Coverage Report
File Comparison.java
Coverage histogram
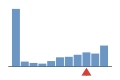
22% of files have more coverage
Code metrics
80
155
19
1
606
362
83
0.54
8.16
19
4.37
80
155
19
1
606
362
83
0.54
8.16
19
4.37
Classes
| Class | Line # | Actions | |||
|---|---|---|---|---|---|
| Comparison | 33 | 155 | 83 | 0.7952755779.5% |
Class Comparison
|
Class Comparison |
Line # 33 |
155 |
83 |
0.7952755779.5% |
|---|---|---|---|---|
| <clinit>, line 57() <clinit>, line 57() | 5757 | 5.05 | 1.01 | 1.0 1.0100% |
| compare(SequenceI,SequenceI) : float compare(SequenceI,SequenceI) : float | 8282 | 1.01 | 1.01 | 0.0 0.00% |
| compare(SequenceI,SequenceI,int,int) : float compare(SequenceI,SequenceI,int,int) : float | 100100 | 20.020 | 8.08 | 0.0 0.00% |
| PID(String,String) : float PID(String,String) : float | 162162 | 1.01 | 1.01 | 1.0 1.0100% |
| PID(String,String,int,int) : float PID(String,String,int,int) : float | 174174 | 1.01 | 1.01 | 1.0 1.0100% |
| PID(String,String,int,int,boolean,boolean) : float PID(String,String,int,int,boolean,boolean) : float | 199199 | 29.029 | 13.013 | 0.877551 0.87755187.8% |
| isGap(char) : boolean isGap(char) : boolean | 277277 | 1.01 | 1.01 | 1.0 1.0100% |
| isNucleotide(SequenceI) : boolean isNucleotide(SequenceI) : boolean | 289289 | 34.034 | 16.016 | 0.87931037 0.8793103787.9% |
| myShortSequenceNucleotideProportionCount(long,long) : boolean myShortSequenceNucleotideProportionCount(long,long) : boolean | 387387 | 3.03 | 1.01 | 1.0 1.0100% |
| isNucleotide(SequenceI[]) : boolean isNucleotide(SequenceI[]) : boolean | 433433 | 10.010 | 4.04 | 0.875 0.87587.5% |
| isNucleotide(char) : boolean isNucleotide(char) : boolean | 465465 | 1.01 | 1.01 | 1.0 1.0100% |
| isNucleotide(char,boolean) : boolean isNucleotide(char,boolean) : boolean | 473473 | 13.013 | 8.08 | 1.0 1.0100% |
| isNucleotideAmbiguity(char) : boolean isNucleotideAmbiguity(char) : boolean | 497497 | 16.016 | 14.014 | 1.0 1.0100% |
| isN(char) : boolean isN(char) : boolean | 519519 | 1.01 | 1.01 | 1.0 1.0100% |
| isX(char) : boolean isX(char) : boolean | 524524 | 1.01 | 1.01 | 1.0 1.0100% |
| isNucleotideSequence(String,boolean) : boolean isNucleotideSequence(String,boolean) : boolean | 537537 | 1.01 | 1.01 | 1.0 1.0100% |
| isNucleotideSequence(String,boolean,boolean) : boolean isNucleotideSequence(String,boolean,boolean) : boolean | 542542 | 8.08 | 6.06 | 1.0 1.0100% |
| isNucleotide(SequenceI[][]) : boolean isNucleotide(SequenceI[][]) : boolean | 569569 | 8.08 | 2.02 | 1.0 1.0100% |
| isSameResidue(char,char,boolean) : boolean isSameResidue(char,char,boolean) : boolean | 600600 | 1.01 | 2.02 | 1.0 1.0100% |
Contributing tests
This file is covered by 832 tests.
.
Contributing tests
|
0.41732284
|
jalview.util.ComparisonTest.testIsNucleotide_sequencesjalview.util.ComparisonTest.testIsNucleotide_sequences | 1PASS | ||
|
0.40944883
|
jalview.bin.CommandsTest2.structureOpeningArgsTestjalview.bin.CommandsTest2.structureOpeningArgsTest | 1PASS | ||
|
0.40944883
|
jalview.bin.CommandsTest.structureImageAnnotationsOutputTestjalview.bin.CommandsTest.structureImageAnnotationsOutputTest | 1PASS | ||
|
0.40944883
|
jalview.gui.StructureChooserTest.openStructureFileForSequenceTestjalview.gui.StructureChooserTest.openStructureFileForSequenceTest | 1PASS | ||
|
0.40944883
|
jalview.bin.CommandsTest2.structureOpeningArgsTestjalview.bin.CommandsTest2.structureOpeningArgsTest | 1PASS | ||
|
0.40944883
|
jalview.bin.CommandsTest.structureImageAnnotationsOutputTestjalview.bin.CommandsTest.structureImageAnnotationsOutputTest | 1PASS | ||
|
0.40944883
|
jalview.bin.CommandsTest.structureImageAnnotationsOutputTestjalview.bin.CommandsTest.structureImageAnnotationsOutputTest | 1PASS | ||
|
0.40944883
|
jalview.project.Jalview2xmlTests.gatherViewsHerejalview.project.Jalview2xmlTests.gatherViewsHere | 1PASS | ||
|
0.40944883
|
jalview.project.Jalview2xmlTests.testStoreAndRecoverReferenceSeqSettingsjalview.project.Jalview2xmlTests.testStoreAndRecoverReferenceSeqSettings | 1PASS | ||
|
0.40944883
|
jalview.bin.CommandsTest2.structureOpeningArgsTestjalview.bin.CommandsTest2.structureOpeningArgsTest | 1PASS | ||
|
0.40944883
|
jalview.bin.CommandsTest.structureImageAnnotationsOutputTestjalview.bin.CommandsTest.structureImageAnnotationsOutputTest | 1PASS | ||
|
0.40944883
|
jalview.bin.CommandsTest.structureImageAnnotationsOutputTestjalview.bin.CommandsTest.structureImageAnnotationsOutputTest | 1PASS | ||
|
0.40944883
|
jalview.gui.StructureChooserTest.openStructureFileForSequenceTestjalview.gui.StructureChooserTest.openStructureFileForSequenceTest | 1PASS | ||
|
0.40944883
|
jalview.project.Jalview2xmlTests.testCopyViewSettingsjalview.project.Jalview2xmlTests.testCopyViewSettings | 1PASS | ||
|
0.40944883
|
jalview.bin.CommandsTest.structureImageAnnotationsOutputTestjalview.bin.CommandsTest.structureImageAnnotationsOutputTest | 1PASS | ||
|
0.40944883
|
jalview.project.Jalview2xmlTests.viewRefPdbAnnotationjalview.project.Jalview2xmlTests.viewRefPdbAnnotation | 1PASS | ||
|
0.40944883
|
jalview.project.Jalview2xmlTests.testStoreAndRecoverExpandedviewsjalview.project.Jalview2xmlTests.testStoreAndRecoverExpandedviews | 1PASS | ||
|
0.40944883
|
jalview.bin.CommandsTest.structureImageAnnotationsOutputTestjalview.bin.CommandsTest.structureImageAnnotationsOutputTest | 1PASS | ||
|
0.40944883
|
jalview.bin.CommandsTest2.structureOpeningArgsTestjalview.bin.CommandsTest2.structureOpeningArgsTest | 1PASS | ||
|
0.40944883
|
jalview.bin.CommandsTest2.structureOpeningArgsTestjalview.bin.CommandsTest2.structureOpeningArgsTest | 1PASS | ||
|
0.40944883
|
jalview.gui.StructureChooserTest.openStructureFileForSequenceTestjalview.gui.StructureChooserTest.openStructureFileForSequenceTest | 1PASS | ||
|
0.40944883
|
jalview.bin.CommandsTest.structureImageAnnotationsOutputTestjalview.bin.CommandsTest.structureImageAnnotationsOutputTest | 1PASS | ||
|
0.40944883
|
jalview.bin.CommandsTest2.structureOpeningArgsTestjalview.bin.CommandsTest2.structureOpeningArgsTest | 1PASS | ||
|
0.4015748
|
jalview.util.ComparisonTest.testIsNucleotideSequencejalview.util.ComparisonTest.testIsNucleotideSequence | 1PASS | ||
|
0.38582677
|
jalview.bin.CommandsTest2.structureOpeningArgsTestjalview.bin.CommandsTest2.structureOpeningArgsTest | 1PASS | ||
|
0.38582677
|
jalview.bin.CommandsTest2.structureOpeningArgsTestjalview.bin.CommandsTest2.structureOpeningArgsTest | 1PASS | ||
|
0.38582677
|
jalview.bin.CommandsTest.structureImageOutputTestjalview.bin.CommandsTest.structureImageOutputTest | 1PASS | ||
|
0.38582677
|
jalview.bin.CommandsTest2.structureOpeningArgsTestjalview.bin.CommandsTest2.structureOpeningArgsTest | 1PASS | ||
|
0.38582677
|
jalview.bin.CommandsTest.structureImageOutputTestjalview.bin.CommandsTest.structureImageOutputTest | 1PASS | ||
|
0.37401575
|
jalview.gui.StructureChooserTest.openStructureFileForSequenceTestjalview.gui.StructureChooserTest.openStructureFileForSequenceTest | 1PASS | ||
|
0.37401575
|
jalview.gui.StructureChooserTest.openStructureFileForSequenceTestjalview.gui.StructureChooserTest.openStructureFileForSequenceTest | 1PASS | ||
|
0.37401575
|
jalview.renderer.seqfeatures.FeatureRendererTest.testFindFeaturesAtColumnjalview.renderer.seqfeatures.FeatureRendererTest.testFindFeaturesAtColumn | 1PASS | ||
|
0.37401575
|
jalview.analysis.AlignmentUtilsTests.testExpandContextjalview.analysis.AlignmentUtilsTests.testExpandContext | 1PASS | ||
|
0.37401575
|
jalview.project.Jalview2xmlTests.noDuplicatePdbMappingsMadejalview.project.Jalview2xmlTests.noDuplicatePdbMappingsMade | 1PASS | ||
|
0.37401575
|
jalview.gui.StructureChooserTest.openStructureFileForSequenceTestjalview.gui.StructureChooserTest.openStructureFileForSequenceTest | 1PASS | ||
|
0.37007874
|
jalview.renderer.ScaleRendererTest.testCalculateMarksjalview.renderer.ScaleRendererTest.testCalculateMarks | 1PASS | ||
|
0.37007874
|
jalview.datamodel.HiddenColumnsTest.testGetVisibleStartAndEndIndexjalview.datamodel.HiddenColumnsTest.testGetVisibleStartAndEndIndex | 1PASS | ||
|
0.37007874
|
jalview.datamodel.AlignmentTest.testAddSequencePreserveDatasetIntegrityjalview.datamodel.AlignmentTest.testAddSequencePreserveDatasetIntegrity | 1PASS | ||
|
0.37007874
|
jalview.analysis.DnaTest.testTranslateCdna_withUntranslatableCodonsjalview.analysis.DnaTest.testTranslateCdna_withUntranslatableCodons | 1PASS | ||
|
0.36614174
|
jalview.bin.CommandsTest.commandsOpenTestjalview.bin.CommandsTest.commandsOpenTest | 1PASS | ||
|
0.36614174
|
jalview.ext.jmol.JmolViewerTest.testAddStrToSingleSeqViewJMoljalview.ext.jmol.JmolViewerTest.testAddStrToSingleSeqViewJMol | 1PASS | ||
|
0.36614174
|
jalview.analysis.DnaTest.testTranslateCdna_simplejalview.analysis.DnaTest.testTranslateCdna_simple | 1PASS | ||
|
0.36614174
|
jalview.bin.CommandsTest.commandsOpenTestjalview.bin.CommandsTest.commandsOpenTest | 1PASS | ||
|
0.36614174
|
jalview.bin.CommandsTest.structureImageOutputTestjalview.bin.CommandsTest.structureImageOutputTest | 1PASS | ||
|
0.36614174
|
jalview.bin.CommandsTest.structureImageOutputTestjalview.bin.CommandsTest.structureImageOutputTest | 1PASS | ||
|
0.36220473
|
jalview.project.Jalview2xmlTests.testMergeDatasetsforManyViewsjalview.project.Jalview2xmlTests.testMergeDatasetsforManyViews | 1PASS | ||
|
0.36220473
|
jalview.analysis.DnaTest.testTranslateCdna_hiddenColumnsjalview.analysis.DnaTest.testTranslateCdna_hiddenColumns | 1PASS | ||
|
0.36220473
|
jalview.gui.PairwiseAlignmentPanelTest.testConstructor_withSelectionGroupjalview.gui.PairwiseAlignmentPanelTest.testConstructor_withSelectionGroup | 1PASS | ||
|
0.35826772
|
jalview.ext.jmol.JmolParserTest.testFileParserjalview.ext.jmol.JmolParserTest.testFileParser | 1PASS | ||
|
0.35433072
|
jalview.analysis.DnaTest.testReverseCdnajalview.analysis.DnaTest.testReverseCdna | 1PASS | ||
|
0.35433072
|
jalview.ext.jmol.JmolViewerTest.testSingleSeqViewJMoljalview.ext.jmol.JmolViewerTest.testSingleSeqViewJMol | 1PASS | ||
|
0.3503937
|
jalview.datamodel.ColumnSelectionTest.testHideColumns_withSelectionjalview.datamodel.ColumnSelectionTest.testHideColumns_withSelection | 1PASS | ||
|
0.3503937
|
jalview.bin.CommandsTest2.structureOpeningArgsTestjalview.bin.CommandsTest2.structureOpeningArgsTest | 1PASS | ||
|
0.3503937
|
jalview.io.FormatAdapterTest.testRoundTripjalview.io.FormatAdapterTest.testRoundTrip | 1PASS | ||
|
0.3503937
|
jalview.gui.QuitHandlerTest.testNoGUIUnsavedChangesjalview.gui.QuitHandlerTest.testNoGUIUnsavedChanges | 1PASS | ||
|
0.3503937
|
jalview.io.FormatAdapterTest.testRoundTripjalview.io.FormatAdapterTest.testRoundTrip | 1PASS | ||
|
0.3503937
|
jalview.gui.QuitHandlerTest.testWaitForSaveQuitjalview.gui.QuitHandlerTest.testWaitForSaveQuit | 1PASS | ||
|
0.3503937
|
jalview.datamodel.HiddenColumnsTest.testHideColumnsjalview.datamodel.HiddenColumnsTest.testHideColumns | 1PASS | ||
|
0.3503937
|
jalview.io.AnnotationFileIOTest.exampleAnnotationFileIOjalview.io.AnnotationFileIOTest.exampleAnnotationFileIO | 1PASS | ||
|
0.3503937
|
jalview.gui.DesktopTests.testInternalCopyPastejalview.gui.DesktopTests.testInternalCopyPaste | 1PASS | ||
|
0.3503937
|
jalview.gui.QuitHandlerTest.testForceQuitjalview.gui.QuitHandlerTest.testForceQuit | 1PASS | ||
|
0.3503937
|
jalview.gui.SeqPanelTest.testFindColumn_unwrappedjalview.gui.SeqPanelTest.testFindColumn_unwrapped | 1PASS | ||
|
0.3503937
|
jalview.gui.AnnotationLabelsTest2.testIdWidthNoChangesjalview.gui.AnnotationLabelsTest2.testIdWidthNoChanges | 1PASS | ||
|
0.3503937
|
jalview.project.Jalview2xmlTests.testStoreAndRecoverOverviewjalview.project.Jalview2xmlTests.testStoreAndRecoverOverview | 1PASS | ||
|
0.3503937
|
jalview.project.Jalview2xmlTests.testColourByAnnotScoresjalview.project.Jalview2xmlTests.testColourByAnnotScores | 1PASS | ||
|
0.3503937
|
jalview.io.FormatAdapterTest.testRoundTripjalview.io.FormatAdapterTest.testRoundTrip | 1PASS | ||
|
0.3503937
|
jalview.io.FormatAdapterTest.testRoundTripjalview.io.FormatAdapterTest.testRoundTrip | 1PASS | ||
|
0.3503937
|
jalview.datamodel.ColumnSelectionTest.testHideSelectedColumnsjalview.datamodel.ColumnSelectionTest.testHideSelectedColumns | 1PASS | ||
|
0.3503937
|
jalview.datamodel.ColumnSelectionTest.testInvertColumnSelectionjalview.datamodel.ColumnSelectionTest.testInvertColumnSelection | 1PASS | ||
|
0.3503937
|
jalview.bin.CommandsTest.commandsOpenTestjalview.bin.CommandsTest.commandsOpenTest | 1PASS | ||
|
0.3503937
|
jalview.bin.CommandsTest.argFilesGlobAndSubstitutionsTestjalview.bin.CommandsTest.argFilesGlobAndSubstitutionsTest | 1PASS | ||
|
0.3503937
|
jalview.gui.AnnotationLabelsTest2.testIdWidthChangesjalview.gui.AnnotationLabelsTest2.testIdWidthChanges | 1PASS | ||
|
0.3503937
|
jalview.io.FormatAdapterTest.testRoundTripjalview.io.FormatAdapterTest.testRoundTrip | 1PASS | ||
|
0.3503937
|
jalview.project.Jalview2xmlTests.testAutoShowOverviewForLegacyProjectsjalview.project.Jalview2xmlTests.testAutoShowOverviewForLegacyProjects | 1PASS | ||
|
0.3503937
|
jalview.gui.SeqPanelTest.testFindColumn_and_FindAlignmentColumn_wrappedjalview.gui.SeqPanelTest.testFindColumn_and_FindAlignmentColumn_wrapped | 1PASS | ||
|
0.3503937
|
jalview.gui.SeqPanelTest.testFindMousePosition_wrapped_scaleAbovejalview.gui.SeqPanelTest.testFindMousePosition_wrapped_scaleAbove | 1PASS | ||
|
0.3503937
|
jalview.bin.CommandsTest.commandsOpenTestjalview.bin.CommandsTest.commandsOpenTest | 1PASS | ||
|
0.3503937
|
jalview.io.FormatAdapterTest.testRoundTripjalview.io.FormatAdapterTest.testRoundTrip | 1PASS | ||
|
0.3503937
|
jalview.gui.QuitHandlerTest.testUnsavedChangesjalview.gui.QuitHandlerTest.testUnsavedChanges | 1PASS | ||
|
0.3503937
|
jalview.gui.QuitHandlerTest.testSavedProjectChangesjalview.gui.QuitHandlerTest.testSavedProjectChanges | 1PASS | ||
|
0.3503937
|
jalview.io.FormatAdapterTest.testRoundTripjalview.io.FormatAdapterTest.testRoundTrip | 1PASS | ||
|
0.3503937
|
jalview.bin.CommandsTest.commandsOpenTestjalview.bin.CommandsTest.commandsOpenTest | 1PASS | ||
|
0.3503937
|
jalview.project.Jalview2xmlTests.testPcaViewAssociationjalview.project.Jalview2xmlTests.testPcaViewAssociation | 1PASS | ||
|
0.3503937
|
jalview.io.FeaturesFileTest.testPrintGffFormat_withFiltersjalview.io.FeaturesFileTest.testPrintGffFormat_withFilters | 1PASS | ||
|
0.3503937
|
jalview.gui.SeqPanelTest.testFindMousePosition_wrapped_noAnnotationsjalview.gui.SeqPanelTest.testFindMousePosition_wrapped_noAnnotations | 1PASS | ||
|
0.3503937
|
jalview.io.FeaturesFileTest.testPrintJalviewFormat_withFiltersjalview.io.FeaturesFileTest.testPrintJalviewFormat_withFilters | 1PASS | ||
|
0.3503937
|
jalview.bin.CommandsTest.argFilesGlobAndSubstitutionsTestjalview.bin.CommandsTest.argFilesGlobAndSubstitutionsTest | 1PASS | ||
