 182 | * | |
| 183 | * @param seq | |
| 184 | * @param geneId | |
| 185 | */ | |
| 186 | 0 | void findGeneLoci(SequenceI seq, String geneId) |
| 187 | { | |
| 188 | 0 | GeneLociI geneLoci = new EnsemblLookup(getDomain()).getGeneLoci(geneId); |
| 189 | 0 | if (geneLoci != null) |
| 190 | { | |
| 191 | 0 | seq.setGeneLoci(geneLoci.getSpeciesId(), geneLoci.getAssemblyId(), |
| 192 | geneLoci.getChromosomeId(), geneLoci.getMap()); | |
| 193 | } | |
| 194 | else | |
| 195 | { | |
| 196 | 0 | parseChromosomeLocations(seq); |
| 197 | } | |
| 198 | } | |
| 199 | ||
| 200 | /** | |
| 201 | * Parses and saves fields of an Ensembl-style description e.g. | |
| 202 | * chromosome:GRCh38:17:45051610:45109016:1 | |
| 203 | * | |
| 204 | * @param seq | |
| 205 | */ | |
| 206 | 0 | boolean parseChromosomeLocations(SequenceI seq) |
| 207 | { | |
| 208 | 0 | String description = seq.getDescription(); |
| 209 | 0 | if (description == null) |
| 210 | { | |
| 211 | 0 | return false; |
| 212 | } | |
| 213 | 0 | String[] tokens = description.split(":"); |
| 214 | 0 | if (tokens.length == 6 && tokens[0].startsWith(DBRefEntry.CHROMOSOME)) |
| 215 | { | |
| 216 | 0 | String ref = tokens[1]; |
| 217 | 0 | String chrom = tokens[2]; |
| 218 | 0 | try |
| 219 | { | |
| 220 | 0 | int chStart = Integer.parseInt(tokens[3]); |
| 221 | 0 | int chEnd = Integer.parseInt(tokens[4]); |
| 222 | 0 | boolean forwardStrand = "1".equals(tokens[5]); |
| 223 | 0 | String species = ""; // not known here |
| 224 | 0 | int[] from = new int[] { seq.getStart(), seq.getEnd() }; |
| 225 | 0 | int[] to = new int[] { forwardStrand ? chStart : chEnd, |
| 226 | 0 | forwardStrand ? chEnd : chStart }; |
| 227 | 0 | MapList map = new MapList(from, to, 1, 1); |
| 228 | 0 | seq.setGeneLoci(species, ref, chrom, map); |
| 229 | 0 | return true; |
| 230 | } catch (NumberFormatException e) | |
| 231 | { | |
| 232 | 0 | System.err.println("Bad integers in description " + description); |
| 233 | } | |
| 234 | } | |
| 235 | 0 | return false; |
| 236 | } | |
| 237 | ||
| 238 | /** | |
| 239 | * Converts a query, which may contain one or more gene, transcript, or | |
| 240 | * external (to Ensembl) identifiers, into a non-redundant list of gene | |
| 241 | * identifiers. | |
| 242 | * | |
| 243 | * @param accessions | |
| 244 | * @return | |
| 245 | */ | |
| 246 | 0 | List<String> getGeneIds(String accessions) |
| 247 | { | |
| 248 | 0 | List<String> geneIds = new ArrayList<>(); |
| 249 | ||
| 250 | 0 | for (String acc : accessions.split(getAccessionSeparator())) |
| 251 | { | |
| 252 | /* | |
| 253 | * First try lookup as an Ensembl (gene or transcript) identifier | |
| 254 | */ | |
| 255 | 0 | String geneId = new EnsemblLookup(getDomain()).getGeneId(acc); |
| 256 | 0 | if (geneId != null) |
| 257 | { | |
| 258 | 0 | if (!geneIds.contains(geneId)) |
| 259 | { | |
| 260 | 0 | geneIds.add(geneId); |
| 261 | } | |
| 262 | } | |
| 263 | else | |
| 264 | { | |
| 265 | /* | |
| 266 | * if given a gene or other external name, lookup and fetch | |
| 267 | * the corresponding gene for all model organisms | |
| 268 | */ | |
| 269 | 0 | List<String> ids = new EnsemblSymbol(getDomain(), getDbSource(), |