|
0.3503937
|
jalview.bin.CommandsTest.commandsOpenTestjalview.bin.CommandsTest.commandsOpenTest | 1PASS | ||
|
0.3503937
|
jalview.schemes.ColourSchemesTest.testRegisterColourSchemejalview.schemes.ColourSchemesTest.testRegisterColourScheme | 1PASS | ||
|
0.3503937
|
jalview.io.FormatAdapterTest.testRoundTripjalview.io.FormatAdapterTest.testRoundTrip | 1PASS | ||
|
0.3503937
|
jalview.project.Jalview2xmlTests.testStoreAndRecoverGroupRepSeqsjalview.project.Jalview2xmlTests.testStoreAndRecoverGroupRepSeqs | 1PASS | ||
|
0.3503937
|
jalview.viewmodel.ViewportRangesTest.testScrollToWrappedVisiblejalview.viewmodel.ViewportRangesTest.testScrollToWrappedVisible | 1PASS | ||
|
0.3503937
|
jalview.datamodel.SequenceTest.testLocateVisibleStartofSequencejalview.datamodel.SequenceTest.testLocateVisibleStartofSequence | 1PASS | ||
|
0.3503937
|
jalview.io.FormatAdapterTest.testRoundTripjalview.io.FormatAdapterTest.testRoundTrip | 1PASS | ||
|
0.3503937
|
jalview.gui.QuitHandlerTest.testSavedAlignmentChangesjalview.gui.QuitHandlerTest.testSavedAlignmentChanges | 1PASS | ||
|
0.3503937
|
jalview.gui.SeqPanelTest.testFindMousePosition_wrapped_annotationsjalview.gui.SeqPanelTest.testFindMousePosition_wrapped_annotations | 1PASS | ||
|
0.3503937
|
jalview.io.FeaturesFileTest.testParse_jalviewFeaturesOnlyjalview.io.FeaturesFileTest.testParse_jalviewFeaturesOnly | 1PASS | ||
|
0.3503937
|
jalview.project.Jalview2xmlTests.testTCoffeeScoresjalview.project.Jalview2xmlTests.testTCoffeeScores | 1PASS | ||
|
0.3503937
|
jalview.io.FeaturesFileTest.testParse_mixedJalviewGffjalview.io.FeaturesFileTest.testParse_mixedJalviewGff | 1PASS | ||
|
0.3503937
|
jalview.io.WindowsFileLoadAndSaveTest.loadAndSaveAlignmentjalview.io.WindowsFileLoadAndSaveTest.loadAndSaveAlignment | 1PASS | ||
|
0.3503937
|
jalview.io.FeaturesFileTest.testPrintJalviewFormatjalview.io.FeaturesFileTest.testPrintJalviewFormat | 1PASS | ||
|
0.3503937
|
jalview.gui.AnnotationLabelsTest2.testIdWidthNoChangesjalview.gui.AnnotationLabelsTest2.testIdWidthNoChanges | 1PASS | ||
|
0.3503937
|
jalview.bin.CommandsTest.commandsOpenTestjalview.bin.CommandsTest.commandsOpenTest | 1PASS | ||
|
0.3503937
|
jalview.gui.AnnotationLabelsTest2.testIdWidthChangesjalview.gui.AnnotationLabelsTest2.testIdWidthChanges | 1PASS | ||
|
0.3503937
|
jalview.io.FormatAdapterTest.testRoundTripjalview.io.FormatAdapterTest.testRoundTrip | 1PASS | ||
|
0.3503937
|
jalview.project.Jalview2xmlTests.testStoreAndRecoverColourThresholdsjalview.project.Jalview2xmlTests.testStoreAndRecoverColourThresholds | 1PASS | ||
|
0.3503937
|
jalview.project.Jalview2xmlTests.testStoreAndRestoreIDwidthAndAnnotationHeightjalview.project.Jalview2xmlTests.testStoreAndRestoreIDwidthAndAnnotationHeight | 1PASS | ||
|
0.3503937
|
jalview.gui.AlignViewportTest.testSetGetHasSearchResultsjalview.gui.AlignViewportTest.testSetGetHasSearchResults | 1PASS | ||
|
0.3503937
|
jalview.gui.AlignViewportTest.testSetSelectionGroupjalview.gui.AlignViewportTest.testSetSelectionGroup | 1PASS | ||
|
0.3503937
|
jalview.gui.AlignViewportTest.testUpdateConservation_qualityOnlyjalview.gui.AlignViewportTest.testUpdateConservation_qualityOnly | 1PASS | ||
|
0.3503937
|
jalview.bin.CommandsTest.commandsOpenTestjalview.bin.CommandsTest.commandsOpenTest | 1PASS | ||
|
0.3503937
|
jalview.io.FormatAdapterTest.testRoundTripjalview.io.FormatAdapterTest.testRoundTrip | 1PASS | ||
|
0.3503937
|
jalview.io.FeaturesFileTest.testParse_pureGff3jalview.io.FeaturesFileTest.testParse_pureGff3 | 1PASS | ||
|
0.3503937
|
jalview.gui.QuitHandlerTest.testInstantQuitjalview.gui.QuitHandlerTest.testInstantQuit | 1PASS | ||
|
0.3503937
|
jalview.io.FeaturesFileTest.testParsejalview.io.FeaturesFileTest.testParse | 1PASS | ||
|
0.3503937
|
jalview.gui.AlignViewportTest.testSetGlobalColourSchemejalview.gui.AlignViewportTest.testSetGlobalColourScheme | 1PASS | ||
|
0.3503937
|
jalview.bin.CommandsTest.commandsOpenTestjalview.bin.CommandsTest.commandsOpenTest | 1PASS | ||
|
0.3503937
|
jalview.gui.AlignViewportTest.testShowOrDontShowOccupancyjalview.gui.AlignViewportTest.testShowOrDontShowOccupancy | 1PASS | ||
|
0.3503937
|
jalview.project.Jalview2xmlTests.testMergeDatasetsforViewsjalview.project.Jalview2xmlTests.testMergeDatasetsforViews | 1PASS | ||
|
0.3503937
|
jalview.gui.AlignmentPanelTest.testSetOverviewTitle_automaticOverviewjalview.gui.AlignmentPanelTest.testSetOverviewTitle_automaticOverview | 1PASS | ||
|
0.3503937
|
jalview.io.JalviewExportPropertiesTests.testImportExportPeriodGapsjalview.io.JalviewExportPropertiesTests.testImportExportPeriodGaps | 1PASS | ||
|
0.3503937
|
jalview.io.FeaturesFileTest.testPrintGffFormatjalview.io.FeaturesFileTest.testPrintGffFormat | 1PASS | ||
|
0.3464567
|
jalview.analysis.DnaTest.testTranslateCdna_withUntranslatableCodonsAndHiddenColumnsjalview.analysis.DnaTest.testTranslateCdna_withUntranslatableCodonsAndHiddenColumns | 1PASS | ||
|
0.3464567
|
jalview.viewmodel.ViewportRangesTest.testSetViewportLocationjalview.viewmodel.ViewportRangesTest.testSetViewportLocation | 1PASS | ||
|
0.34251967
|
jalview.io.CrossRef2xmlTests.openCrossrefsForEnsemblTwicejalview.io.CrossRef2xmlTests.openCrossrefsForEnsemblTwice | 1PASS | ||
|
0.34251967
|
jalview.structures.models.AAStructureBindingModelTest.testBuildColoursMapjalview.structures.models.AAStructureBindingModelTest.testBuildColoursMap | 1PASS | ||
|
0.34251967
|
jalview.viewmodel.ViewportRangesTest.testScrollUp_wrappedjalview.viewmodel.ViewportRangesTest.testScrollUp_wrapped | 1PASS | ||
|
0.33858266
|
jalview.io.StockholmFileTest.pfamFileDataExtractionjalview.io.StockholmFileTest.pfamFileDataExtraction | 1PASS | ||
|
0.33858266
|
jalview.io.StockholmFileTest.pfamFileIOjalview.io.StockholmFileTest.pfamFileIO | 1PASS | ||
|
0.33464566
|
jalview.analysis.AverageDistanceEngineTest.testUPGMAEnginejalview.analysis.AverageDistanceEngineTest.testUPGMAEngine | 1PASS | ||
|
0.33464566
|
jalview.gui.PairwiseAlignmentPanelTest.testConstructor_noSelectionGroupjalview.gui.PairwiseAlignmentPanelTest.testConstructor_noSelectionGroup | 1PASS | ||
|
0.33464566
|
jalview.io.JSONFileTest.testBioJSONRoundTripWithColourSchemeNonejalview.io.JSONFileTest.testBioJSONRoundTripWithColourSchemeNone | 1PASS | ||
|
0.33464566
|
jalview.datamodel.SeqCigarTest.testSomethingjalview.datamodel.SeqCigarTest.testSomething | 1PASS | ||
|
0.33464566
|
jalview.io.JSONFileTest.testGrpParsed_colourNonejalview.io.JSONFileTest.testGrpParsed_colourNone | 1PASS | ||
|
0.33464566
|
jalview.renderer.seqfeatures.FeatureRendererTest.testFindComplementFeaturesAtResiduejalview.renderer.seqfeatures.FeatureRendererTest.testFindComplementFeaturesAtResidue | 1PASS | ||
|
0.33070865
|
jalview.analysis.CrossRefTest.testFindXrefSequences_fromDbRefMapjalview.analysis.CrossRefTest.testFindXrefSequences_fromDbRefMap | 1PASS | ||
|
0.33070865
|
jalview.gui.ScalePanelTest.testSelectColumns_withHiddenjalview.gui.ScalePanelTest.testSelectColumns_withHidden | 1PASS | ||
|
0.33070865
|
jalview.datamodel.AlignmentTest.testPropagateInsertionsjalview.datamodel.AlignmentTest.testPropagateInsertions | 1PASS | ||
|
0.32677165
|
jalview.io.gff.GffTests.testResolveExonerateGffjalview.io.gff.GffTests.testResolveExonerateGff | 1PASS | ||
|
0.32677165
|
jalview.datamodel.AlignmentTest.testDeleteSequenceBySeqjalview.datamodel.AlignmentTest.testDeleteSequenceBySeq | 1PASS | ||
|
0.32677165
|
jalview.gui.StructureChooserTest.populateFilterComboBoxTestjalview.gui.StructureChooserTest.populateFilterComboBoxTest | 1PASS | ||
|
0.32677165
|
jalview.datamodel.AlignmentTest.testDeleteSequenceByIndexjalview.datamodel.AlignmentTest.testDeleteSequenceByIndex | 1PASS | ||
|
0.32677165
|
jalview.gui.structurechooser.StructureChooserQuerySourceTest.buildPDBQueryTestjalview.gui.structurechooser.StructureChooserQuerySourceTest.buildPDBQueryTest | 1PASS | ||
|
0.32677165
|
jalview.analysis.CrossRefTest.testFindXrefSequences_indirectDbrefToNucleotidejalview.analysis.CrossRefTest.testFindXrefSequences_indirectDbrefToNucleotide | 1PASS | ||
|
0.32677165
|
jalview.schemes.ResidueColourSchemeTest.testIsApplicableTojalview.schemes.ResidueColourSchemeTest.testIsApplicableTo | 1PASS | ||
|
0.32677165
|
jalview.analysis.CrossRefTest.testSearchDatasetjalview.analysis.CrossRefTest.testSearchDataset | 1PASS | ||
|
0.32677165
|
jalview.gui.AssociatePDBFileTest.testAssociatePDBFilejalview.gui.AssociatePDBFileTest.testAssociatePDBFile | 1PASS | ||
|
0.32677165
|
jalview.datamodel.AlignmentTest.testDeleteHiddenSequencejalview.datamodel.AlignmentTest.testDeleteHiddenSequence | 1PASS | ||
|
0.32283464
|
jalview.io.FeaturesFileTest.simpleGff3FileLoaderjalview.io.FeaturesFileTest.simpleGff3FileLoader | 1PASS | ||
|
0.32283464
|
jalview.analysis.CrossRefTest.testFindXrefSequences_indirectDbrefToProteinjalview.analysis.CrossRefTest.testFindXrefSequences_indirectDbrefToProtein | 1PASS | ||
|
0.32283464
|
jalview.analysis.AlignmentUtilsTests.testAlignProteinAsDna_incompleteStartCodonjalview.analysis.AlignmentUtilsTests.testAlignProteinAsDna_incompleteStartCodon | 1PASS | ||
|
0.32283464
|
jalview.io.FeaturesFileTest.readGff3Filejalview.io.FeaturesFileTest.readGff3File | 1PASS | ||
|
0.31889763
|
mc_view.PDBfileTest.testParsemc_view.PDBfileTest.testParse | 1PASS | ||
|
0.31889763
|
mc_view.PDBfileTest.testParse_withJmol_noAnnotationsmc_view.PDBfileTest.testParse_withJmol_noAnnotations | 1PASS | ||
|
0.31889763
|
jalview.io.gff.ExonerateHelperTest.testAddExonerateGffToAlignmentjalview.io.gff.ExonerateHelperTest.testAddExonerateGffToAlignment | 1PASS | ||
|
0.31889763
|
jalview.datamodel.AlignmentTest.testPropagateInsertionsOverlapjalview.datamodel.AlignmentTest.testPropagateInsertionsOverlap | 1PASS | ||
|
0.31889763
|
jalview.viewmodel.ViewportRangesTest.testPageUpDownWrappedjalview.viewmodel.ViewportRangesTest.testPageUpDownWrapped | 1PASS | ||
|
0.31889763
|
jalview.datamodel.AlignmentTest.testAlignAs_cdnaAsProteinjalview.datamodel.AlignmentTest.testAlignAs_cdnaAsProtein | 1PASS | ||
|
0.31889763
|
jalview.project.Jalview2xmlTests.testStoreAndRecoverPDBEntryjalview.project.Jalview2xmlTests.testStoreAndRecoverPDBEntry | 1PASS | ||
|
0.31889763
|
jalview.io.AnnotatedPDBFileInputTest.testJalviewProjectRelocationAnnotationjalview.io.AnnotatedPDBFileInputTest.testJalviewProjectRelocationAnnotation | 1PASS | ||
|
0.31889763
|
jalview.datamodel.AlignmentTest.testAlignAs_proteinAsCdnajalview.datamodel.AlignmentTest.testAlignAs_proteinAsCdna | 1PASS | ||
|
0.31889763
|
jalview.viewmodel.ViewportRangesTest.testGetWrappedMaxScrolljalview.viewmodel.ViewportRangesTest.testGetWrappedMaxScroll | 1PASS | ||
|
0.31889763
|
jalview.structures.models.AAStructureBindingModelTest.testImportPDBPreservesChainMappingsjalview.structures.models.AAStructureBindingModelTest.testImportPDBPreservesChainMappings | 1PASS | ||
|
0.31889763
|
jalview.datamodel.AlignmentTest.testFindGroupjalview.datamodel.AlignmentTest.testFindGroup | 1PASS | ||
|
0.31889763
|
jalview.project.Jalview2xmlTests.testStoreAndRecoverNoOverviewjalview.project.Jalview2xmlTests.testStoreAndRecoverNoOverview | 1PASS | ||
|
0.31889763
|
jalview.renderer.OverviewResColourFinderTest.testGetResidueBoxColour_nonejalview.renderer.OverviewResColourFinderTest.testGetResidueBoxColour_none | 1PASS | ||
|
0.31889763
|
mc_view.PDBfileTest.testParse_withAnnotations_noSSmc_view.PDBfileTest.testParse_withAnnotations_noSS | 1PASS | ||
|
0.31889763
|
jalview.datamodel.AlignmentTest.testAppendjalview.datamodel.AlignmentTest.testAppend | 1PASS | ||
|
0.31889763
|
jalview.gui.FeatureSettingsTest.testSaveLoadjalview.gui.FeatureSettingsTest.testSaveLoad | 1PASS | ||
|
0.31889763
|
jalview.ext.jmol.JmolParserTest.testAlignmentLoaderjalview.ext.jmol.JmolParserTest.testAlignmentLoader | 1PASS | ||
|
0.31889763
|
jalview.project.Jalview2xmlTests.testSaveLoadFeatureColoursAndFiltersjalview.project.Jalview2xmlTests.testSaveLoadFeatureColoursAndFilters | 1PASS | ||
|
0.31889763
|
mc_view.PDBfileTest.testParse_withJmolAddAlignmentAnnotationsmc_view.PDBfileTest.testParse_withJmolAddAlignmentAnnotations | 1PASS | ||
|
0.31889763
|
jalview.renderer.ResidueColourFinderTest.testGetResidueColour_nonejalview.renderer.ResidueColourFinderTest.testGetResidueColour_none | 1PASS | ||
|
0.31889763
|
jalview.viewmodel.ViewportRangesTest.testGetWrappedScrollPositionjalview.viewmodel.ViewportRangesTest.testGetWrappedScrollPosition | 1PASS | ||
|
0.31889763
|
jalview.analysis.AlignmentUtilsTests.testExpandContext_annotationjalview.analysis.AlignmentUtilsTests.testExpandContext_annotation | 1PASS | ||
|
0.31889763
|
jalview.project.Jalview2xmlTests.testPAEsaveRestorejalview.project.Jalview2xmlTests.testPAEsaveRestore | 1PASS | ||
|
0.31889763
|
jalview.analysis.AlignmentSorterTest.testSortByFeature_scorejalview.analysis.AlignmentSorterTest.testSortByFeature_score | 1PASS | ||
|
0.31889763
|
jalview.datamodel.SequenceGroupTest.testContainsjalview.datamodel.SequenceGroupTest.testContains | 1PASS | ||
|
0.31496063
|
jalview.bin.CommandsTest.allLinkedIdsTestjalview.bin.CommandsTest.allLinkedIdsTest | 1PASS | ||
|
0.31496063
|
jalview.gui.AlignFrameTest.testHideFeatureColumnsjalview.gui.AlignFrameTest.testHideFeatureColumns | 1PASS | ||
|
0.31496063
|
jalview.renderer.OverviewResColourFinderTest.testGetResidueBoxColour_zappojalview.renderer.OverviewResColourFinderTest.testGetResidueBoxColour_zappo | 1PASS | ||
|
0.31496063
|
jalview.bin.CommandsTest.allLinkedIdsTestjalview.bin.CommandsTest.allLinkedIdsTest | 1PASS | ||
|
0.31496063
|
jalview.bin.CommandsTest.argFilesGlobAndSubstitutionsTestjalview.bin.CommandsTest.argFilesGlobAndSubstitutionsTest | 1PASS | ||
|
0.31496063
|
jalview.commands.EditCommandTest.testReplace_withGapsjalview.commands.EditCommandTest.testReplace_withGaps | 1PASS | ||
|
0.31496063
|
jalview.bin.CommandsTest.allLinkedIdsTestjalview.bin.CommandsTest.allLinkedIdsTest | 1PASS | ||
|
0.31496063
|
jalview.bin.CommandsTest.allLinkedIdsTestjalview.bin.CommandsTest.allLinkedIdsTest | 1PASS | ||
|
0.31496063
|
jalview.bin.CommandsTest.allLinkedIdsTestjalview.bin.CommandsTest.allLinkedIdsTest | 1PASS | ||
|
0.31496063
|
jalview.bin.CommandsTest.allLinkedIdsTestjalview.bin.CommandsTest.allLinkedIdsTest | 1PASS | ||
|
0.31496063
|
jalview.bin.CommandsTest.allLinkedIdsTestjalview.bin.CommandsTest.allLinkedIdsTest | 1PASS | ||
|
0.31496063
|
jalview.structure.StructureSelectionManagerTest.testSetMapping_seqFeaturesjalview.structure.StructureSelectionManagerTest.testSetMapping_seqFeatures | 1PASS | ||
|
0.31496063
|
jalview.renderer.ResidueColourFinderTest.testGetResidueColour_userdefjalview.renderer.ResidueColourFinderTest.testGetResidueColour_userdef | 1PASS | ||
|
0.31496063
|
jalview.analysis.AnnotationSorterTest.testSort_timingPresortedjalview.analysis.AnnotationSorterTest.testSort_timingPresorted | 1PASS | ||
|
0.31496063
|
jalview.bin.CommandsTest.commandsOpenTestjalview.bin.CommandsTest.commandsOpenTest | 1PASS | ||
|
0.31496063
|
jalview.analysis.AnnotationSorterTest.testSort_timingSemisortedjalview.analysis.AnnotationSorterTest.testSort_timingSemisorted | 1PASS | ||
|
0.31496063
|
jalview.analysis.AnnotationSorterTest.testSort_timingUnsortedjalview.analysis.AnnotationSorterTest.testSort_timingUnsorted | 1PASS | ||
|
0.31496063
|
jalview.renderer.OverviewResColourFinderTest.testGetResidueBoxColour_userdefjalview.renderer.OverviewResColourFinderTest.testGetResidueBoxColour_userdef | 1PASS | ||
|
0.31496063
|
jalview.bin.CommandsTest.allLinkedIdsTestjalview.bin.CommandsTest.allLinkedIdsTest | 1PASS | ||
|
0.31496063
|
jalview.renderer.ResidueColourFinderTest.testGetResidueColour_zappojalview.renderer.ResidueColourFinderTest.testGetResidueColour_zappo | 1PASS | ||
|
0.31496063
|
jalview.bin.CommandsTest.allLinkedIdsTestjalview.bin.CommandsTest.allLinkedIdsTest | 1PASS | ||
|
0.31496063
|
jalview.bin.CommandsTest.argFilesGlobAndSubstitutionsTestjalview.bin.CommandsTest.argFilesGlobAndSubstitutionsTest | 1PASS | ||
|
0.31496063
|
jalview.analysis.AlignmentUtilsTests.testAlignProteinAsDnajalview.analysis.AlignmentUtilsTests.testAlignProteinAsDna | 1PASS | ||
|
0.31496063
|
jalview.bin.CommandsTest.argFilesGlobAndSubstitutionsTestjalview.bin.CommandsTest.argFilesGlobAndSubstitutionsTest | 1PASS | ||
|
0.31496063
|
jalview.bin.CommandsTest.allLinkedIdsTestjalview.bin.CommandsTest.allLinkedIdsTest | 1PASS | ||
|
0.31496063
|
jalview.bin.CommandsTest.allLinkedIdsTestjalview.bin.CommandsTest.allLinkedIdsTest | 1PASS | ||
|
0.31102362
|
jalview.gui.ScalePanelTest.testBuildPopupMenujalview.gui.ScalePanelTest.testBuildPopupMenu | 1PASS | ||
|
0.31102362
|
jalview.datamodel.AlignmentTest.testFindOrCreateForNullCalcIdjalview.datamodel.AlignmentTest.testFindOrCreateForNullCalcId | 1PASS | ||
|
0.31102362
|
jalview.util.MappingUtilsTest.testMapColumnSelection_hiddenColumnsjalview.util.MappingUtilsTest.testMapColumnSelection_hiddenColumns | 1PASS | ||
|
0.31102362
|
jalview.util.MappingUtilsTest.testMapColumnSelection_nulljalview.util.MappingUtilsTest.testMapColumnSelection_null | 1PASS | ||
|
0.31102362
|
jalview.schemes.ColourSchemesTest.testGetColourSchemejalview.schemes.ColourSchemesTest.testGetColourScheme | 1PASS | ||
|
0.31102362
|
jalview.datamodel.AlignmentTest.testAlignAs_cdnaAsProtein_singleSequencejalview.datamodel.AlignmentTest.testAlignAs_cdnaAsProtein_singleSequence | 1PASS | ||
|
0.31102362
|
jalview.util.MappingUtilsTest.testMapColumnSelection_proteinToDnajalview.util.MappingUtilsTest.testMapColumnSelection_proteinToDna | 1PASS | ||
|
0.31102362
|
jalview.util.MappingUtilsTest.testMapColumnSelection_dnaToProteinjalview.util.MappingUtilsTest.testMapColumnSelection_dnaToProtein | 1PASS | ||
|
0.30708662
|
jalview.gui.ScalePanelTest.testPreventNegativeStartColumnjalview.gui.ScalePanelTest.testPreventNegativeStartColumn | 1PASS | ||
|
0.30708662
|
jalview.util.MappingUtilsTest.testMapSequenceGroup_sharedDatasetjalview.util.MappingUtilsTest.testMapSequenceGroup_sharedDataset | 1PASS | ||
|
0.30708662
|
jalview.datamodel.AlignmentTest.testGetWidthjalview.datamodel.AlignmentTest.testGetWidth | 1PASS | ||
|
0.30708662
|
jalview.datamodel.AlignmentAnnotationTests.testLiftOverjalview.datamodel.AlignmentAnnotationTests.testLiftOver | 1PASS | ||
|
0.30708662
|
jalview.analysis.AlignmentUtilsTests.testMapProteinAlignmentToCdna_prioritiseXrefsjalview.analysis.AlignmentUtilsTests.testMapProteinAlignmentToCdna_prioritiseXrefs | 1PASS | ||
|
0.30708662
|
jalview.util.MappingUtilsTest.testMapSequenceGroup_regionjalview.util.MappingUtilsTest.testMapSequenceGroup_region | 1PASS | ||
|
0.30708662
|
jalview.viewmodel.OverviewDimensionsShowHiddenTest.testConstructorjalview.viewmodel.OverviewDimensionsShowHiddenTest.testConstructor | 1PASS | ||
|
0.30708662
|
jalview.datamodel.AlignmentTest.testGetVisibleWidthjalview.datamodel.AlignmentTest.testGetVisibleWidth | 1PASS | ||
|
0.30708662
|
jalview.ext.jmol.JmolCommandsTest.testGetColourBySequenceCommands_hiddenColumnsjalview.ext.jmol.JmolCommandsTest.testGetColourBySequenceCommands_hiddenColumns | 1PASS | ||
|
0.30708662
|
jalview.analysis.AlignmentUtilsTests.testMapProteinAlignmentToCdna_noXrefsjalview.analysis.AlignmentUtilsTests.testMapProteinAlignmentToCdna_noXrefs | 1PASS | ||
|
0.30708662
|
jalview.analysis.AlignmentUtilsTests.testMapProteinAlignmentToCdna_withXrefsjalview.analysis.AlignmentUtilsTests.testMapProteinAlignmentToCdna_withXrefs | 1PASS | ||
|
0.30708662
|
jalview.datamodel.CigarArrayTest.testConstructorjalview.datamodel.CigarArrayTest.testConstructor | 1PASS | ||
|
0.30708662
|
jalview.schemes.PIDColourSchemeTest.testFindColour_ignoreGapsjalview.schemes.PIDColourSchemeTest.testFindColour_ignoreGaps | 1PASS | ||
|
0.30708662
|
jalview.renderer.seqfeatures.FeatureRendererTest.testIsVisiblejalview.renderer.seqfeatures.FeatureRendererTest.testIsVisible | 1PASS | ||
|
0.30708662
|
jalview.datamodel.AlignmentTest.testEqualsjalview.datamodel.AlignmentTest.testEquals | 1PASS | ||
|
0.30708662
|
jalview.analysis.DnaTest.testTranslateCdna_sequenceOrderIndependentjalview.analysis.DnaTest.testTranslateCdna_sequenceOrderIndependent | 1PASS | ||
|
0.30708662
|
jalview.datamodel.AlignmentTest.testPadGapsjalview.datamodel.AlignmentTest.testPadGaps | 1PASS | ||
|
0.30708662
|
jalview.analysis.AlignmentUtilsTests.testMapProteinAlignmentToCdna_withStartAndStopCodonsjalview.analysis.AlignmentUtilsTests.testMapProteinAlignmentToCdna_withStartAndStopCodons | 1PASS | ||
|
0.3031496
|
jalview.renderer.seqfeatures.FeatureRendererTest.testFindAllFeaturesjalview.renderer.seqfeatures.FeatureRendererTest.testFindAllFeatures | 1PASS | ||
|
0.3031496
|
jalview.schemes.ResidueColourSchemeTest.testIsApplicableTo_dynamicColourSchemejalview.schemes.ResidueColourSchemeTest.testIsApplicableTo_dynamicColourScheme | 1PASS | ||
|
0.3031496
|
jalview.commands.EditCommandTest.testLeftRight_Justify_and_preserves_gapsjalview.commands.EditCommandTest.testLeftRight_Justify_and_preserves_gaps | 1PASS | ||
|
0.3031496
|
jalview.analysis.AlignmentUtilsTests.testIsMappablejalview.analysis.AlignmentUtilsTests.testIsMappable | 1PASS | ||
|
0.3031496
|
jalview.commands.EditCommandTest.testCut_withFeatures_exhaustivejalview.commands.EditCommandTest.testCut_withFeatures_exhaustive | 1PASS | ||
|
0.3031496
|
jalview.analysis.scoremodels.FeatureDistanceModelTest.testFindDistancesjalview.analysis.scoremodels.FeatureDistanceModelTest.testFindDistances | 1PASS | ||
|
0.3031496
|
jalview.gui.SeqPanelTest.testAmbiguousAminoAcidGetsStatusMessagejalview.gui.SeqPanelTest.testAmbiguousAminoAcidGetsStatusMessage | 1PASS | ||
|
0.3031496
|
jalview.schemes.ResidueColourSchemeTest.testGetNamejalview.schemes.ResidueColourSchemeTest.testGetName | 1PASS | ||
|
0.3031496
|
jalview.renderer.seqfeatures.FeatureRendererTest.testFilterFeaturesForDisplayjalview.renderer.seqfeatures.FeatureRendererTest.testFilterFeaturesForDisplay | 1PASS | ||
|
0.3031496
|
jalview.schemes.ClustalxColourSchemeTest.testFindColourjalview.schemes.ClustalxColourSchemeTest.testFindColour | 1PASS | ||
|
0.2992126
|
jalview.project.Jalview2xmlTests.testStoreAndRecoverGeneLocusjalview.project.Jalview2xmlTests.testStoreAndRecoverGeneLocus | 1PASS | ||
|
0.2992126
|
jalview.util.MappingUtilsTest.testMapSequenceGroup_columnsjalview.util.MappingUtilsTest.testMapSequenceGroup_columns | 1PASS | ||
|
0.2992126
|
jalview.analysis.SeqsetUtilsTest.testSeqFeatureAdditionjalview.analysis.SeqsetUtilsTest.testSeqFeatureAddition | 1PASS | ||
|
0.2992126
|
jalview.datamodel.AlignmentTest.testVerifyAlignmentDatasetRefsjalview.datamodel.AlignmentTest.testVerifyAlignmentDatasetRefs | 1PASS | ||
|
0.2992126
|
jalview.bin.CommandsTest.commandsOpenTestjalview.bin.CommandsTest.commandsOpenTest | 1PASS | ||
|
0.2992126
|
jalview.datamodel.PAEContactMatrixTest.testSeqAssociatedPAEMatrixjalview.datamodel.PAEContactMatrixTest.testSeqAssociatedPAEMatrix | 1PASS | ||
|
0.2992126
|
jalview.datamodel.SequenceTest.testIsProteinWithXorNAmbiguityCodesjalview.datamodel.SequenceTest.testIsProteinWithXorNAmbiguityCodes | 1PASS | ||
|
0.2992126
|
jalview.io.StockholmFileTest.dbrefOutputjalview.io.StockholmFileTest.dbrefOutput | 1PASS | ||
|
0.2992126
|
jalview.io.StockholmFileTest.descriptionLineOutputjalview.io.StockholmFileTest.descriptionLineOutput | 1PASS | ||
|
0.2992126
|
jalview.gui.SeqPanelTest.testSetStatusReturnsNearestResiduePositionjalview.gui.SeqPanelTest.testSetStatusReturnsNearestResiduePosition | 1PASS | ||
|
0.2992126
|
jalview.viewmodel.OverviewDimensionsHideHiddenTest.testConstructorjalview.viewmodel.OverviewDimensionsHideHiddenTest.testConstructor | 1PASS | ||
|
0.2992126
|
jalview.util.MappingUtilsTest.testMapEditCommandjalview.util.MappingUtilsTest.testMapEditCommand | 1PASS | ||
|
0.2952756
|
jalview.controller.AlignViewControllerTest.testFindColumnsWithFeaturejalview.controller.AlignViewControllerTest.testFindColumnsWithFeature | 1PASS | ||
|
0.2952756
|
jalview.gui.ColourMenuHelperTest.testAddMenuItems_forAlignFramejalview.gui.ColourMenuHelperTest.testAddMenuItems_forAlignFrame | 1PASS | ||
|
0.2952756
|
jalview.analysis.CrossRefTest.testFindXrefSourcesForSequence_proteinToDnajalview.analysis.CrossRefTest.testFindXrefSourcesForSequence_proteinToDna | 1PASS | ||
|
0.2952756
|
jalview.gui.ColourMenuHelperTest.testAddMenuItems_peptidejalview.gui.ColourMenuHelperTest.testAddMenuItems_peptide | 1PASS | ||
|
0.2952756
|
jalview.gui.ColourMenuHelperTest.testAddMenuItems_simpleOnlyjalview.gui.ColourMenuHelperTest.testAddMenuItems_simpleOnly | 1PASS | ||
|
0.2952756
|
jalview.io.AnnotationFileIOTest.testAnnotateAlignmentViewjalview.io.AnnotationFileIOTest.testAnnotateAlignmentView | 1PASS | ||
|
0.2913386
|
jalview.io.BackupFilesTest.backupsEnabledNoRollMaxTestjalview.io.BackupFilesTest.backupsEnabledNoRollMaxTest | 1PASS | ||
|
0.2913386
|
jalview.analysis.scoremodels.FeatureDistanceModelTest.testFeatureScoreModeljalview.analysis.scoremodels.FeatureDistanceModelTest.testFeatureScoreModel | 1PASS | ||
|
0.2913386
|
jalview.ws.dbsources.EBIAlphaFoldTest.checkImportPAEToStructurejalview.ws.dbsources.EBIAlphaFoldTest.checkImportPAEToStructure | 1PASS | ||
|
0.2913386
|
jalview.io.BackupFilesTest.backupsEnabledSingleFileBackupTestjalview.io.BackupFilesTest.backupsEnabledSingleFileBackupTest | 1PASS | ||
|
0.2913386
|
jalview.analysis.AlignmentUtilsTests.testAddReferenceAnnotationsjalview.analysis.AlignmentUtilsTests.testAddReferenceAnnotations | 1PASS | ||
|
0.2913386
|
jalview.gui.AlignViewportTest.testGetSelectionAsNewSequences_withContactMatricesjalview.gui.AlignViewportTest.testGetSelectionAsNewSequences_withContactMatrices | 1PASS | ||
|
0.2913386
|
jalview.io.BackupFilesTest.backupsEnabledRollMaxTestjalview.io.BackupFilesTest.backupsEnabledRollMaxTest | 1PASS | ||
|
0.2913386
|
jalview.io.BackupFilesTest.noBackupsEnabledTestjalview.io.BackupFilesTest.noBackupsEnabledTest | 1PASS | ||
|
0.2913386
|
jalview.analysis.AlignmentUtilsTests.testMakeCdsAlignment_filterProductsjalview.analysis.AlignmentUtilsTests.testMakeCdsAlignment_filterProducts | 1PASS | ||
|
0.2913386
|
jalview.ws.dbsources.EBIAlphaFoldTest.checkImportPAEToStructurejalview.ws.dbsources.EBIAlphaFoldTest.checkImportPAEToStructure | 1PASS | ||
|
0.2913386
|
jalview.ws.dbsources.EBIAlphaFoldTest.checkImportPAEToStructurejalview.ws.dbsources.EBIAlphaFoldTest.checkImportPAEToStructure | 1PASS | ||
|
0.2913386
|
jalview.analysis.scoremodels.FeatureDistanceModelTest.testFeatureScoreModel_HiddenColumnsjalview.analysis.scoremodels.FeatureDistanceModelTest.testFeatureScoreModel_HiddenColumns | 1PASS | ||
|
0.2913386
|
jalview.analysis.scoremodels.FeatureDistanceModelTest.testFeatureScoreModel_hiddenFirstColumnjalview.analysis.scoremodels.FeatureDistanceModelTest.testFeatureScoreModel_hiddenFirstColumn | 1PASS | ||
|
0.2913386
|
jalview.io.BackupFilesTest.backupsEnabledReverseRollMaxTestjalview.io.BackupFilesTest.backupsEnabledReverseRollMaxTest | 1PASS | ||
|
0.2874016
|
jalview.controller.AlignViewControllerTest.testSelectColumnsWithHighlightjalview.controller.AlignViewControllerTest.testSelectColumnsWithHighlight | 1PASS | ||
|
0.2874016
|
jalview.io.AnnotationExporterTest.testAnnotationExportAsCSVjalview.io.AnnotationExporterTest.testAnnotationExportAsCSV | 1PASS | ||
|
0.28346458
|
jalview.io.PfamFormatInputTest.testPfamFormatValidLimitsjalview.io.PfamFormatInputTest.testPfamFormatValidLimits | 1PASS | ||
|
0.28346458
|
jalview.util.MappingUtilsTest.testMapSequenceGroup_sequencesjalview.util.MappingUtilsTest.testMapSequenceGroup_sequences | 1PASS | ||
|
0.28346458
|
jalview.analysis.scoremodels.SecondaryStructureDistanceModelTest.testFindDistances_withSSUndefinedInEitherOneSeqjalview.analysis.scoremodels.SecondaryStructureDistanceModelTest.testFindDistances_withSSUndefinedInEitherOneSeq | 1PASS | ||
|
0.28346458
|
jalview.analysis.scoremodels.SecondaryStructureDistanceModelTest.testFindDistances_withSSUndefinedInBothSeqsjalview.analysis.scoremodels.SecondaryStructureDistanceModelTest.testFindDistances_withSSUndefinedInBothSeqs | 1PASS | ||
|
0.28346458
|
jalview.gui.AlignViewportTest.testDeregisterMapping_withNoReferencejalview.gui.AlignViewportTest.testDeregisterMapping_withNoReference | 1PASS | ||
|
0.28346458
|
jalview.analysis.scoremodels.SecondaryStructureDistanceModelTest.testFindDistances_withGapjalview.analysis.scoremodels.SecondaryStructureDistanceModelTest.testFindDistances_withGap | 1PASS | ||
|
0.28346458
|
jalview.io.PfamFormatInputTest.testPfamFormatNoLimitsjalview.io.PfamFormatInputTest.testPfamFormatNoLimits | 1PASS | ||
|
0.28346458
|
jalview.gui.AlignViewportTest.testDeregisterMapping_withReferencejalview.gui.AlignViewportTest.testDeregisterMapping_withReference | 1PASS | ||
|
0.27952754
|
jalview.datamodel.AlignmentTest.testCreateDatasetAlignmentWithMappedToSeqsjalview.datamodel.AlignmentTest.testCreateDatasetAlignmentWithMappedToSeqs | 1PASS | ||
|
0.27952754
|
jalview.datamodel.SequenceTest.testIsProteinjalview.datamodel.SequenceTest.testIsProtein | 1PASS | ||
|
0.27559054
|
jalview.datamodel.SequenceTest.testGetPrimaryDBRefs_peptidejalview.datamodel.SequenceTest.testGetPrimaryDBRefs_peptide | 1PASS | ||
|
0.27559054
|
jalview.gui.structurechooser.StructureChooserQuerySourceTest.cascadingThreeDBandPDBQuerysjalview.gui.structurechooser.StructureChooserQuerySourceTest.cascadingThreeDBandPDBQuerys | 1PASS | ||