| 270 | getDbVersion()).getGeneIds(acc); | |
| 271 | 0 | for (String id : ids) |
| 272 | { | |
| 273 | 0 | if (!geneIds.contains(id)) |
| 274 | { | |
| 275 | 0 | geneIds.add(id); |
| 276 | } | |
| 277 | } | |
| 278 | } | |
| 279 | } | |
| 280 | 0 | return geneIds; |
| 281 | } | |
| 282 | ||
| 283 | /** | |
| 284 | * Constructs all transcripts for the gene, as identified by "transcript" | |
| 285 | * features whose Parent is the requested gene. The coding transcript | |
| 286 | * sequences (i.e. with introns omitted) are added to the alignment. | |
| 287 | * | |
| 288 | * @param al | |
| 289 | * @param accId | |
| 290 | * @throws Exception | |
| 291 | */ | |
| 292 | 0 | protected void getTranscripts(AlignmentI al, String accId) |
| 293 | throws Exception | |
| 294 | { | |
| 295 | 0 | SequenceI gene = al.getSequenceAt(0); |
| 296 | 0 | List<SequenceFeature> transcriptFeatures = getTranscriptFeatures(accId, |
| 297 | gene); | |
| 298 | ||
| 299 | 0 | for (SequenceFeature transcriptFeature : transcriptFeatures) |
| 300 | { | |
| 301 | 0 | makeTranscript(transcriptFeature, al, gene); |
| 302 | } | |
| 303 | ||
| 304 | 0 | clearGeneFeatures(gene); |
| 305 | } | |
| 306 | ||
| 307 | /** | |
| 308 | * Remove unwanted features (transcript, exon, CDS) from the gene sequence | |
| 309 | * after we have used them to derive transcripts and transfer features | |
| 310 | * | |
| 311 | * @param gene | |
| 312 | */ | |
| 313 | 0 | protected void clearGeneFeatures(SequenceI gene) |
| 314 | { | |
| 315 | /* | |
| 316 | * Note we include NMD_transcript_variant here because it behaves like | |
| 317 | * 'transcript' in Ensembl, although strictly speaking it is not | |
| 318 | * (it is a sub-type of sequence_variant) | |
| 319 | */ | |
| 320 | 0 | String[] soTerms = new String[] { |
| 321 | SequenceOntologyI.NMD_TRANSCRIPT_VARIANT, | |
| 322 | SequenceOntologyI.TRANSCRIPT, SequenceOntologyI.EXON, | |
| 323 | SequenceOntologyI.CDS }; | |
| 324 | 0 | List<SequenceFeature> sfs = gene.getFeatures().getFeaturesByOntology( |
| 325 | soTerms); | |
| 326 | 0 | for (SequenceFeature sf : sfs) |
| 327 | { | |
| 328 | 0 | gene.deleteFeature(sf); |
| 329 | } | |
| 330 | } | |
| 331 | ||
| 332 | /** | |
| 333 | * Constructs a spliced transcript sequence by finding 'exon' features for the | |
| 334 | * given id (or failing that 'CDS'). Copies features on to the new sequence. | |
| 335 | * 'Aligns' the new sequence against the gene sequence by padding with gaps, | |
| 336 | * and adds it to the alignment. | |
| 337 | * | |
| 338 | * @param transcriptFeature | |
| 339 | * @param al | |
| 340 | * the alignment to which to add the new sequence | |
| 341 | * @param gene | |
| 342 | * the parent gene sequence, with features | |
| 343 | * @return | |
| 344 | */ | |
| 345 | 0 | SequenceI makeTranscript(SequenceFeature transcriptFeature, AlignmentI al, |
| 346 | SequenceI gene) | |
| 347 | { | |
| 348 | 0 | String accId = getTranscriptId(transcriptFeature); |
| 349 | 0 | if (accId == null) |
| 350 | { | |
| 351 | 0 | return null; |
| 352 | } | |
| 353 | ||
| 354 | /* | |
| 355 | * NB we are mapping from gene sequence (not genome), so do not | |