|
0.27559054
|
jalview.datamodel.SequenceTest.testFindPosition_withCursorAndEditsjalview.datamodel.SequenceTest.testFindPosition_withCursorAndEdits | 1PASS | ||
|
0.27559054
|
jalview.gui.structurechooser.StructureChooserQuerySourceTest.cascadingThreeDBandPDBQuerysjalview.gui.structurechooser.StructureChooserQuerySourceTest.cascadingThreeDBandPDBQuerys | 1PASS | ||
|
0.27559054
|
jalview.gui.StructureChooserTest.displayTDBQueryTestjalview.gui.StructureChooserTest.displayTDBQueryTest | 1PASS | ||
|
0.27559054
|
jalview.datamodel.AlignmentViewTest.testGetVisibleAlignmentGapCharjalview.datamodel.AlignmentViewTest.testGetVisibleAlignmentGapChar | 1PASS | ||
|
0.27559054
|
jalview.gui.AlignViewportTest.testGetConsensusSeqjalview.gui.AlignViewportTest.testGetConsensusSeq | 1PASS | ||
|
0.27559054
|
jalview.gui.structurechooser.StructureChooserQuerySourceTest.cascadingThreeDBandPDBQuerysjalview.gui.structurechooser.StructureChooserQuerySourceTest.cascadingThreeDBandPDBQuerys | 1PASS | ||
|
0.27559054
|
jalview.datamodel.AlignmentTest.testAssertDatasetIsNormalisedjalview.datamodel.AlignmentTest.testAssertDatasetIsNormalised | 1PASS | ||
|
0.27559054
|
jalview.gui.StructureChooserTest.fetchStructuresInfoMockedTestjalview.gui.StructureChooserTest.fetchStructuresInfoMockedTest | 1PASS | ||
|
0.27559054
|
jalview.gui.structurechooser.StructureChooserQuerySourceTest.cascadingThreeDBandPDBQuerysjalview.gui.structurechooser.StructureChooserQuerySourceTest.cascadingThreeDBandPDBQuerys | 1PASS | ||
|
0.27559054
|
jalview.gui.structurechooser.StructureChooserQuerySourceTest.cascadingThreeDBandPDBQuerysjalview.gui.structurechooser.StructureChooserQuerySourceTest.cascadingThreeDBandPDBQuerys | 1PASS | ||
|
0.27559054
|
jalview.gui.structurechooser.StructureChooserQuerySourceTest.buildThreeDBQueryTestjalview.gui.structurechooser.StructureChooserQuerySourceTest.buildThreeDBQueryTest | 1PASS | ||
|
0.27165353
|
jalview.ws.dbsources.UniprotTest.testGetUniprotSequencejalview.ws.dbsources.UniprotTest.testGetUniprotSequence | 1PASS | ||
|
0.27165353
|
jalview.schemes.ColourSchemePropertyTest.testGetColourNamejalview.schemes.ColourSchemePropertyTest.testGetColourName | 1PASS | ||
|
0.27165353
|
jalview.renderer.seqfeatures.FeatureRendererTest.testGetColourjalview.renderer.seqfeatures.FeatureRendererTest.testGetColour | 1PASS | ||
|
0.27165353
|
jalview.schemes.ColourSchemePropertyTest.testGetColourSchemejalview.schemes.ColourSchemePropertyTest.testGetColourScheme | 1PASS | ||
|
0.26771653
|
jalview.analysis.AlignmentUtilsTests.testShowOrHideSequenceAnnotationsjalview.analysis.AlignmentUtilsTests.testShowOrHideSequenceAnnotations | 1PASS | ||
|
0.26771653
|
jalview.gui.PaintRefresherTest.testGetAssociatedPanelsjalview.gui.PaintRefresherTest.testGetAssociatedPanels | 1PASS | ||
|
0.26771653
|
jalview.commands.EditCommandTest.testCut_withFeatures5primejalview.commands.EditCommandTest.testCut_withFeatures5prime | 1PASS | ||
|
0.26771653
|
jalview.datamodel.AlignmentTest.testCreateDataset_updateDbrefMappingsjalview.datamodel.AlignmentTest.testCreateDataset_updateDbrefMappings | 1PASS | ||
|
0.26771653
|
jalview.analysis.scoremodels.FeatureDistanceModelTest.testFindDistances_withParamsjalview.analysis.scoremodels.FeatureDistanceModelTest.testFindDistances_withParams | 1PASS | ||
|
0.26771653
|
jalview.datamodel.HiddenSequencesTest.testAdjustForHiddenSeqsjalview.datamodel.HiddenSequencesTest.testAdjustForHiddenSeqs | 1PASS | ||
|
0.26771653
|
jalview.datamodel.HiddenSequencesTest.testIsHiddenjalview.datamodel.HiddenSequencesTest.testIsHidden | 1PASS | ||
|
0.26377952
|
jalview.datamodel.AlignmentTest.testCopyConstructorjalview.datamodel.AlignmentTest.testCopyConstructor | 1PASS | ||
|
0.26377952
|
jalview.project.Jalview2xmlTests.testStoreAndRecoverAnnotationRowElementColoursjalview.project.Jalview2xmlTests.testStoreAndRecoverAnnotationRowElementColours | 1PASS | ||
|
0.26377952
|
jalview.datamodel.AlignmentTest.testCreateDatasetAlignmentjalview.datamodel.AlignmentTest.testCreateDatasetAlignment | 1PASS | ||
|
0.26377952
|
jalview.datamodel.AlignmentViewTest.testGetVisibleContigsjalview.datamodel.AlignmentViewTest.testGetVisibleContigs | 1PASS | ||
|
0.26377952
|
jalview.bin.CommandsTest.commandsOpenTestjalview.bin.CommandsTest.commandsOpenTest | 1PASS | ||
|
0.25984251
|
jalview.datamodel.SequenceTest.testDeriveSequence_existingDatasetjalview.datamodel.SequenceTest.testDeriveSequence_existingDataset | 1PASS | ||
|
0.25984251
|
jalview.analysis.AlignmentUtilsTests.testGetSequencesByNamejalview.analysis.AlignmentUtilsTests.testGetSequencesByName | 1PASS | ||
|
0.2559055
|
jalview.analysis.AlignmentUtilsTests.testAddReferenceContactMapjalview.analysis.AlignmentUtilsTests.testAddReferenceContactMap | 1PASS | ||
|
0.22440945
|
jalview.datamodel.AlignmentTest.testAlignAs_dnaAsDnajalview.datamodel.AlignmentTest.testAlignAs_dnaAsDna | 1PASS | ||
|
0.22047244
|
jalview.io.vcf.VCFLoaderTest.testDoLoad_reverseStrandjalview.io.vcf.VCFLoaderTest.testDoLoad_reverseStrand | 1PASS | ||
|
0.22047244
|
jalview.project.Jalview2xmlTests.testRNAStructureRecoveryjalview.project.Jalview2xmlTests.testRNAStructureRecovery | 1PASS | ||
|
0.22047244
|
jalview.io.vcf.VCFLoaderTest.testDoLoad_vepCsqjalview.io.vcf.VCFLoaderTest.testDoLoad_vepCsq | 1PASS | ||
|
0.22047244
|
jalview.io.vcf.VCFLoaderTest.testDoLoadjalview.io.vcf.VCFLoaderTest.testDoLoad | 1PASS | ||
|
0.22047244
|
jalview.io.StockholmFileTest.rfamFileIOjalview.io.StockholmFileTest.rfamFileIO | 1PASS | ||
|
0.21653543
|
jalview.analysis.scoremodels.PIDModelTest.testComputePID_matchesComparisonPIDjalview.analysis.scoremodels.PIDModelTest.testComputePID_matchesComparisonPID | 1PASS | ||
|
0.20866142
|
jalview.io.gff.ExonerateHelperTest.testProcessGffSimilarity_protein2dna_forward_targetgffjalview.io.gff.ExonerateHelperTest.testProcessGffSimilarity_protein2dna_forward_targetgff | 1PASS | ||
|
0.20866142
|
jalview.io.gff.ExonerateHelperTest.testProcessGffSimilarity_protein2dna_reverse_targetgffjalview.io.gff.ExonerateHelperTest.testProcessGffSimilarity_protein2dna_reverse_targetgff | 1PASS | ||
|
0.20472442
|
jalview.io.PhylipFileTests.testInterleavedDataExtractionjalview.io.PhylipFileTests.testInterleavedDataExtraction | 1PASS | ||
|
0.20472442
|
jalview.io.PhylipFileTests.testInterleavedIOjalview.io.PhylipFileTests.testInterleavedIO | 1PASS | ||
|
0.20472442
|
jalview.io.PhylipFileTests.testSequentialDataExtractionjalview.io.PhylipFileTests.testSequentialDataExtraction | 1PASS | ||
|
0.20472442
|
jalview.io.PhylipFileTests.testSequentialIOjalview.io.PhylipFileTests.testSequentialIO | 1PASS | ||
|
0.2007874
|
jalview.schemes.ClustalxColourSchemeTest.testFindColour_ignoreGapsjalview.schemes.ClustalxColourSchemeTest.testFindColour_ignoreGaps | 1PASS | ||
|
0.19685039
|
jalview.analysis.AlignmentUtilsTests.testAlignAs_alternateTranscriptsUngappedjalview.analysis.AlignmentUtilsTests.testAlignAs_alternateTranscriptsUngapped | 1PASS | ||
|
0.19685039
|
jalview.analysis.AlignmentUtilsTests.testMakeCdsAlignmentjalview.analysis.AlignmentUtilsTests.testMakeCdsAlignment | 1PASS | ||
|
0.19685039
|
jalview.io.StockholmFileTest.stockholmFileRnaSSAlphaCharsjalview.io.StockholmFileTest.stockholmFileRnaSSAlphaChars | 1PASS | ||
|
0.19685039
|
jalview.analysis.CrossRefTest.testFindXrefSequences_noDbrefsjalview.analysis.CrossRefTest.testFindXrefSequences_noDbrefs | 1PASS | ||
|
0.19685039
|
jalview.gui.ColourMenuHelperTest.testAddMenuItems_nucleotidejalview.gui.ColourMenuHelperTest.testAddMenuItems_nucleotide | 1PASS | ||
|
0.19685039
|
jalview.io.StockholmFileTest.fullWUSSsecondaryStructureForRNASequencejalview.io.StockholmFileTest.fullWUSSsecondaryStructureForRNASequence | 1PASS | ||
|
0.19685039
|
jalview.analysis.AlignmentUtilsTests.testMakeCdsAlignment_alternativeTranscriptsjalview.analysis.AlignmentUtilsTests.testMakeCdsAlignment_alternativeTranscripts | 1PASS | ||
|
0.19685039
|
jalview.analysis.AlignmentUtilsTests.testAlignAsSameSequencesMultipleSubSeqjalview.analysis.AlignmentUtilsTests.testAlignAsSameSequencesMultipleSubSeq | 1PASS | ||
|
0.19685039
|
jalview.io.StockholmFileTest.stockholmFileRnaSSSpaceCharsjalview.io.StockholmFileTest.stockholmFileRnaSSSpaceChars | 1PASS | ||
|
0.19685039
|
jalview.analysis.AlignmentUtilsTests.testAlignAsSameSequencesjalview.analysis.AlignmentUtilsTests.testAlignAsSameSequences | 1PASS | ||
|
0.19685039
|
jalview.io.StockholmFileTest.curlyWUSSsecondaryStructureForRNASequencejalview.io.StockholmFileTest.curlyWUSSsecondaryStructureForRNASequence | 1PASS | ||
|
0.19685039
|
jalview.analysis.AlignmentUtilsTests.testMakeCdsAlignment_multipleProteinsjalview.analysis.AlignmentUtilsTests.testMakeCdsAlignment_multipleProteins | 1PASS | ||
|
0.19685039
|
jalview.io.StockholmFileTest.secondaryStructureForRNASequencejalview.io.StockholmFileTest.secondaryStructureForRNASequence | 1PASS | ||
|
0.18897638
|
jalview.util.ComparisonTest.testPID_includingGapsjalview.util.ComparisonTest.testPID_includingGaps | 1PASS | ||
|
0.18897638
|
jalview.analysis.scoremodels.FeatureDistanceModelTest.testFindFeatureAt_PointFeaturejalview.analysis.scoremodels.FeatureDistanceModelTest.testFindFeatureAt_PointFeature | 1PASS | ||
|
0.18897638
|
jalview.gui.AlignViewportTest.testDeregisterMapping_onCloseViewjalview.gui.AlignViewportTest.testDeregisterMapping_onCloseView | 1PASS | ||
|
0.18110237
|
jalview.gui.SeqPanelTest.testFindMousePosition_wrapped_scales_longSequencejalview.gui.SeqPanelTest.testFindMousePosition_wrapped_scales_longSequence | 1PASS | ||
|
0.18110237
|
jalview.io.RNAMLfileTest.testRnamlToStockholmIOjalview.io.RNAMLfileTest.testRnamlToStockholmIO | 1PASS | ||
|
0.17716536
|
jalview.datamodel.AlignmentTest.testSetDataset_selfReferencejalview.datamodel.AlignmentTest.testSetDataset_selfReference | 1PASS | ||
|
0.16141732
|
jalview.util.ComparisonTest.testPID_ungappedOnlyjalview.util.ComparisonTest.testPID_ungappedOnly | 1PASS | ||
|
0.15354331
|
jalview.datamodel.SequenceTest.testGetPrimaryDBRefs_nucleotidejalview.datamodel.SequenceTest.testGetPrimaryDBRefs_nucleotide | 1PASS | ||
|
0.11811024
|
jalview.ext.ensembl.EnsemblSeqProxyTest.testReverseComplementAllelejalview.ext.ensembl.EnsemblSeqProxyTest.testReverseComplementAllele | 1PASS | ||
|
0.11811024
|
jalview.ext.ensembl.EnsemblSeqProxyTest.testReverseComplementAllelesjalview.ext.ensembl.EnsemblSeqProxyTest.testReverseComplementAlleles | 1PASS | ||
|
0.10236221
|
jalview.gui.AlignFrameTest.testNewView_colourThresholdsjalview.gui.AlignFrameTest.testNewView_colourThresholds | 1PASS | ||
|
0.10236221
|
jalview.gui.AlignmentPanelTest.testSetOverviewTitlejalview.gui.AlignmentPanelTest.testSetOverviewTitle | 1PASS | ||
|
0.10236221
|
jalview.util.ComparisonTest.testIsNucleotideAmbiguityjalview.util.ComparisonTest.testIsNucleotideAmbiguity | 1PASS | ||
|
0.10236221
|
jalview.gui.AlignFrameTest.testNewView_dsRefPreservedjalview.gui.AlignFrameTest.testNewView_dsRefPreserved | 1PASS | ||
|
0.08267716
|
jalview.io.FeaturesFileTest.simpleGff3RelaxedIdMatchingjalview.io.FeaturesFileTest.simpleGff3RelaxedIdMatching | 1PASS | ||
|
0.08267716
|
jalview.io.FeaturesFileTest.simpleGff3FileClassjalview.io.FeaturesFileTest.simpleGff3FileClass | 1PASS | ||
|
0.07480315
|
jalview.io.gff.ExonerateHelperTest.testProcessGffSimilarity_protein2dna_forward_querygffjalview.io.gff.ExonerateHelperTest.testProcessGffSimilarity_protein2dna_forward_querygff | 1PASS | ||
|
0.062992126
|
jalview.io.gff.ExonerateHelperTest.testProcessGffSimilarity_protein2dna_reverse_querygffjalview.io.gff.ExonerateHelperTest.testProcessGffSimilarity_protein2dna_reverse_querygff | 1PASS | ||
|
0.05905512
|
jalview.datamodel.features.FeatureStoreTest.testMinjalview.datamodel.features.FeatureStoreTest.testMin | 1PASS | ||
|
0.05905512
|
jalview.viewmodel.ViewportRangesTest.testScrollRightjalview.viewmodel.ViewportRangesTest.testScrollRight | 1PASS | ||
|
0.05905512
|
jalview.viewmodel.ViewportRangesTest.testSetStartResjalview.viewmodel.ViewportRangesTest.testSetStartRes | 1PASS | ||
|
0.05905512
|
jalview.datamodel.features.FeatureMatcherSetTest.testFromStringjalview.datamodel.features.FeatureMatcherSetTest.testFromString | 1PASS | ||
|
0.05905512
|
jalview.math.SparseMatrixTest.testPostMultiplyjalview.math.SparseMatrixTest.testPostMultiply | 1PASS | ||
|
0.05905512
|
jalview.math.SparseMatrixTest.testPreMultiplyjalview.math.SparseMatrixTest.testPreMultiply | 1PASS | ||
|
0.05905512
|
jalview.datamodel.features.FeatureStoreTest.testListContainsjalview.datamodel.features.FeatureStoreTest.testListContains | 1PASS | ||
|
0.05905512
|
jalview.viewmodel.OverviewDimensionsShowHiddenTest.testFromMouseWithHiddenRowsAtStartWrappedjalview.viewmodel.OverviewDimensionsShowHiddenTest.testFromMouseWithHiddenRowsAtStartWrapped | 1PASS | ||
|
0.05905512
|
jalview.viewmodel.OverviewDimensionsShowHiddenTest.testSetBoxFromMouseClickjalview.viewmodel.OverviewDimensionsShowHiddenTest.testSetBoxFromMouseClick | 1PASS | ||
|
0.05905512
|
jalview.viewmodel.ViewportRangesTest.testSetStartEndResjalview.viewmodel.ViewportRangesTest.testSetStartEndRes | 1PASS | ||
|
0.05905512
|
jalview.datamodel.features.FeatureMatcherSetTest.testAndjalview.datamodel.features.FeatureMatcherSetTest.testAnd | 1PASS | ||
|
0.05905512
|
jalview.viewmodel.styles.ViewStyleTest.testEqualsjalview.viewmodel.styles.ViewStyleTest.testEquals | 1PASS | ||
|
0.05905512
|
jalview.analysis.scoremodels.ScoreModelsTest.testConstructorjalview.analysis.scoremodels.ScoreModelsTest.testConstructor | 1PASS | ||
|
0.05905512
|
jalview.analysis.scoremodels.ScoreMatrixTest.testComputePairwiseScoresjalview.analysis.scoremodels.ScoreMatrixTest.testComputePairwiseScores | 1PASS | ||
|
0.05905512
|
jalview.viewmodel.OverviewDimensionsShowHiddenTest.testSetBoxFromViewportHiddenColsAtEndjalview.viewmodel.OverviewDimensionsShowHiddenTest.testSetBoxFromViewportHiddenColsAtEnd | 1PASS | ||
|
0.05905512
|
jalview.datamodel.features.FeatureStoreTest.testAddFeaturejalview.datamodel.features.FeatureStoreTest.testAddFeature | 1PASS | ||
|
0.05905512
|
jalview.math.SparseMatrixTest.testPreMultiply_tooManyColumnsjalview.math.SparseMatrixTest.testPreMultiply_tooManyColumns | 1PASS | ||
|
0.05905512
|
jalview.viewmodel.ViewportRangesTest.testScrollToVisiblejalview.viewmodel.ViewportRangesTest.testScrollToVisible | 1PASS | ||
|
0.05905512
|
jalview.math.MatrixTest.testTred_reproduciblejalview.math.MatrixTest.testTred_reproducible | 1PASS | ||
|
0.05905512
|
jalview.math.SparseMatrixTest.testTred_matchesMatrixjalview.math.SparseMatrixTest.testTred_matchesMatrix | 1PASS | ||
|
0.05905512
|
jalview.math.MatrixTest.testFindMinMaxjalview.math.MatrixTest.testFindMinMax | 1PASS | ||
|
0.05905512
|
jalview.math.RotatableMatrixTest.testPrintjalview.math.RotatableMatrixTest.testPrint | 1PASS | ||
|
0.05905512
|
jalview.datamodel.features.FeatureMatcherTest.testToStringjalview.datamodel.features.FeatureMatcherTest.testToString | 1PASS | ||
|
0.05905512
|
jalview.analysis.AAFrequencyTest.testCompleteConsensus_includeGaps_showLogojalview.analysis.AAFrequencyTest.testCompleteConsensus_includeGaps_showLogo | 1PASS | ||
|
0.05905512
|
jalview.math.MatrixTest.testFindMinMax_timingjalview.math.MatrixTest.testFindMinMax_timing | 1PASS | ||
|
0.05905512
|
jalview.viewmodel.OverviewDimensionsShowHiddenTest.testSetBoxFromViewportHiddenColsAtStartjalview.viewmodel.OverviewDimensionsShowHiddenTest.testSetBoxFromViewportHiddenColsAtStart | 1PASS | ||
|
0.05905512
|
jalview.datamodel.features.FeatureMatcherSetTest.testGetMatchersjalview.datamodel.features.FeatureMatcherSetTest.testGetMatchers | 1PASS | ||
|
0.05905512
|
jalview.analysis.scoremodels.ScoreMatrixTest.testSymmetricjalview.analysis.scoremodels.ScoreMatrixTest.testSymmetric | 1PASS | ||
|
0.05905512
|
jalview.datamodel.features.FeatureMatcherTest.testMatches_byScorejalview.datamodel.features.FeatureMatcherTest.testMatches_byScore | 1PASS | ||
|
0.05905512
|
jalview.datamodel.features.FeatureMatcherSetTest.testMatches_byAttributejalview.datamodel.features.FeatureMatcherSetTest.testMatches_byAttribute | 1PASS | ||
|
0.05905512
|
jalview.analysis.scoremodels.ScoreMatrixTest.testIsSymmetricjalview.analysis.scoremodels.ScoreMatrixTest.testIsSymmetric | 1PASS | ||
|
0.05905512
|
jalview.io.FeaturesFileTest.testOutputFeatureFiltersjalview.io.FeaturesFileTest.testOutputFeatureFilters | 1PASS | ||
|
0.05905512
|
jalview.datamodel.features.FeatureStoreTest.testFindFeatures_nestedjalview.datamodel.features.FeatureStoreTest.testFindFeatures_nested | 1PASS | ||
|
0.05905512
|
jalview.math.MatrixTest.testReverseRange_maxToZerojalview.math.MatrixTest.testReverseRange_maxToZero | 1PASS | ||
|
0.05905512
|
jalview.math.RotatableMatrixTest.testPreMultiplyjalview.math.RotatableMatrixTest.testPreMultiply | 1PASS | ||
|
0.05905512
|
jalview.viewmodel.OverviewDimensionsShowHiddenTest.testDraggingjalview.viewmodel.OverviewDimensionsShowHiddenTest.testDragging | 1PASS | ||
|
0.05905512
|
jalview.analysis.scoremodels.ScoreMatrixTest.testGetMatrixIndexjalview.analysis.scoremodels.ScoreMatrixTest.testGetMatrixIndex | 1PASS | ||
|
0.05905512
|
jalview.math.SparseMatrixTest.testPreMultiply_tooFewColumnsjalview.math.SparseMatrixTest.testPreMultiply_tooFewColumns | 1PASS | ||
|
0.05905512
|
jalview.io.EmblFlatFileTest.testParse_noUniprotXrefjalview.io.EmblFlatFileTest.testParse_noUniprotXref | 1PASS | ||
|
0.05905512
|
jalview.viewmodel.OverviewDimensionsShowHiddenTest.testPositionInBoxjalview.viewmodel.OverviewDimensionsShowHiddenTest.testPositionInBox | 1PASS | ||
|
0.05905512
|
jalview.bin.ArgsParserTest.testGetValue_decodedjalview.bin.ArgsParserTest.testGetValue_decoded | 1PASS | ||
|
0.05905512
|
jalview.viewmodel.ViewportRangesTest.testEventFiringjalview.viewmodel.ViewportRangesTest.testEventFiring | 1PASS | ||
|
0.05905512
|
jalview.viewmodel.OverviewDimensionsShowHiddenTest.testFromMouseWithHiddenColsAtStartjalview.viewmodel.OverviewDimensionsShowHiddenTest.testFromMouseWithHiddenColsAtStart | 1PASS | ||
|
0.05905512
|
jalview.datamodel.features.FeatureStoreTest.testDelete_readdjalview.datamodel.features.FeatureStoreTest.testDelete_readd | 1PASS | ||
|
0.05905512
|
jalview.datamodel.features.FeatureStoreTest.testGetTotalFeatureLengthjalview.datamodel.features.FeatureStoreTest.testGetTotalFeatureLength | 1PASS | ||
|
0.05905512
|
jalview.datamodel.features.FeatureStoreTest.testDeletejalview.datamodel.features.FeatureStoreTest.testDelete | 1PASS | ||
|
0.05905512
|
jalview.math.SparseMatrixTest.testTred_reproduciblejalview.math.SparseMatrixTest.testTred_reproducible | 1PASS | ||
|
0.05905512
|
jalview.analysis.scoremodels.ScoreMatrixTest.testOutputMatrix_roundTripjalview.analysis.scoremodels.ScoreMatrixTest.testOutputMatrix_roundTrip | 1PASS | ||
|
0.05905512
|
jalview.bin.CacheTest.testSetDatePropertyjalview.bin.CacheTest.testSetDateProperty | 1PASS | ||
|
0.05905512
|
jalview.datamodel.features.FeatureAttributesTest.testGetMinMaxjalview.datamodel.features.FeatureAttributesTest.testGetMinMax | 1PASS | ||
|
0.05905512
|
jalview.datamodel.VisibleRowsIteratorTest.testLastNextEndHiddenjalview.datamodel.VisibleRowsIteratorTest.testLastNextEndHidden | 1PASS | ||
|
0.05905512
|
jalview.analysis.AAFrequencyTest.testCalculate_withProfilejalview.analysis.AAFrequencyTest.testCalculate_withProfile | 1PASS | ||
|
0.05905512
|
jalview.viewmodel.ViewportRangesTest.testSetViewportStartAndWidthWrappedjalview.viewmodel.ViewportRangesTest.testSetViewportStartAndWidthWrapped | 1PASS | ||
|
0.05905512
|
jalview.workers.AlignCalcManagerTest.testRemoveWorkerForAnnotationjalview.workers.AlignCalcManagerTest.testRemoveWorkerForAnnotation | 1PASS | ||
|
0.05905512
|
jalview.io.EmblFlatFileTest.testParsejalview.io.EmblFlatFileTest.testParse | 1PASS | ||
|
0.05905512
|
jalview.math.SparseMatrixTest.testTransposejalview.math.SparseMatrixTest.testTranspose | 1PASS | ||
|
0.05905512
|
jalview.io.FileIOTester.testGziplocalFileIOjalview.io.FileIOTester.testGziplocalFileIO | 1PASS | ||
|
0.05905512
|
jalview.viewmodel.OverviewDimensionsShowHiddenTest.testFromMouseWithHiddenRowsAtEndjalview.viewmodel.OverviewDimensionsShowHiddenTest.testFromMouseWithHiddenRowsAtEnd | 1PASS | ||
|
0.05905512
|
jalview.viewmodel.OverviewDimensionsShowHiddenTest.testSetBoxFromViewportjalview.viewmodel.OverviewDimensionsShowHiddenTest.testSetBoxFromViewport | 1PASS | ||
|
0.05905512
|
jalview.io.FileFormatsTest.testDeregisterFileFormatjalview.io.FileFormatsTest.testDeregisterFileFormat | 1PASS | ||
|
0.05905512
|
jalview.io.vcf.VCFLoaderTest.testLoadVCFContigjalview.io.vcf.VCFLoaderTest.testLoadVCFContig | 1PASS | ||
|
0.05905512
|
jalview.datamodel.features.FeatureMatcherTest.testFromStringjalview.datamodel.features.FeatureMatcherTest.testFromString | 1PASS | ||
|
0.05905512
|
jalview.analysis.scoremodels.ScoreMatrixTest.testBuildSymbolIndexjalview.analysis.scoremodels.ScoreMatrixTest.testBuildSymbolIndex | 1PASS | ||
|
0.05905512
|
jalview.io.FileFormatsTest.testForNamejalview.io.FileFormatsTest.testForName | 1PASS | ||
|
0.05905512
|
jalview.analysis.AAFrequencyTest.testCalculate_noProfilejalview.analysis.AAFrequencyTest.testCalculate_noProfile | 1PASS | ||
|
0.05905512
|
jalview.io.FileFormatsTest.testRegisterFileFormatjalview.io.FileFormatsTest.testRegisterFileFormat | 1PASS | ||
|
0.05905512
|
jalview.viewmodel.OverviewDimensionsShowHiddenTest.testFromMouseWithHiddenRowsAtStartjalview.viewmodel.OverviewDimensionsShowHiddenTest.testFromMouseWithHiddenRowsAtStart | 1PASS | ||
|
0.05905512
|
jalview.datamodel.features.FeatureAttributesTest.testAttributeNameComparatorjalview.datamodel.features.FeatureAttributesTest.testAttributeNameComparator | 1PASS | ||
|
0.05905512
|
jalview.datamodel.features.FeatureStoreTest.testGetPositionalFeaturesjalview.datamodel.features.FeatureStoreTest.testGetPositionalFeatures | 1PASS | ||
|
0.05905512
|
jalview.analysis.scoremodels.ScoreMatrixTest.testConstructor_matrixTooSmalljalview.analysis.scoremodels.ScoreMatrixTest.testConstructor_matrixTooSmall | 1PASS | ||
|
0.05905512
|
jalview.datamodel.features.FeatureStoreTest.testGetMinimumScore_getMaximumScorejalview.datamodel.features.FeatureStoreTest.testGetMinimumScore_getMaximumScore | 1PASS | ||
|
0.05905512
|
jalview.analysis.scoremodels.ScoreMatrixTest.testConstructorjalview.analysis.scoremodels.ScoreMatrixTest.testConstructor | 1PASS | ||
|
0.05905512
|
jalview.viewmodel.OverviewDimensionsShowHiddenTest.testFromMouseWithHiddenColsInMiddlejalview.viewmodel.OverviewDimensionsShowHiddenTest.testFromMouseWithHiddenColsInMiddle | 1PASS | ||
|
0.05905512
|
jalview.datamodel.features.FeatureAttributesTest.testDatatypejalview.datamodel.features.FeatureAttributesTest.testDatatype | 1PASS | ||
|
0.05905512
|
jalview.datamodel.features.FeatureMatcherTest.testIsByAttributejalview.datamodel.features.FeatureMatcherTest.testIsByAttribute | 1PASS | ||
|
0.05905512
|
jalview.datamodel.VisibleRowsIteratorTest.testHasNextAndNextEndHiddenjalview.datamodel.VisibleRowsIteratorTest.testHasNextAndNextEndHidden | 1PASS | ||
|
0.05905512
|
jalview.math.SparseMatrixTest.testPreMultiply_sparseProductjalview.math.SparseMatrixTest.testPreMultiply_sparseProduct | 1PASS | ||
|
0.05905512
|
jalview.io.gff.SequenceOntologyLiteTest.testIsA_sequenceVariantjalview.io.gff.SequenceOntologyLiteTest.testIsA_sequenceVariant | 1PASS | ||
|
0.05905512
|
jalview.schemes.UserColourSchemeTest.testToAppletParameterjalview.schemes.UserColourSchemeTest.testToAppletParameter | 1PASS | ||
|
0.05905512
|
jalview.viewmodel.OverviewDimensionsShowHiddenTest.testFromMouseWithHiddenColsAtEndjalview.viewmodel.OverviewDimensionsShowHiddenTest.testFromMouseWithHiddenColsAtEnd | 1PASS | ||
|
0.05905512
|
jalview.math.SparseMatrixTest.testConstructorjalview.math.SparseMatrixTest.testConstructor | 1PASS | ||
|
0.05905512
|
jalview.io.FileIOTester.testGzipIojalview.io.FileIOTester.testGzipIo | 1PASS | ||
|
0.05905512
|
jalview.viewmodel.styles.ViewStyleTest.testCopyConstructorjalview.viewmodel.styles.ViewStyleTest.testCopyConstructor | 1PASS | ||
|
0.05905512
|
jalview.io.FileFormatsTest.testGetWritableFormatsjalview.io.FileFormatsTest.testGetWritableFormats | 1PASS | ||
|
0.05905512
|
jalview.datamodel.features.FeatureStoreTest.testFindFeatures_contactFeaturesjalview.datamodel.features.FeatureStoreTest.testFindFeatures_contactFeatures | 1PASS | ||
|
0.05905512
|
jalview.io.FileIOTester.testNonGzipURLIOjalview.io.FileIOTester.testNonGzipURLIO | 1PASS | ||
|
0.05905512
|
jalview.viewmodel.OverviewDimensionsShowHiddenTest.testSetBoxFromViewportHiddenColsInMiddlejalview.viewmodel.OverviewDimensionsShowHiddenTest.testSetBoxFromViewportHiddenColsInMiddle | 1PASS | ||
|
0.05905512
|
jalview.analysis.AAFrequencyTest.testCompleteConsensus_ignoreGaps_noLogojalview.analysis.AAFrequencyTest.testCompleteConsensus_ignoreGaps_noLogo | 1PASS | ||
|
0.05905512
|
jalview.io.EmblFlatFileTest.testAdjustForProteinLengthjalview.io.EmblFlatFileTest.testAdjustForProteinLength | 1PASS | ||
|
0.05905512
|
jalview.datamodel.features.FeatureMatcherSetTest.testOrjalview.datamodel.features.FeatureMatcherSetTest.testOr | 1PASS | ||
|
0.05905512
|
jalview.datamodel.features.FeatureMatcherTest.testMatches_byAttributejalview.datamodel.features.FeatureMatcherTest.testMatches_byAttribute | 1PASS | ||
|
0.05905512
|
jalview.schemes.TurnColourSchemeTest.testFindColourjalview.schemes.TurnColourSchemeTest.testFindColour | 1PASS | ||
|
0.05905512
|
jalview.datamodel.features.FeatureStoreTest.testGetFeatureGroupsjalview.datamodel.features.FeatureStoreTest.testGetFeatureGroups | 1PASS | ||
|
0.05905512
|
jalview.bin.CacheTest.testVersionCheckerjalview.bin.CacheTest.testVersionChecker | 1PASS | ||
|
0.05905512
|
jalview.viewmodel.OverviewDimensionsShowHiddenTest.testSetBoxFromViewportHiddenRowsAtEndjalview.viewmodel.OverviewDimensionsShowHiddenTest.testSetBoxFromViewportHiddenRowsAtEnd | 1PASS | ||
|
0.05905512
|
jalview.viewmodel.OverviewDimensionsShowHiddenTest.testSetBoxFromViewportHiddenRowsAtStartjalview.viewmodel.OverviewDimensionsShowHiddenTest.testSetBoxFromViewportHiddenRowsAtStart | 1PASS | ||
|
0.05905512
|
jalview.schemes.UserColourSchemeTest.testParseAppletParameterjalview.schemes.UserColourSchemeTest.testParseAppletParameter | 1PASS | ||
|
0.05905512
|
jalview.analysis.scoremodels.ScoreMatrixTest.testOutputMatrix_htmljalview.analysis.scoremodels.ScoreMatrixTest.testOutputMatrix_html | 1PASS | ||
|
0.05905512
|
jalview.viewmodel.OverviewDimensionsShowHiddenTest.testSetBoxFromViewportHiddenRowsInMiddlejalview.viewmodel.OverviewDimensionsShowHiddenTest.testSetBoxFromViewportHiddenRowsInMiddle | 1PASS | ||
|
0.05905512
|
jalview.datamodel.features.FeatureMatcherSetTest.testToStringjalview.datamodel.features.FeatureMatcherSetTest.testToString | 1PASS | ||
|
0.05905512
|
jalview.math.SparseMatrixTest.testTqli_matchesMatrixjalview.math.SparseMatrixTest.testTqli_matchesMatrix | 1PASS | ||
|
0.05905512
|
jalview.viewmodel.OverviewDimensionsShowHiddenTest.testFromMouseWithHiddenRowsInMiddlejalview.viewmodel.OverviewDimensionsShowHiddenTest.testFromMouseWithHiddenRowsInMiddle | 1PASS | ||
|
0.05905512
|
jalview.datamodel.features.FeatureStoreTest.testShiftFeaturesjalview.datamodel.features.FeatureStoreTest.testShiftFeatures | 1PASS | ||
|
0.05905512
|
jalview.io.FeaturesFileTest.testParseFiltersjalview.io.FeaturesFileTest.testParseFilters | 1PASS | ||
|
0.05905512
|
jalview.analysis.scoremodels.ScoreMatrixTest.testBlosum62_valuesjalview.analysis.scoremodels.ScoreMatrixTest.testBlosum62_values | 1PASS | ||
|
0.05511811
|
jalview.datamodel.VisibleRowsIteratorTest.testLastNextWithHiddenjalview.datamodel.VisibleRowsIteratorTest.testLastNextWithHidden | 1PASS | ||
|
0.05511811
|
jalview.analysis.scoremodels.PIDModelTest.testComputePID_matchLongestSequencejalview.analysis.scoremodels.PIDModelTest.testComputePID_matchLongestSequence | 1PASS | ||
|
0.05511811
|
jalview.datamodel.features.FeatureStoreTest.testGetFeatureLengthjalview.datamodel.features.FeatureStoreTest.testGetFeatureLength | 1PASS | ||
|
0.05511811
|
jalview.math.MatrixTest.testCopyjalview.math.MatrixTest.testCopy | 1PASS | ||
|
0.05511811
|
jalview.io.FileIOTester.testStarsInFasta1jalview.io.FileIOTester.testStarsInFasta1 | 1PASS | ||
|
0.05511811
|
jalview.io.FileFormatsTest.testGetFormatsjalview.io.FileFormatsTest.testGetFormats | 1PASS | ||
|
0.05511811
|
jalview.datamodel.features.FeatureMatcherSetTest.testToStableStringjalview.datamodel.features.FeatureMatcherSetTest.testToStableString | 1PASS | ||
|
0.05511811
|
jalview.math.MatrixTest.testPostMultiplyjalview.math.MatrixTest.testPostMultiply | 1PASS | ||
|
0.05511811
|
jalview.viewmodel.ViewportRangesTest.testSetStartResAndSeqjalview.viewmodel.ViewportRangesTest.testSetStartResAndSeq | 1PASS | ||
|
0.05511811
|
jalview.io.EmblFlatFileTest.testParseToRNAjalview.io.EmblFlatFileTest.testParseToRNA | 1PASS | ||
|
0.05511811
|
jalview.util.ComparisonTest.testIsNucleotidejalview.util.ComparisonTest.testIsNucleotide | 1PASS | ||
|
0.05511811
|
jalview.viewmodel.ViewportRangesTest.testScrollRightWithHiddenjalview.viewmodel.ViewportRangesTest.testScrollRightWithHidden | 1PASS | ||
|
0.05511811
|
jalview.analysis.scoremodels.ScoreMatrixTest.testGetPairwiseScorejalview.analysis.scoremodels.ScoreMatrixTest.testGetPairwiseScore | 1PASS | ||
|
0.05511811
|