| 356 | * need to check for reverse strand (gene and transcript sequences | |
| 357 | * are in forward sense) | |
| 358 | */ | |
| 359 | ||
| 360 | /* | |
| 361 | * make a gene-length sequence filled with gaps | |
| 362 | * we will fill in the bases for transcript regions | |
| 363 | */ | |
| 364 | 0 | char[] seqChars = new char[gene.getLength()]; |
| 365 | 0 | Arrays.fill(seqChars, al.getGapCharacter()); |
| 366 | ||
| 367 | /* | |
| 368 | * look for exon features of the transcript, failing that for CDS | |
| 369 | * (for example ENSG00000124610 has 1 CDS but no exon features) | |
| 370 | */ | |
| 371 | 0 | String parentId = "transcript:" + accId; |
| 372 | 0 | List<SequenceFeature> splices = findFeatures(gene, |
| 373 | SequenceOntologyI.EXON, parentId); | |
| 374 | 0 | if (splices.isEmpty()) |
| 375 | { | |
| 376 | 0 | splices = findFeatures(gene, SequenceOntologyI.CDS, parentId); |
| 377 | } | |
| 378 | 0 | SequenceFeatures.sortFeatures(splices, true); |
| 379 | ||
| 380 | 0 | int transcriptLength = 0; |
| 381 | 0 | final char[] geneChars = gene.getSequence(); |
| 382 | 0 | int offset = gene.getStart(); // to convert to 0-based positions |
| 383 | 0 | List<int[]> mappedFrom = new ArrayList<>(); |
| 384 | ||
| 385 | 0 | for (SequenceFeature sf : splices) |
| 386 | { | |
| 387 | 0 | int start = sf.getBegin() - offset; |
| 388 | 0 | int end = sf.getEnd() - offset; |
| 389 | 0 | int spliceLength = end - start + 1; |
| 390 | 0 | System.arraycopy(geneChars, start, seqChars, start, spliceLength); |
| 391 | 0 | transcriptLength += spliceLength; |
| 392 | 0 | mappedFrom.add(new int[] { sf.getBegin(), sf.getEnd() }); |
| 393 | } | |
| 394 | ||
| 395 | 0 | Sequence transcript = new Sequence(accId, seqChars, 1, |
| 396 | transcriptLength); | |
| 397 | ||
| 398 | /* | |
| 399 | * Ensembl has gene name as transcript Name | |
| 400 | * EnsemblGenomes doesn't, but has a url-encoded description field | |
| 401 | */ | |
| 402 | 0 | String description = (String) transcriptFeature.getValue(NAME); |
| 403 | 0 | if (description == null) |
| 404 | { | |
| 405 | 0 | description = (String) transcriptFeature.getValue(DESCRIPTION); |
| 406 | } | |
| 407 | 0 | if (description != null) |
| 408 | { | |
| 409 | 0 | try |
| 410 | { | |
| 411 | 0 | transcript.setDescription(URLDecoder.decode(description, "UTF-8")); |
| 412 | } catch (UnsupportedEncodingException e) | |
| 413 | { | |
| 414 | 0 | e.printStackTrace(); // as if |
| 415 | } | |
| 416 | } | |
| 417 | 0 | transcript.createDatasetSequence(); |
| 418 | ||
| 419 | 0 | al.addSequence(transcript); |
| 420 | ||
| 421 | /* | |
| 422 | * transfer features to the new sequence; we use EnsemblCdna to do this, | |
| 423 | * to filter out unwanted features types (see method retainFeature) | |
| 424 | */ | |
| 425 | 0 | List<int[]> mapTo = new ArrayList<>(); |
| 426 | 0 | mapTo.add(new int[] { 1, transcriptLength }); |
| 427 | 0 | MapList mapping = new MapList(mappedFrom, mapTo, 1, 1); |
| 428 | 0 | EnsemblCdna cdna = new EnsemblCdna(getDomain()); |
| 429 | 0 | cdna.transferFeatures(gene.getFeatures().getPositionalFeatures(), |
| 430 | transcript.getDatasetSequence(), mapping, parentId); | |
| 431 | ||