jalview.analysis.scoremodels.ScoreMatrixTest.testBuildSymbolIndex_nonAsciijalview.analysis.scoremodels.ScoreMatrixTest.testBuildSymbolIndex_nonAscii | 1PASS | ||
|
0.05511811
|
jalview.math.MatrixTest.testEqualsjalview.math.MatrixTest.testEquals | 1PASS | ||
|
0.05511811
|
jalview.datamodel.VisibleRowsIteratorTest.testLastNextNoHiddenjalview.datamodel.VisibleRowsIteratorTest.testLastNextNoHidden | 1PASS | ||
|
0.05511811
|
jalview.analysis.scoremodels.ScoreMatrixTest.testConstructor_matrixNotSquarejalview.analysis.scoremodels.ScoreMatrixTest.testConstructor_matrixNotSquare | 1PASS | ||
|
0.05511811
|
jalview.math.SparseMatrixTest.testFillRatiojalview.math.SparseMatrixTest.testFillRatio | 1PASS | ||
|
0.05511811
|
jalview.io.FileIOTester.testStarsInFasta2jalview.io.FileIOTester.testStarsInFasta2 | 1PASS | ||
|
0.05511811
|
jalview.datamodel.features.FeatureMatcherSetTest.testMatches_compoundKeyjalview.datamodel.features.FeatureMatcherSetTest.testMatches_compoundKey | 1PASS | ||
|
0.05511811
|
jalview.datamodel.features.FeatureMatcherTest.testGetAttributejalview.datamodel.features.FeatureMatcherTest.testGetAttribute | 1PASS | ||
|
0.05511811
|
jalview.datamodel.features.FeatureMatcherTest.testToStableStringjalview.datamodel.features.FeatureMatcherTest.testToStableString | 1PASS | ||
|
0.05511811
|
jalview.analysis.ParsePropertiesTest.testGetScoresFromDescription_twoScoresjalview.analysis.ParsePropertiesTest.testGetScoresFromDescription_twoScores | 1PASS | ||
|
0.05511811
|
jalview.viewmodel.ViewportRangesTest.testGetAbsoluteAlignmentHeightjalview.viewmodel.ViewportRangesTest.testGetAbsoluteAlignmentHeight | 1PASS | ||
|
0.05511811
|
jalview.bin.ArgsParserTest.testNextValuejalview.bin.ArgsParserTest.testNextValue | 1PASS | ||
|
0.05511811
|
jalview.analysis.GroupingTest.testMakeGroupsWithBothjalview.analysis.GroupingTest.testMakeGroupsWithBoth | 1PASS | ||
|
0.05511811
|
jalview.viewmodel.ViewportRangesTest.testSetViewportStartAndWidthjalview.viewmodel.ViewportRangesTest.testSetViewportStartAndWidth | 1PASS | ||
|
0.05511811
|
jalview.viewmodel.ViewportRangesTest.testSetViewportWidthjalview.viewmodel.ViewportRangesTest.testSetViewportWidth | 1PASS | ||
|
0.05511811
|
jalview.viewmodel.ViewportRangesTest.testSetViewportHeightjalview.viewmodel.ViewportRangesTest.testSetViewportHeight | 1PASS | ||
|
0.05511811
|
jalview.datamodel.features.FeatureStoreTest.testIsEmptyjalview.datamodel.features.FeatureStoreTest.testIsEmpty | 1PASS | ||
|
0.05511811
|
jalview.datamodel.features.FeatureStoreTest.testContainsjalview.datamodel.features.FeatureStoreTest.testContains | 1PASS | ||
|
0.05511811
|
jalview.datamodel.features.FeatureMatcherTest.testIsByScorejalview.datamodel.features.FeatureMatcherTest.testIsByScore | 1PASS | ||
|
0.05511811
|
jalview.analysis.scoremodels.ScoreMatrixTest.testGetMatrixjalview.analysis.scoremodels.ScoreMatrixTest.testGetMatrix | 1PASS | ||
|
0.05511811
|
jalview.viewmodel.ViewportRangesTest.testSetStartEndResWrappedjalview.viewmodel.ViewportRangesTest.testSetStartEndResWrapped | 1PASS | ||
|
0.05511811
|
jalview.datamodel.VisibleRowsIteratorTest.testRemovejalview.datamodel.VisibleRowsIteratorTest.testRemove | 1PASS | ||
|
0.05511811
|
jalview.gui.AnnotationChooserTest.testBuildApplyToOptionsPanel_withSelectionGroupjalview.gui.AnnotationChooserTest.testBuildApplyToOptionsPanel_withSelectionGroup | 1PASS | ||
|
0.05511811
|
jalview.math.RotatableMatrixTest.testGetRotationjalview.math.RotatableMatrixTest.testGetRotation | 1PASS | ||
|
0.05511811
|
jalview.datamodel.features.FeatureMatcherSetTest.testIsEmptyjalview.datamodel.features.FeatureMatcherSetTest.testIsEmpty | 1PASS | ||
|
0.05511811
|
jalview.datamodel.VisibleRowsIteratorTest.testLastNextStartHiddenjalview.datamodel.VisibleRowsIteratorTest.testLastNextStartHidden | 1PASS | ||
|
0.05511811
|
jalview.viewmodel.ViewportRangesTest.testViewportRangesjalview.viewmodel.ViewportRangesTest.testViewportRanges | 1PASS | ||
|
0.05511811
|
jalview.math.MatrixTest.testReverseRange_swapMinMaxjalview.math.MatrixTest.testReverseRange_swapMinMax | 1PASS | ||
|
0.05511811
|
jalview.viewmodel.ViewportRangesTest.testScrollUpjalview.viewmodel.ViewportRangesTest.testScrollUp | 1PASS | ||
|
0.05511811
|
jalview.datamodel.features.FeatureStoreTest.testGetFeaturesForGroupjalview.datamodel.features.FeatureStoreTest.testGetFeaturesForGroup | 1PASS | ||
|
0.05511811
|
jalview.bin.ArgsParserTest.testGetValuejalview.bin.ArgsParserTest.testGetValue | 1PASS | ||
|
0.05511811
|
jalview.viewmodel.ViewportRangesTest.testSetEndSeqjalview.viewmodel.ViewportRangesTest.testSetEndSeq | 1PASS | ||
|
0.05511811
|
jalview.datamodel.features.FeatureStoreTest.testFindFeatures_mixedjalview.datamodel.features.FeatureStoreTest.testFindFeatures_mixed | 1PASS | ||
|
0.05511811
|
jalview.datamodel.features.FeatureAttributesTest.testGetDescriptionjalview.datamodel.features.FeatureAttributesTest.testGetDescription | 1PASS | ||
|
0.05511811
|
jalview.datamodel.HiddenSequencesTest.testHideShowSequence_withHiddenRepSequencejalview.datamodel.HiddenSequencesTest.testHideShowSequence_withHiddenRepSequence | 1PASS | ||
|
0.05511811
|
jalview.datamodel.features.FeatureMatcherTest.testIsByLabeljalview.datamodel.features.FeatureMatcherTest.testIsByLabel | 1PASS | ||
|
0.05511811
|
jalview.io.FileIOTester.testIsGzipInputStreamjalview.io.FileIOTester.testIsGzipInputStream | 1PASS | ||
|
0.05511811
|
jalview.datamodel.features.FeatureMatcherTest.testGetMatcherjalview.datamodel.features.FeatureMatcherTest.testGetMatcher | 1PASS | ||
|
0.05511811
|
jalview.analysis.scoremodels.ScoreMatrixTest.testcomputeSimilarity_matchLongestSequencejalview.analysis.scoremodels.ScoreMatrixTest.testcomputeSimilarity_matchLongestSequence | 1PASS | ||
|
0.05511811
|
jalview.datamodel.HiddenSequencesTest.testAdjustHeightSequenceAddedjalview.datamodel.HiddenSequencesTest.testAdjustHeightSequenceAdded | 1PASS | ||
|
0.05511811
|
jalview.schemes.UserColourSchemeTest.testConstructor_coloursArrayjalview.schemes.UserColourSchemeTest.testConstructor_coloursArray | 1PASS | ||
|
0.05511811
|
jalview.bin.ArgsParserTest.testContainsjalview.bin.ArgsParserTest.testContains | 1PASS | ||
|
0.05511811
|
jalview.datamodel.features.FeatureStoreTest.testFindFeatures_nonNestedjalview.datamodel.features.FeatureStoreTest.testFindFeatures_nonNested | 1PASS | ||
|
0.05511811
|
jalview.math.MatrixTest.testPreMultiply_tooFewColumnsjalview.math.MatrixTest.testPreMultiply_tooFewColumns | 1PASS | ||
|
0.05511811
|
jalview.io.FileIOTester.testNonGziplocalFileIOjalview.io.FileIOTester.testNonGziplocalFileIO | 1PASS | ||
|
0.05511811
|
jalview.viewmodel.ViewportRangesTest.testGetAbsoluteAlignmentWidthjalview.viewmodel.ViewportRangesTest.testGetAbsoluteAlignmentWidth | 1PASS | ||
|
0.05511811
|
jalview.analysis.scoremodels.PIDModelTest.testComputePID_matchShortestSequencejalview.analysis.scoremodels.PIDModelTest.testComputePID_matchShortestSequence | 1PASS | ||
|
0.05511811
|
jalview.structure.AtomSpecModelTest.testGetRangesjalview.structure.AtomSpecModelTest.testGetRanges | 1PASS | ||
|
0.05511811
|
jalview.math.MatrixTest.testMultiplyjalview.math.MatrixTest.testMultiply | 1PASS | ||
|
0.05511811
|
jalview.io.FileFormatsTest.testIsIdentifiablejalview.io.FileFormatsTest.testIsIdentifiable | 1PASS | ||
|
0.051181104
|
jalview.analysis.ParsePropertiesTest.testGetScoresFromDescriptionjalview.analysis.ParsePropertiesTest.testGetScoresFromDescription | 1PASS | ||
|
0.051181104
|
jalview.math.MatrixTest.testPreMultiply_tooManyColumnsjalview.math.MatrixTest.testPreMultiply_tooManyColumns | 1PASS | ||
|
0.051181104
|
jalview.analysis.scoremodels.ScoreMatrixTest.testGetMinimumScorejalview.analysis.scoremodels.ScoreMatrixTest.testGetMinimumScore | 1PASS | ||
|
0.051181104
|
jalview.viewmodel.ViewportRangesTest.testSetViewportStartAndHeightjalview.viewmodel.ViewportRangesTest.testSetViewportStartAndHeight | 1PASS | ||
|
0.051181104
|
jalview.io.FileFormatsTest.testGetReadableFormatsjalview.io.FileFormatsTest.testGetReadableFormats | 1PASS | ||
|
0.051181104
|
jalview.datamodel.VisibleRowsIteratorTest.testHasNextAndNextStartHiddenjalview.datamodel.VisibleRowsIteratorTest.testHasNextAndNextStartHidden | 1PASS | ||
|
0.051181104
|
jalview.viewmodel.ViewportRangesTest.testScrollUpWithHiddenjalview.viewmodel.ViewportRangesTest.testScrollUpWithHidden | 1PASS | ||
|
0.051181104
|
jalview.datamodel.VisibleRowsIteratorTest.testHasNextAndNextNoHiddenjalview.datamodel.VisibleRowsIteratorTest.testHasNextAndNextNoHidden | 1PASS | ||
|
0.051181104
|
jalview.math.MatrixTest.testConstructorjalview.math.MatrixTest.testConstructor | 1PASS | ||
|
0.051181104
|
jalview.viewmodel.ViewportRangesTest.testSetStartSeqjalview.viewmodel.ViewportRangesTest.testSetStartSeq | 1PASS | ||
|
0.051181104
|
jalview.analysis.FinderTest.testFindAll_sequenceIdsjalview.analysis.FinderTest.testFindAll_sequenceIds | 1PASS | ||
|
0.051181104
|
jalview.viewmodel.ViewportRangesTest.testSetStartEndSeqjalview.viewmodel.ViewportRangesTest.testSetStartEndSeq | 1PASS | ||
|
0.051181104
|
jalview.math.RotatableMatrixTest.testVectorMultiplyjalview.math.RotatableMatrixTest.testVectorMultiply | 1PASS | ||
|
0.051181104
|
jalview.analysis.scoremodels.ScoreMatrixTest.testConstructor_gapDashjalview.analysis.scoremodels.ScoreMatrixTest.testConstructor_gapDash | 1PASS | ||
|
0.051181104
|
jalview.analysis.scoremodels.ScoreMatrixTest.testcomputeSimilarity_matchShortestSequencejalview.analysis.scoremodels.ScoreMatrixTest.testcomputeSimilarity_matchShortestSequence | 1PASS | ||
|
0.051181104
|
jalview.io.EmblFlatFileTest.testParse_codonStartNot1jalview.io.EmblFlatFileTest.testParse_codonStartNot1 | 1PASS | ||
|
0.051181104
|
jalview.analysis.scoremodels.ScoreMatrixTest.testGetSizejalview.analysis.scoremodels.ScoreMatrixTest.testGetSize | 1PASS | ||
|
0.051181104
|
jalview.analysis.scoremodels.ScoreMatrixTest.testGetMaximumScorejalview.analysis.scoremodels.ScoreMatrixTest.testGetMaximumScore | 1PASS | ||
|
0.051181104
|
jalview.datamodel.features.FeatureStoreTest.testMaxjalview.datamodel.features.FeatureStoreTest.testMax | 1PASS | ||
|
0.051181104
|
jalview.commands.EditCommandTest.testReplaceFirstResiduesWithGapsjalview.commands.EditCommandTest.testReplaceFirstResiduesWithGaps | 1PASS | ||
|
0.051181104
|
jalview.io.EmblFlatFileTest.testRemoveQuotesjalview.io.EmblFlatFileTest.testRemoveQuotes | 1PASS | ||
|
0.051181104
|
jalview.analysis.FinderTest.testFind_inDescriptionjalview.analysis.FinderTest.testFind_inDescription | 1PASS | ||
|
0.051181104
|
jalview.analysis.scoremodels.ScoreMatrixTest.testConstructor_matrixTooBigjalview.analysis.scoremodels.ScoreMatrixTest.testConstructor_matrixTooBig | 1PASS | ||
|
0.051181104
|
jalview.datamodel.VisibleRowsIteratorTest.testHasNextAndNextWithHiddenjalview.datamodel.VisibleRowsIteratorTest.testHasNextAndNextWithHidden | 1PASS | ||
|
0.051181104
|
jalview.math.MatrixTest.testPreMultiplyjalview.math.MatrixTest.testPreMultiply | 1PASS | ||
|
0.051181104
|
jalview.viewmodel.ViewportRangesTest.testPageUpDownjalview.viewmodel.ViewportRangesTest.testPageUpDown | 1PASS | ||
|
0.051181104
|
jalview.analysis.scoremodels.PIDModelTest.testGetPairwiseScorejalview.analysis.scoremodels.PIDModelTest.testGetPairwiseScore | 1PASS | ||
|
0.047244094
|
jalview.analysis.scoremodels.ScoreMatrixTest.testEqualsAndHashCodejalview.analysis.scoremodels.ScoreMatrixTest.testEqualsAndHashCode | 1PASS | ||
|
0.047244094
|
jalview.datamodel.HiddenSequencesTest.testAdjustHeightSequenceDeletedjalview.datamodel.HiddenSequencesTest.testAdjustHeightSequenceDeleted | 1PASS | ||
|
0.047244094
|
jalview.schemes.HydrophobicColourSchemeTest.testFindColourjalview.schemes.HydrophobicColourSchemeTest.testFindColour | 1PASS | ||
|
0.047244094
|
jalview.io.gff.Gff3HelperTest.testGetDescriptionjalview.io.gff.Gff3HelperTest.testGetDescription | 1PASS | ||
|
0.047244094
|
jalview.io.gff.ExonerateHelperTest.testGetMappingTypejalview.io.gff.ExonerateHelperTest.testGetMappingType | 1PASS | ||
|
0.047244094
|
jalview.datamodel.HiddenSequencesTest.testGetWidthjalview.datamodel.HiddenSequencesTest.testGetWidth | 1PASS | ||
|
0.047244094
|
jalview.renderer.ResidueShaderTest.testFindColour_gapColourjalview.renderer.ResidueShaderTest.testFindColour_gapColour | 1PASS | ||
|
0.047244094
|
jalview.datamodel.features.FeatureMatcherTest.testMatches_byLabeljalview.datamodel.features.FeatureMatcherTest.testMatches_byLabel | 1PASS | ||
|
0.047244094
|
jalview.datamodel.HiddenSequencesTest.testFindIndexWithoutHiddenSeqsjalview.datamodel.HiddenSequencesTest.testFindIndexWithoutHiddenSeqs | 1PASS | ||
|
0.047244094
|
jalview.datamodel.HiddenSequencesTest.testHideShowSequencejalview.datamodel.HiddenSequencesTest.testHideShowSequence | 1PASS | ||
|
0.047244094
|
jalview.datamodel.HiddenSequencesTest.testGetHiddenSequencejalview.datamodel.HiddenSequencesTest.testGetHiddenSequence | 1PASS | ||
|
0.047244094
|
jalview.datamodel.HiddenSequencesTest.testGetFullAlignmentjalview.datamodel.HiddenSequencesTest.testGetFullAlignment | 1PASS | ||
|
0.047244094
|
jalview.datamodel.HiddenSequencesTest.testFindIndexNFromRowjalview.datamodel.HiddenSequencesTest.testFindIndexNFromRow | 1PASS | ||
|
0.047244094
|
jalview.datamodel.HiddenSequencesTest.testHideShowLastSequencesjalview.datamodel.HiddenSequencesTest.testHideShowLastSequences | 1PASS | ||
|
0.03937008
|
jalview.gui.AlignFrameTest.testChangeColour_background_groupsAndThresholdsjalview.gui.AlignFrameTest.testChangeColour_background_groupsAndThresholds | 1PASS | ||
|
0.031496063
|
jalview.io.gff.Gff3HelperTest.testProcessCdnaMatch_forwardToReversejalview.io.gff.Gff3HelperTest.testProcessCdnaMatch_forwardToReverse | 1PASS | ||
|
0.031496063
|
jalview.io.gff.Gff3HelperTest.testProcessCdnaMatch_reverseToForwardjalview.io.gff.Gff3HelperTest.testProcessCdnaMatch_reverseToForward | 1PASS | ||
|
0.031496063
|
jalview.io.gff.Gff3HelperTest.testProcessCdnaMatch_splicedjalview.io.gff.Gff3HelperTest.testProcessCdnaMatch_spliced | 1PASS | ||
|
0.031496063
|
jalview.io.gff.InterProScanHelperTest.testProcessProteinMatchjalview.io.gff.InterProScanHelperTest.testProcessProteinMatch | 1PASS | ||
|
0.031496063
|
jalview.io.gff.Gff3HelperTest.testProcessCdnaMatch_forwardToForwardjalview.io.gff.Gff3HelperTest.testProcessCdnaMatch_forwardToForward | 1PASS | ||
|
0.031496063
|
jalview.datamodel.AlignedCodonFrameTest.testFindAlignedSequencejalview.datamodel.AlignedCodonFrameTest.testFindAlignedSequence | 1PASS | ||
|
0.023622047
|
jalview.datamodel.AlignmentTest.testAddCodonFramejalview.datamodel.AlignmentTest.testAddCodonFrame | 1PASS | ||
|
0.023622047
|
jalview.datamodel.AlignmentTest.testSetHiddenColumnsjalview.datamodel.AlignmentTest.testSetHiddenColumns | 1PASS | ||