| 432 | 0 | mapTranscriptToChromosome(transcript, gene, mapping); |
| 433 | ||
| 434 | /* | |
| 435 | * fetch and save cross-references | |
| 436 | */ | |
| 437 | 0 | cdna.getCrossReferences(transcript); |
| 438 | ||
| 439 | /* | |
| 440 | * and finally fetch the protein product and save as a cross-reference | |
| 441 | */ | |
| 442 | 0 | cdna.addProteinProduct(transcript); |
| 443 | ||
| 444 | 0 | return transcript; |
| 445 | } | |
| 446 | ||
| 447 | /** | |
| 448 | * If the gene has a mapping to chromosome coordinates, derive the transcript | |
| 449 | * chromosome regions and save on the transcript sequence | |
| 450 | * | |
| 451 | * @param transcript | |
| 452 | * @param gene | |
| 453 | * @param mapping | |
| 454 | * the mapping from gene to transcript positions | |
| 455 | */ | |
| 456 | 0 | protected void mapTranscriptToChromosome(SequenceI transcript, |
| 457 | SequenceI gene, MapList mapping) | |
| 458 | { | |
| 459 | 0 | GeneLociI loci = gene.getGeneLoci(); |
| 460 | 0 | if (loci == null) |
| 461 | { | |
| 462 | 0 | return; |
| 463 | } | |
| 464 | ||
| 465 | 0 | MapList geneMapping = loci.getMap(); |
| 466 | ||
| 467 | 0 | List<int[]> exons = mapping.getFromRanges(); |
| 468 | 0 | List<int[]> transcriptLoci = new ArrayList<>(); |
| 469 | ||
| 470 | 0 | for (int[] exon : exons) |
| 471 | { | |
| 472 | 0 | transcriptLoci.add(geneMapping.locateInTo(exon[0], exon[1])); |
| 473 | } | |
| 474 | ||
| 475 | 0 | List<int[]> transcriptRange = Arrays.asList(new int[] { |
| 476 | transcript.getStart(), transcript.getEnd() }); | |
| 477 | 0 | MapList mapList = new MapList(transcriptRange, transcriptLoci, 1, 1); |
| 478 | ||
| 479 | 0 | transcript.setGeneLoci(loci.getSpeciesId(), loci.getAssemblyId(), |
| 480 | loci.getChromosomeId(), mapList); | |
| 481 | } | |
| 482 | ||
| 483 | /** | |
| 484 | * Returns the 'transcript_id' property of the sequence feature (or null) | |
| 485 | * | |
| 486 | * @param feature | |
| 487 | * @return | |
| 488 | */ | |
| 489 | 0 | protected String getTranscriptId(SequenceFeature feature) |
| 490 | { | |
| 491 | 0 | return (String) feature.getValue("transcript_id"); |
| 492 | } | |
| 493 | ||
| 494 | /** | |
| 495 | * Returns a list of the transcript features on the sequence whose Parent is | |
| 496 | * the gene for the accession id. | |
| 497 | * <p> | |
| 498 | * Transcript features are those of type "transcript", or any of its sub-types | |
| 499 | * in the Sequence Ontology e.g. "mRNA", "processed_transcript". We also | |
| 500 | * include "NMD_transcript_variant", because this type behaves like a | |
| 501 | * transcript identifier in Ensembl, although strictly speaking it is not in | |
| 502 | * the SO. | |
| 503 | * | |
| 504 | * @param accId | |
| 505 | * @param geneSequence | |
| 506 | * @return | |
| 507 | */ | |
| 508 | 1 | protected List<SequenceFeature> getTranscriptFeatures(String accId, |
| 509 | SequenceI geneSequence) | |
| 510 | { | |
| 511 | 1 | List<SequenceFeature> transcriptFeatures = new ArrayList<>(); |
| 512 | ||
| 513 | 1 | String parentIdentifier = GENE_PREFIX + accId; |
| 514 | ||
| 515 | 1 | List<SequenceFeature> sfs = geneSequence.getFeatures() |
| 516 | .getFeaturesByOntology(SequenceOntologyI.TRANSCRIPT); | |
| 517 | 1 | sfs.addAll(geneSequence.getFeatures().getPositionalFeatures( |
| 518 | SequenceOntologyI.NMD_TRANSCRIPT_VARIANT)); | |
| 519 | ||
| 520 | 1 | for (SequenceFeature sf : sfs) |
| 521 | { | |
| 522 | 4 | String parent = (String) sf.getValue(PARENT); |
| 523 | 4 | if (parentIdentifier.equalsIgnoreCase(parent)) |
| 524 | { | |
| 525 | 3 | transcriptFeatures.add(sf); |
| 526 | } | |
| 527 | } | |
| 528 | ||
| 529 | 1 | return transcriptFeatures; |
| 530 | } | |
| 531 | ||
| 532 | 0 | @Override |
| 533 | public String getDescription() | |
| 534 | { | |
| 535 | 0 | return "Fetches all transcripts and variant features for a gene or transcript"; |
| 536 | } | |
| 537 | ||
| 538 | /** | |
| 539 | * Default test query is a gene id (can also enter a transcript id) | |
| 540 | */ | |
| 541 | 0 | @Override |
| 542 | public String getTestQuery() | |
| 543 | { | |
| 544 | 0 | return "ENSG00000157764"; // BRAF, 5 transcripts, reverse strand |
| 545 | // ENSG00000090266 // NDUFB2, 15 transcripts, forward strand | |
| 546 | // ENSG00000101812 // H2BFM histone, 3 transcripts, forward strand | |
| 547 | // ENSG00000123569 // H2BFWT histone, 2 transcripts, reverse strand | |
| 548 | } | |
| 549 | ||
| 550 | /** | |
| 551 | * Answers true for a feature of type 'gene' (or a sub-type of gene in the | |
| 552 | * Sequence Ontology), whose ID is the accession we are retrieving | |
| 553 | */ | |
| 554 | 9 | @Override |
| 555 | protected boolean identifiesSequence(SequenceFeature sf, String accId) | |
| 556 | { | |
| 557 | 9 | if (SequenceOntologyFactory.getInstance().isA(sf.getType(), |
| 558 | SequenceOntologyI.GENE)) | |
| 559 | { | |
| 560 | // NB features as gff use 'ID'; rest services return as 'id' | |
| 561 | 7 | String id = (String) sf.getValue("ID"); |
| 562 | 7 | if ((GENE_PREFIX + accId).equalsIgnoreCase(id)) |
| 563 | { | |
| 564 | 5 | return true; |
| 565 | } | |
| 566 | } | |
| 567 | 4 | return false; |
| 568 | } | |
| 569 | ||
| 570 | /** | |
| 571 | * Answers true unless feature type is 'gene', or 'transcript' with a parent | |
| 572 | * which is a different gene. We need the gene features to identify the range, | |
| 573 | * but it is redundant information on the gene sequence. Checking the parent | |
| 574 | * allows us to drop transcript features which belong to different | |
| 575 | * (overlapping) genes. | |
| 576 | */ | |
| 577 | 6 | @Override |
| 578 | protected boolean retainFeature(SequenceFeature sf, String accessionId) | |
| 579 | { | |
| 580 | 6 | SequenceOntologyI so = SequenceOntologyFactory.getInstance(); |
| 581 | 6 | String type = sf.getType(); |
| 582 | 6 | if (so.isA(type, SequenceOntologyI.GENE)) |
| 583 | { | |
| 584 | 1 | return false; |
| 585 | } | |
| 586 | 5 | if (isTranscript(type)) |
| 587 | { | |
| 588 | 4 | String parent = (String) sf.getValue(PARENT); |
| 589 | 4 | if (!(GENE_PREFIX + accessionId).equalsIgnoreCase(parent)) |
| 590 | { | |
| 591 | 1 | return false; |
| 592 | } | |
| 593 | } | |
| 594 | 4 | return true; |
| 595 | } | |
| 596 | ||
| 597 | /** | |
| 598 | * Answers false. This allows an optimisation - a single 'gene' feature is all | |