|
0.01968504
|
mc_view.PDBChainTest.testMakeExactMappingmc_view.PDBChainTest.testMakeExactMapping | 1PASS | ||
|
0.01968504
|
jalview.analysis.TestAlignSeq.testPrintAlignmentjalview.analysis.TestAlignSeq.testPrintAlignment | 1PASS | ||
|
0.015748031
|
jalview.util.ComparisonTest.testNucleotideProportionjalview.util.ComparisonTest.testNucleotideProportion | 1PASS | ||
|
0.015748031
|
jalview.util.ComparisonTest.testIsSameResiduejalview.util.ComparisonTest.testIsSameResidue | 1PASS | ||
|
0.007874016
|
jalview.renderer.seqfeatures.FeatureColourFinderTest.testFindFeatureColour_graduatedWithThresholdjalview.renderer.seqfeatures.FeatureColourFinderTest.testFindFeatureColour_graduatedWithThreshold | 1PASS | ||
|
0.007874016
|
jalview.renderer.seqfeatures.FeatureColourFinderTest.testFindFeatureColour_graduatedFeatureColourjalview.renderer.seqfeatures.FeatureColourFinderTest.testFindFeatureColour_graduatedFeatureColour | 1PASS | ||
|
0.007874016
|
jalview.commands.EditCommandTest.testUndo_multipleCommandsjalview.commands.EditCommandTest.testUndo_multipleCommands | 1PASS | ||
|
0.007874016
|
jalview.datamodel.AlignedCodonFrameTest.testRealiseWithjalview.datamodel.AlignedCodonFrameTest.testRealiseWith | 1PASS | ||
|
0.007874016
|
jalview.commands.EditCommandTest.testUndo_multipleInsertGapsjalview.commands.EditCommandTest.testUndo_multipleInsertGaps | 1PASS | ||
|
0.007874016
|
jalview.analysis.CrossRefTest.testSameSequencejalview.analysis.CrossRefTest.testSameSequence | 1PASS | ||
|
0.007874016
|
jalview.gui.PopupMenuTest.testHideInsertionsjalview.gui.PopupMenuTest.testHideInsertions | 1PASS | ||
|
0.007874016
|
jalview.commands.EditCommandTest.testAddEdit_groupInsertGapsjalview.commands.EditCommandTest.testAddEdit_groupInsertGaps | 1PASS | ||
|
0.007874016
|
jalview.io.GenBankFileTest.testParsejalview.io.GenBankFileTest.testParse | 1PASS | ||
|
0.007874016
|
jalview.gui.StructureViewerTest.testGetSequencesForPdbsjalview.gui.StructureViewerTest.testGetSequencesForPdbs | 1PASS | ||
|
0.007874016
|
jalview.datamodel.SearchResultsTest.testMatchContainsjalview.datamodel.SearchResultsTest.testMatchContains | 1PASS | ||
|
0.007874016
|
jalview.analysis.ConservationTest.testCountConservationAndGapsjalview.analysis.ConservationTest.testCountConservationAndGaps | 1PASS | ||
|
0.007874016
|
jalview.datamodel.ResidueCountTest.test_unexpectedPeptidejalview.datamodel.ResidueCountTest.test_unexpectedPeptide | 1PASS | ||
|
0.007874016
|
jalview.datamodel.SearchResultsTest.testToStringjalview.datamodel.SearchResultsTest.testToString | 1PASS | ||
|
0.007874016
|
mc_view.PDBChainTest.testMakeResidueList_withTempFactormc_view.PDBChainTest.testMakeResidueList_withTempFactor | 1PASS | ||
|
0.007874016
|
jalview.datamodel.SequenceTest.testReplacejalview.datamodel.SequenceTest.testReplace | 1PASS | ||
|
0.007874016
|
jalview.datamodel.AlignedCodonFrameTest.testIsRealisableWithjalview.datamodel.AlignedCodonFrameTest.testIsRealisableWith | 1PASS | ||
|
0.007874016
|
jalview.ext.jmol.JmolParserTest.testParse_missingResiduesjalview.ext.jmol.JmolParserTest.testParse_missingResidues | 1PASS | ||
|
0.007874016
|
jalview.io.SequenceAnnotationReportTest.testAppendFeature_virtualFeaturejalview.io.SequenceAnnotationReportTest.testAppendFeature_virtualFeature | 1PASS | ||
|
0.007874016
|
jalview.gui.AnnotationLabelsTest.testGetStatusMessagejalview.gui.AnnotationLabelsTest.testGetStatusMessage | 1PASS | ||
|
0.007874016
|
jalview.schemes.AnnotationColourGradientTest.testFindColour_aboveThresholdjalview.schemes.AnnotationColourGradientTest.testFindColour_aboveThreshold | 1PASS | ||
|
0.007874016
|
jalview.datamodel.AlignedCodonIteratorTest.testAnotherjalview.datamodel.AlignedCodonIteratorTest.testAnother | 1PASS | ||
|
0.007874016
|
jalview.datamodel.SequenceTest.testSetDatasetSequence_cascadingjalview.datamodel.SequenceTest.testSetDatasetSequence_cascading | 1PASS | ||
|
0.007874016
|
jalview.analysis.FinderTest.testFind_residueNumberjalview.analysis.FinderTest.testFind_residueNumber | 1PASS | ||
|
0.007874016
|
jalview.datamodel.PAEContactMatrixTest.testMappableContactMatrixjalview.datamodel.PAEContactMatrixTest.testMappableContactMatrix | 1PASS | ||
|
0.007874016
|
jalview.datamodel.SequenceTest.testCheckValidRangejalview.datamodel.SequenceTest.testCheckValidRange | 1PASS | ||
|
0.007874016
|
jalview.datamodel.AlignedCodonFrameTest.testMarkMappedRegionjalview.datamodel.AlignedCodonFrameTest.testMarkMappedRegion | 1PASS | ||
|
0.007874016
|
jalview.datamodel.SequenceTest.testAddDBRefjalview.datamodel.SequenceTest.testAddDBRef | 1PASS | ||
|
0.007874016
|
jalview.commands.EditCommandTest.testAppendEdit_deleteGapjalview.commands.EditCommandTest.testAppendEdit_deleteGap | 1PASS | ||
|
0.007874016
|
jalview.datamodel.SequenceTest.testFindPositionMapjalview.datamodel.SequenceTest.testFindPositionMap | 1PASS | ||
|
0.007874016
|
jalview.ext.jmol.JmolParserTest.testLocalPDBIdjalview.ext.jmol.JmolParserTest.testLocalPDBId | 1PASS | ||
|
0.007874016
|
jalview.ext.ensembl.EnsemblGeneTest.testGetTranscriptFeaturesjalview.ext.ensembl.EnsemblGeneTest.testGetTranscriptFeatures | 1PASS | ||
|
0.007874016
|
jalview.datamodel.ResidueCountTest.testAddGapjalview.datamodel.ResidueCountTest.testAddGap | 1PASS | ||
|
0.007874016
|
jalview.util.MappingUtilsTest.testFindMappingsForSequencejalview.util.MappingUtilsTest.testFindMappingsForSequence | 1PASS | ||
|
0.007874016
|
jalview.util.DBRefUtilsTest.testParseToDbRefjalview.util.DBRefUtilsTest.testParseToDbRef | 1PASS | ||
|
0.007874016
|
jalview.datamodel.MatchTest.testToStringjalview.datamodel.MatchTest.testToString | 1PASS | ||
|
0.007874016
|
jalview.analysis.AlignmentUtilsTests.testAddMappedPositionsjalview.analysis.AlignmentUtilsTests.testAddMappedPositions | 1PASS | ||
|
0.007874016
|
jalview.datamodel.SequenceTest.testFindIndexjalview.datamodel.SequenceTest.testFindIndex | 1PASS | ||
|
0.007874016
|
jalview.datamodel.SearchResultsTest.testEqualsjalview.datamodel.SearchResultsTest.testEquals | 1PASS | ||
|
0.007874016
|
jalview.datamodel.SequenceTest.testAddSequenceFeaturesjalview.datamodel.SequenceTest.testAddSequenceFeatures | 1PASS | ||
|
0.007874016
|
jalview.io.NewickFileTests.testTreeIOjalview.io.NewickFileTests.testTreeIO | 1PASS | ||
|
0.007874016
|
jalview.datamodel.SequenceTest.testFindPositionjalview.datamodel.SequenceTest.testFindPosition | 1PASS | ||
|
0.007874016
|
jalview.commands.EditCommandTest.testCut_withFeaturesjalview.commands.EditCommandTest.testCut_withFeatures | 1PASS | ||
|
0.007874016
|
jalview.datamodel.SequenceTest.testFindPositionsjalview.datamodel.SequenceTest.testFindPositions | 1PASS | ||
|
0.007874016
|
mc_view.PDBChainTest.testMakeCaBondList_nucleotidemc_view.PDBChainTest.testMakeCaBondList_nucleotide | 1PASS | ||
|
0.007874016
|
jalview.datamodel.SequenceTest.testGetStartGetEndjalview.datamodel.SequenceTest.testGetStartGetEnd | 1PASS | ||
|
0.007874016
|
jalview.commands.TrimRegionCommandTest.testTrimLeft_oneColumnjalview.commands.TrimRegionCommandTest.testTrimLeft_oneColumn | 1PASS | ||
|
0.007874016
|
jalview.datamodel.SequenceTest.testGapMapjalview.datamodel.SequenceTest.testGapMap | 1PASS | ||
|
0.007874016
|
jalview.util.MappingUtilsTest.testBuildSearchResultsjalview.util.MappingUtilsTest.testBuildSearchResults | 1PASS | ||
|
0.007874016
|
jalview.datamodel.DBRefEntryTest.testIsPrimaryCandidatejalview.datamodel.DBRefEntryTest.testIsPrimaryCandidate | 1PASS | ||
|
0.007874016
|
jalview.util.StringUtilsTest.testSeparatorListToArrayjalview.util.StringUtilsTest.testSeparatorListToArray | 1PASS | ||
|
0.007874016
|
jalview.renderer.seqfeatures.FeatureColourFinderTest.testFindFeatureColour_transparencySingleFeaturejalview.renderer.seqfeatures.FeatureColourFinderTest.testFindFeatureColour_transparencySingleFeature | 1PASS | ||
|
0.007874016
|
jalview.renderer.seqfeatures.FeatureColourFinderTest.testFindFeatureAtEndjalview.renderer.seqfeatures.FeatureColourFinderTest.testFindFeatureAtEnd | 1PASS | ||
|
0.007874016
|
jalview.structure.StructureMappingTest.testEqualsjalview.structure.StructureMappingTest.testEquals | 1PASS | ||
|
0.007874016
|
jalview.datamodel.SequenceTest.testSetNamejalview.datamodel.SequenceTest.testSetName | 1PASS | ||
|
0.007874016
|
jalview.util.StringUtilsTest.testStripHtmlTagsjalview.util.StringUtilsTest.testStripHtmlTags | 1PASS | ||
|
0.007874016
|
jalview.ext.ensembl.EnsemblCdsTest.testGetGenomicRangesFromFeaturesjalview.ext.ensembl.EnsemblCdsTest.testGetGenomicRangesFromFeatures | 1PASS | ||
|
0.007874016
|
jalview.ws.dbsources.EmblXmlSourceTest.testGetSequencejalview.ws.dbsources.EmblXmlSourceTest.testGetSequence | 1PASS | ||
|
0.007874016
|
jalview.io.RNAMLfileTest.testRnamlSeqImportjalview.io.RNAMLfileTest.testRnamlSeqImport | 1PASS | ||
|
0.007874016
|
jalview.structure.StructureSelectionManagerTest.testRegisterMappingsjalview.structure.StructureSelectionManagerTest.testRegisterMappings | 1PASS | ||
|
0.007874016
|
jalview.datamodel.AlignedCodonFrameTest.testGetCoveringMappingjalview.datamodel.AlignedCodonFrameTest.testGetCoveringMapping | 1PASS | ||
|
0.007874016
|
jalview.analysis.AlignmentUtilsTests.testAlignSequenceAs_withMapping_withUnmappedProteinjalview.analysis.AlignmentUtilsTests.testAlignSequenceAs_withMapping_withUnmappedProtein | 1PASS | ||
|
0.007874016
|
jalview.datamodel.SequenceTest.testDeriveSequence_noDatasetUngappedjalview.datamodel.SequenceTest.testDeriveSequence_noDatasetUngapped | 1PASS | ||
|
0.007874016
|
jalview.datamodel.SequenceGroupTest.testAddSequencejalview.datamodel.SequenceGroupTest.testAddSequence | 1PASS | ||
|
0.007874016
|
jalview.io.SequenceAnnotationReportTest.testCreateSequenceAnnotationReport_withEllipsisjalview.io.SequenceAnnotationReportTest.testCreateSequenceAnnotationReport_withEllipsis | 1PASS | ||
|
0.007874016
|
jalview.datamodel.AlignedCodonFrameTest.testGetMappedCodons_dnaVariantsjalview.datamodel.AlignedCodonFrameTest.testGetMappedCodons_dnaVariants | 1PASS | ||
|
0.007874016
|
jalview.util.MappingUtilsTest.testBuildSearchResults_withIntronjalview.util.MappingUtilsTest.testBuildSearchResults_withIntron | 1PASS | ||
|
0.007874016
|
jalview.datamodel.SequenceGroupTest.testConstructor_listjalview.datamodel.SequenceGroupTest.testConstructor_list | 1PASS | ||
|
0.007874016
|
jalview.ws.dbsources.EBIAlphaFoldTest.checkPAEimportjalview.ws.dbsources.EBIAlphaFoldTest.checkPAEimport | 1PASS | ||
|
0.007874016
|
jalview.datamodel.SearchResultsTest.testMatchAdjacentjalview.datamodel.SearchResultsTest.testMatchAdjacent | 1PASS | ||
|
0.007874016
|
jalview.analysis.AlignmentUtilsTests.testAlignSequenceAs_withMapping_noIntronsjalview.analysis.AlignmentUtilsTests.testAlignSequenceAs_withMapping_noIntrons | 1PASS | ||
|
0.007874016
|
jalview.ext.jmol.JmolParserTest.testParse_alternativeResiduesjalview.ext.jmol.JmolParserTest.testParse_alternativeResidues | 1PASS | ||
|
0.007874016
|
jalview.datamodel.HiddenColumnsTest.testHideInsertionsForjalview.datamodel.HiddenColumnsTest.testHideInsertionsFor | 1PASS | ||
|
0.007874016
|
jalview.ext.ensembl.EnsemblGenomeTest.testGetIdentifyingFeaturesjalview.ext.ensembl.EnsemblGenomeTest.testGetIdentifyingFeatures | 1PASS | ||
|
0.007874016
|
jalview.schemes.BuriedColourSchemeTest.testFindColourjalview.schemes.BuriedColourSchemeTest.testFindColour | 1PASS | ||
|
0.007874016
|
jalview.datamodel.SequenceTest.testInsertGapsAndGapmapsjalview.datamodel.SequenceTest.testInsertGapsAndGapmaps | 1PASS | ||
|
0.007874016
|
jalview.datamodel.SequenceTest.testTransferAnnotationjalview.datamodel.SequenceTest.testTransferAnnotation | 1PASS | ||
|
0.007874016
|
jalview.commands.EditCommandTest.testPriorState_removeGapsMultipleSeqsjalview.commands.EditCommandTest.testPriorState_removeGapsMultipleSeqs | 1PASS | ||
|
0.007874016
|
jalview.analysis.FinderTest.testFind_ignoreHiddenColumnsjalview.analysis.FinderTest.testFind_ignoreHiddenColumns | 1PASS | ||
|
0.007874016
|
jalview.datamodel.SequenceTest.testGetSequenceFeaturesjalview.datamodel.SequenceTest.testGetSequenceFeatures | 1PASS | ||
|
0.007874016
|
jalview.ext.ensembl.EnsemblGeneTest.testGetGenomicRangesFromFeatures_ncRNA_gene_reverseStrandjalview.ext.ensembl.EnsemblGeneTest.testGetGenomicRangesFromFeatures_ncRNA_gene_reverseStrand | 1PASS | ||
|
0.007874016
|
jalview.structures.models.AAStructureBindingModelTest.testFindSuperposableResidues_hiddenColumnjalview.structures.models.AAStructureBindingModelTest.testFindSuperposableResidues_hiddenColumn | 1PASS | ||
|
0.007874016
|
jalview.datamodel.SequenceTest.testInsertCharAtjalview.datamodel.SequenceTest.testInsertCharAt | 1PASS | ||
|
0.007874016
|
jalview.renderer.ContactGeometryTest.testCoverageofRangejalview.renderer.ContactGeometryTest.testCoverageofRange | 1PASS | ||
|
0.007874016
|
jalview.gui.AlignFrameTest.testColourThresholdActionsjalview.gui.AlignFrameTest.testColourThresholdActions | 1PASS | ||
|
0.007874016
|
mc_view.PDBChainTest.testMakeResidueList_noAnnotationmc_view.PDBChainTest.testMakeResidueList_noAnnotation | 1PASS | ||
|
0.007874016
|
jalview.datamodel.AlignedCodonFrameTest.testGetMappedRegion_eitherWayjalview.datamodel.AlignedCodonFrameTest.testGetMappedRegion_eitherWay | 1PASS | ||
|
0.007874016
|
jalview.io.NewickFileTests.testTreeIOjalview.io.NewickFileTests.testTreeIO | 1PASS | ||
|
0.007874016
|
jalview.commands.EditCommandTest.testPriorState_removeGappedColsjalview.commands.EditCommandTest.testPriorState_removeGappedCols | 1PASS | ||
|
0.007874016
|
jalview.datamodel.SearchResultsTest.testGetSequencesjalview.datamodel.SearchResultsTest.testGetSequences | 1PASS | ||
|
0.007874016
|
jalview.datamodel.SequenceFeatureTest.testGetDetailsReportjalview.datamodel.SequenceFeatureTest.testGetDetailsReport | 1PASS | ||
|
0.007874016
|
jalview.analysis.AlignmentUtilsTests.testAlignSequenceAs_keepIntronGapsOnlyjalview.analysis.AlignmentUtilsTests.testAlignSequenceAs_keepIntronGapsOnly | 1PASS | ||
|
0.007874016
|
jalview.datamodel.SearchResultsTest.testMarkColumnsjalview.datamodel.SearchResultsTest.testMarkColumns | 1PASS | ||
|
0.007874016
|
jalview.gui.AnnotationColumnChooserTest.testResetjalview.gui.AnnotationColumnChooserTest.testReset | 1PASS | ||
|
0.007874016
|
jalview.util.ComparisonTest.testIsGapjalview.util.ComparisonTest.testIsGap | 1PASS | ||
|
0.007874016
|
jalview.datamodel.AlignmentAnnotationTests.testAdjustForAlignmentjalview.datamodel.AlignmentAnnotationTests.testAdjustForAlignment | 1PASS | ||
|
0.007874016
|
jalview.commands.TrimRegionCommandTest.testTrimLeft_withUndoAndRedojalview.commands.TrimRegionCommandTest.testTrimLeft_withUndoAndRedo | 1PASS | ||
|
0.007874016
|
jalview.datamodel.SequenceDummyTest.testBecomejalview.datamodel.SequenceDummyTest.testBecome | 1PASS | ||