| 599 | * that is needed to identify the positions of the gene on the genomic | |
| 600 | * sequence. | |
| 601 | */ | |
| 602 | 2 | @Override |
| 603 | protected boolean isSpliceable() | |
| 604 | { | |
| 605 | 2 | return false; |
| 606 | } | |
| 607 | ||
| 608 | /** | |
| 609 | * Override to do nothing as Ensembl doesn't return a protein sequence for a | |
| 610 | * gene identifier | |
| 611 | */ | |
| 612 | 0 | @Override |
| 613 | protected void addProteinProduct(SequenceI querySeq) | |
| 614 | { | |
| 615 | } | |
| 616 | ||
| 617 | 0 | @Override |
| 618 | public Regex getAccessionValidator() | |
| 619 | { | |
| 620 | 0 | return ACCESSION_REGEX; |
| 621 | } | |
| 622 | ||
| 623 | /** | |
| 624 | * Returns a descriptor for suitable feature display settings with | |
| 625 | * <ul> | |
| 626 | * <li>only exon or sequence_variant features (or their subtypes in the | |
| 627 | * Sequence Ontology) visible</li> | |
| 628 | * <li>variant features coloured red</li> | |
| 629 | * <li>exon features coloured by label (exon name)</li> | |
| 630 | * <li>variants displayed above (on top of) exons</li> | |
| 631 | * </ul> | |
| 632 | */ | |
| 633 | 1 | @Override |
| 634 | public FeatureSettingsModelI getFeatureColourScheme() | |
| 635 | { | |
| 636 | 1 | return new FeatureSettingsAdapter() |
| 637 | { | |
| 638 | SequenceOntologyI so = SequenceOntologyFactory.getInstance(); | |
| 639 | ||
| 640 | 5 | @Override |
| 641 | public boolean isFeatureDisplayed(String type) | |
| 642 | { | |
| 643 | 5 | return (so.isA(type, SequenceOntologyI.EXON) |
| 644 | || so.isA(type, SequenceOntologyI.SEQUENCE_VARIANT)); | |
| 645 | } | |
| 646 | ||
| 647 | 4 | @Override |
| 648 | public FeatureColourI getFeatureColour(String type) | |
| 649 | { | |
| 650 | 4 | if (so.isA(type, SequenceOntologyI.EXON)) |
| 651 | { | |
| 652 | 2 | return new FeatureColour() |
| 653 | { | |
| 654 | 2 | @Override |
| 655 | public boolean isColourByLabel() | |
| 656 | { | |
| 657 | 2 | return true; |
| 658 | } | |
| 659 | }; | |
| 660 | } | |
| 661 | 2 | if (so.isA(type, SequenceOntologyI.SEQUENCE_VARIANT)) |
| 662 | { | |
| 663 | 2 | return new FeatureColour() |
| 664 | { | |
| 665 | ||
| 666 | 2 | @Override |
| 667 | public Color getColour() | |
| 668 | { | |
| 669 | 2 | return Color.RED; |
| 670 | } | |
| 671 | }; | |
| 672 | } | |
| 673 | 0 | return null; |
| 674 | } | |
| 675 | ||
| 676 | /** | |
| 677 | * order to render sequence_variant after exon after the rest | |
| 678 | */ | |
| 679 | 4 | @Override |
| 680 | public int compare(String feature1, String feature2) | |
| 681 | { | |
| 682 | 4 | if (so.isA(feature1, SequenceOntologyI.SEQUENCE_VARIANT)) |
| 683 | { | |
| 684 | 2 | return +1; |
| 685 | } | |
| 686 | 2 | if (so.isA(feature2, SequenceOntologyI.SEQUENCE_VARIANT)) |
| 687 | { | |
| 688 | 2 | return -1; |
| 689 | } | |
| 690 | 0 | if (so.isA(feature1, SequenceOntologyI.EXON)) |
| 691 | { | |
| 692 | 0 | return +1; |
| 693 | } | |
| 694 | 0 | if (so.isA(feature2, SequenceOntologyI.EXON)) |
| 695 | { | |
| 696 | 0 | return -1; |
| 697 | } | |
| 698 | 0 | return 0; |
| 699 | } | |
| 700 | }; | |
| 701 | } | |
| 702 | ||
| 703 | } |