|
0.007874016
|
jalview.commands.EditCommandTest.testPriorState_singleDeletejalview.commands.EditCommandTest.testPriorState_singleDelete | 1PASS | ||
|
0.007874016
|
jalview.util.StringUtilsTest.testToSentenceCasejalview.util.StringUtilsTest.testToSentenceCase | 1PASS | ||
|
0.007874016
|
jalview.datamodel.SequenceFeatureTest.testGetDetailsReport_virtualFeaturejalview.datamodel.SequenceFeatureTest.testGetDetailsReport_virtualFeature | 1PASS | ||
|
0.007874016
|
jalview.datamodel.ResidueCountTest.testToStringjalview.datamodel.ResidueCountTest.testToString | 1PASS | ||
|
0.007874016
|
jalview.renderer.seqfeatures.FeatureColourFinderTest.testFindFeatureColour_nestedFeaturesjalview.renderer.seqfeatures.FeatureColourFinderTest.testFindFeatureColour_nestedFeatures | 1PASS | ||
|
0.007874016
|
jalview.datamodel.SearchResultsTest.testHashcodejalview.datamodel.SearchResultsTest.testHashcode | 1PASS | ||
|
0.007874016
|
jalview.util.StringUtilsTest.testListToDelimitedStringjalview.util.StringUtilsTest.testListToDelimitedString | 1PASS | ||
|
0.007874016
|
jalview.commands.TrimRegionCommandTest.testTrimRight_oneColumnjalview.commands.TrimRegionCommandTest.testTrimRight_oneColumn | 1PASS | ||
|
0.007874016
|
jalview.datamodel.SearchResultsTest.testMatchConstructorjalview.datamodel.SearchResultsTest.testMatchConstructor | 1PASS | ||
|
0.007874016
|
jalview.renderer.seqfeatures.FeatureColourFinderTest.testFindFeatureColour_multipleFeaturesAtPositionNoTransparencyjalview.renderer.seqfeatures.FeatureColourFinderTest.testFindFeatureColour_multipleFeaturesAtPositionNoTransparency | 1PASS | ||
|
0.007874016
|
jalview.schemes.StrandColourSchemeTest.testFindColourjalview.schemes.StrandColourSchemeTest.testFindColour | 1PASS | ||
|
0.007874016
|
jalview.structure.StructureSelectionManagerTest.testRegisterMappingjalview.structure.StructureSelectionManagerTest.testRegisterMapping | 1PASS | ||
|
0.007874016
|
jalview.analysis.AlignmentUtilsTests.testHasCrossRefjalview.analysis.AlignmentUtilsTests.testHasCrossRef | 1PASS | ||
|
0.007874016
|
jalview.datamodel.AlignedCodonFrameTest.testGetMappedCodonsjalview.datamodel.AlignedCodonFrameTest.testGetMappedCodons | 1PASS | ||
|
0.007874016
|
jalview.analysis.ConservationTest.testVerdictjalview.analysis.ConservationTest.testVerdict | 1PASS | ||
|
0.007874016
|
jalview.analysis.AlignmentUtilsTests.testAlignSequenceAs_withMapping_withIntronsjalview.analysis.AlignmentUtilsTests.testAlignSequenceAs_withMapping_withIntrons | 1PASS | ||
|
0.007874016
|
jalview.commands.EditCommandTest.testPriorState_singleInsertjalview.commands.EditCommandTest.testPriorState_singleInsert | 1PASS | ||
|
0.007874016
|
jalview.util.StringUtilsTest.testInsertCharAtjalview.util.StringUtilsTest.testInsertCharAt | 1PASS | ||
|
0.007874016
|
jalview.datamodel.SequenceTest.testFindPosition_withCursorjalview.datamodel.SequenceTest.testFindPosition_withCursor | 1PASS | ||
|
0.007874016
|
jalview.commands.EditCommandTest.testCutjalview.commands.EditCommandTest.testCut | 1PASS | ||
|
0.007874016
|
jalview.schemes.AnnotationColourGradientTest.testFindColour_belowThresholdjalview.schemes.AnnotationColourGradientTest.testFindColour_belowThreshold | 1PASS | ||
|
0.007874016
|
jalview.renderer.ContactGeometryTest.testContactGeometryjalview.renderer.ContactGeometryTest.testContactGeometry | 1PASS | ||
|
0.007874016
|
jalview.ext.htsjdk.TestHtsContigDb.testGetSequenceProxyjalview.ext.htsjdk.TestHtsContigDb.testGetSequenceProxy | 1PASS | ||
|
0.007874016
|
jalview.commands.TrimRegionCommandTest.testTrimRight_withUndoAndRedojalview.commands.TrimRegionCommandTest.testTrimRight_withUndoAndRedo | 1PASS | ||
|
0.007874016
|
jalview.datamodel.SequenceTest.testGetCharAtjalview.datamodel.SequenceTest.testGetCharAt | 1PASS | ||
|
0.007874016
|
jalview.commands.EditCommandTest.testUndo_cutjalview.commands.EditCommandTest.testUndo_cut | 1PASS | ||
|
0.007874016
|
jalview.ext.ensembl.EnsemblGeneTest.testGetIdentifyingFeaturesjalview.ext.ensembl.EnsemblGeneTest.testGetIdentifyingFeatures | 1PASS | ||
|
0.007874016
|
jalview.commands.EditCommandTest.testAddEdit_multipleInsertGapjalview.commands.EditCommandTest.testAddEdit_multipleInsertGap | 1PASS | ||
|
0.007874016
|
jalview.schemes.HelixColourSchemeTest.testFindColourjalview.schemes.HelixColourSchemeTest.testFindColour | 1PASS | ||
|
0.007874016
|
jalview.datamodel.SeqCigarTest.testFindPositionjalview.datamodel.SeqCigarTest.testFindPosition | 1PASS | ||
|
0.007874016
|
jalview.commands.EditCommandTest.testUndo_insertGapjalview.commands.EditCommandTest.testUndo_insertGap | 1PASS | ||
|
0.007874016
|
jalview.io.NewickFileTests.testTreeIOjalview.io.NewickFileTests.testTreeIO | 1PASS | ||
|
0.007874016
|
jalview.commands.EditCommandTest.testPriorState_removeAllGapsjalview.commands.EditCommandTest.testPriorState_removeAllGaps | 1PASS | ||
|
0.007874016
|
jalview.datamodel.SequenceTest.testDeleteCharsjalview.datamodel.SequenceTest.testDeleteChars | 1PASS | ||
|
0.007874016
|
jalview.analysis.AlignmentUtilsTests.testFindCdsPositionsjalview.analysis.AlignmentUtilsTests.testFindCdsPositions | 1PASS | ||
|
0.007874016
|
jalview.commands.EditCommandTest.testPriorState_multipleInsertsjalview.commands.EditCommandTest.testPriorState_multipleInserts | 1PASS | ||
|
0.007874016
|
jalview.io.SequenceAnnotationReportTest.testCreateSequenceAnnotationReportjalview.io.SequenceAnnotationReportTest.testCreateSequenceAnnotationReport | 1PASS | ||
|
0.007874016
|
jalview.ext.ensembl.EnsemblCdnaTest.testGetGenomicRangesFromFeatures_mixedStrandjalview.ext.ensembl.EnsemblCdnaTest.testGetGenomicRangesFromFeatures_mixedStrand | 1PASS | ||
|
0.007874016
|
jalview.renderer.seqfeatures.FeatureColourFinderTest.testFindFeatureColour_transparencyTwoFeaturesjalview.renderer.seqfeatures.FeatureColourFinderTest.testFindFeatureColour_transparencyTwoFeatures | 1PASS | ||
|
0.007874016
|
jalview.gui.SeqPanelTest.testGetEditStatusMessagejalview.gui.SeqPanelTest.testGetEditStatusMessage | 1PASS | ||
|
0.007874016
|
jalview.datamodel.AlignedCodonIteratorTest.testNextjalview.datamodel.AlignedCodonIteratorTest.testNext | 1PASS | ||
|
0.007874016
|
jalview.datamodel.MappedFeaturesTest.testFindProteinVariantsjalview.datamodel.MappedFeaturesTest.testFindProteinVariants | 1PASS | ||
|
0.007874016
|
mc_view.PDBfileTest.testIsRnamc_view.PDBfileTest.testIsRna | 1PASS | ||
|
0.007874016
|
jalview.renderer.seqfeatures.FeatureColourFinderTest.testFindFeatureColour_singleFeatureAtPositionjalview.renderer.seqfeatures.FeatureColourFinderTest.testFindFeatureColour_singleFeatureAtPosition | 1PASS | ||
|
0.007874016
|
jalview.commands.EditCommandTest.testUndo_deleteGapjalview.commands.EditCommandTest.testUndo_deleteGap | 1PASS | ||
|
0.007874016
|
jalview.util.StringUtilsTest.testParseIntjalview.util.StringUtilsTest.testParseInt | 1PASS | ||
|
0.007874016
|
jalview.datamodel.SequenceTest.testDeleteChars_withGapsjalview.datamodel.SequenceTest.testDeleteChars_withGaps | 1PASS | ||
|
0.007874016
|
jalview.ext.ensembl.EnsemblCdsTest.testGetIdentifyingFeaturesjalview.ext.ensembl.EnsemblCdsTest.testGetIdentifyingFeatures | 1PASS | ||
|
0.007874016
|
jalview.analysis.AlignmentUtilsTests.testMapCdsToProteinjalview.analysis.AlignmentUtilsTests.testMapCdsToProtein | 1PASS | ||
|
0.007874016
|
jalview.analysis.AlignSeqTest.testGlobalAlignmentjalview.analysis.AlignSeqTest.testGlobalAlignment | 1PASS | ||
|
0.007874016
|
jalview.analysis.AlignmentUtilsTests.testFindCdsForProteinjalview.analysis.AlignmentUtilsTests.testFindCdsForProtein | 1PASS | ||
|
0.007874016
|
jalview.datamodel.AlignmentAnnotationTests.testCopyConstructorjalview.datamodel.AlignmentAnnotationTests.testCopyConstructor | 1PASS | ||
|
0.007874016
|
jalview.datamodel.SequenceTest.testGapBitsetjalview.datamodel.SequenceTest.testGapBitset | 1PASS | ||
|
0.007874016
|
jalview.gui.AnnotationLabelsTest.testGetTooltipjalview.gui.AnnotationLabelsTest.testGetTooltip | 1PASS | ||
|
0.007874016
|
jalview.datamodel.AlignedCodonIteratorTest.testNext_unmappedPeptidejalview.datamodel.AlignedCodonIteratorTest.testNext_unmappedPeptide | 1PASS | ||
|
0.007874016
|
jalview.analysis.FinderTest.testFind_withHiddenColumnsjalview.analysis.FinderTest.testFind_withHiddenColumns | 1PASS | ||
|
0.007874016
|
jalview.analysis.AlignmentUtilsTests.testTransferFeatures_withSelectjalview.analysis.AlignmentUtilsTests.testTransferFeatures_withSelect | 1PASS | ||
|
0.007874016
|
jalview.gui.structurechooser.StructureChooserQuerySourceTest.testUpSeqsjalview.gui.structurechooser.StructureChooserQuerySourceTest.testUpSeqs | 1PASS | ||
|
0.007874016
|
jalview.commands.EditCommandTest.testReplacejalview.commands.EditCommandTest.testReplace | 1PASS | ||
|
0.007874016
|
jalview.ws.dbsources.UniprotTest.testimportOfProblemEntriesjalview.ws.dbsources.UniprotTest.testimportOfProblemEntries | 1PASS | ||
|
0.007874016
|
jalview.gui.SequenceRendererTest.testGetResidueColour_WithGroupjalview.gui.SequenceRendererTest.testGetResidueColour_WithGroup | 1PASS | ||
|
0.007874016
|
jalview.analysis.AlignmentUtilsTests.testAddMappedPositions_withStopCodonjalview.analysis.AlignmentUtilsTests.testAddMappedPositions_withStopCodon | 1PASS | ||
|
0.007874016
|
jalview.datamodel.SearchResultsTest.testEquals_distinctSequencesjalview.datamodel.SearchResultsTest.testEquals_distinctSequences | 1PASS | ||
|
0.007874016
|
jalview.project.Jalview2xmlTests.testMatrixToFloatsAndBackjalview.project.Jalview2xmlTests.testMatrixToFloatsAndBack | 1PASS | ||
|
0.007874016
|
jalview.datamodel.ResidueCountTest.test_countNucleotidejalview.datamodel.ResidueCountTest.test_countNucleotide | 1PASS | ||
|
0.007874016
|
jalview.analysis.FinderTest.testFind_withHiddenColumnsAndSelectionjalview.analysis.FinderTest.testFind_withHiddenColumnsAndSelection | 1PASS | ||
|
0.007874016
|
jalview.datamodel.MatchTest.testEqualsjalview.datamodel.MatchTest.testEquals | 1PASS | ||
|
0.007874016
|
jalview.datamodel.AlignedCodonIteratorTest.testNext_incompleteCodonjalview.datamodel.AlignedCodonIteratorTest.testNext_incompleteCodon | 1PASS | ||
|
0.007874016
|
jalview.renderer.seqfeatures.FeatureColourFinderTest.testFindFeatureColour_featureTypeNotDisplayedjalview.renderer.seqfeatures.FeatureColourFinderTest.testFindFeatureColour_featureTypeNotDisplayed | 1PASS | ||
|
0.007874016
|
jalview.analysis.AlignmentUtilsTests.testAlignSequenceAs_mappedProteinProteinjalview.analysis.AlignmentUtilsTests.testAlignSequenceAs_mappedProteinProtein | 1PASS | ||
|
0.007874016
|
jalview.datamodel.SequenceTest.testCopyPasteStyleDerivesequence_withcontactMatrixAnnjalview.datamodel.SequenceTest.testCopyPasteStyleDerivesequence_withcontactMatrixAnn | 1PASS | ||
|
0.007874016
|
jalview.datamodel.SearchResultsTest.testEquals_orderDiffersjalview.datamodel.SearchResultsTest.testEquals_orderDiffers | 1PASS | ||
|
0.007874016
|
jalview.util.StringUtilsTest.testUrlEncodejalview.util.StringUtilsTest.testUrlEncode | 1PASS | ||
|
0.007874016
|
jalview.ext.ensembl.EnsemblCdnaTest.testGetIdentifyingFeaturesjalview.ext.ensembl.EnsemblCdnaTest.testGetIdentifyingFeatures | 1PASS | ||
|
0.007874016
|
jalview.analysis.AlignmentUtilsTests.testTransferFeaturesjalview.analysis.AlignmentUtilsTests.testTransferFeatures | 1PASS | ||
|
0.007874016
|
jalview.datamodel.ResidueCountTest.test_unexpectedNucleotidejalview.datamodel.ResidueCountTest.test_unexpectedNucleotide | 1PASS | ||
|
0.007874016
|
jalview.datamodel.ResidueCountTest.test_countPeptidejalview.datamodel.ResidueCountTest.test_countPeptide | 1PASS | ||
|
0.007874016
|
jalview.schemes.PIDColourSchemeTest.testFindColourjalview.schemes.PIDColourSchemeTest.testFindColour | 1PASS | ||
|
0.007874016
|
jalview.renderer.ResidueShaderTest.testApplyConservationjalview.renderer.ResidueShaderTest.testApplyConservation | 1PASS | ||
|
0.007874016
|
jalview.ws.dbsources.EBIAlphaFoldTest.checkPAEimportjalview.ws.dbsources.EBIAlphaFoldTest.checkPAEimport | 1PASS | ||
|
0.007874016
|
jalview.analysis.AlignmentUtilsTests.testFindCdsPositions_fivePrimeIncompletejalview.analysis.AlignmentUtilsTests.testFindCdsPositions_fivePrimeIncomplete | 1PASS | ||
|
0.007874016
|
jalview.analysis.ParsePropertiesTest.testGetScoresFromDescription_wordBoundariesjalview.analysis.ParsePropertiesTest.testGetScoresFromDescription_wordBoundaries | 1PASS | ||
|
0.007874016
|
jalview.commands.EditCommandTest.testAddEdit_removeAllGapsjalview.commands.EditCommandTest.testAddEdit_removeAllGaps | 1PASS | ||
|
0.007874016
|
jalview.renderer.seqfeatures.FeatureColourFinderTest.testFindFeatureColour_singleFeatureNotAtPositionjalview.renderer.seqfeatures.FeatureColourFinderTest.testFindFeatureColour_singleFeatureNotAtPosition | 1PASS | ||
|
0.007874016
|
jalview.schemes.AnnotationColourGradientTest.testFindColour_originalColoursjalview.schemes.AnnotationColourGradientTest.testFindColour_originalColours | 1PASS | ||
|
0.007874016
|
jalview.datamodel.SequenceGroupTest.testCopyConstructorjalview.datamodel.SequenceGroupTest.testCopyConstructor | 1PASS | ||
|
0.007874016
|
jalview.schemes.AnnotationColourGradientTest.testFindColour_noThresholdjalview.schemes.AnnotationColourGradientTest.testFindColour_noThreshold | 1PASS | ||
|
0.007874016
|
jalview.util.UrlLinkTest.testCreateLinksFromSequencejalview.util.UrlLinkTest.testCreateLinksFromSequence | 1PASS | ||
|
0.007874016
|
jalview.ws.dbsources.EBIAlphaFoldTest.checkPAEimportjalview.ws.dbsources.EBIAlphaFoldTest.checkPAEimport | 1PASS | ||
|
0.007874016
|
jalview.util.StringUtilsTest.testUrlDecodejalview.util.StringUtilsTest.testUrlDecode | 1PASS | ||
|
0.007874016
|
jalview.datamodel.SequenceTest.testGetSequencejalview.datamodel.SequenceTest.testGetSequence | 1PASS | ||
|
0.007874016
|
jalview.gui.SeqPanelTest.testGetEditStatusMessage_lockedEditingjalview.gui.SeqPanelTest.testGetEditStatusMessage_lockedEditing | 1PASS | ||
|
0.007874016
|
jalview.analysis.ConservationTest.testCalculate_thresholdjalview.analysis.ConservationTest.testCalculate_threshold | 1PASS | ||
|
0.007874016
|
jalview.analysis.TestAlignSeq.testGetMappingForS1_withLowerCasejalview.analysis.TestAlignSeq.testGetMappingForS1_withLowerCase | 1PASS | ||
|
0.007874016
|
jalview.io.ClustalFileTest.testParse_withNumberingjalview.io.ClustalFileTest.testParse_withNumbering | 1PASS | ||
|
0.007874016
|
jalview.datamodel.SequenceTest.testGetSubsequencejalview.datamodel.SequenceTest.testGetSubsequence | 1PASS | ||
|
0.007874016
|
jalview.commands.EditCommandTest.testAddEdit_multipleDeleteGapjalview.commands.EditCommandTest.testAddEdit_multipleDeleteGap | 1PASS | ||
|
0.007874016
|
jalview.ext.ensembl.EnsemblCdnaTest.testGetGenomicRangesFromFeaturesjalview.ext.ensembl.EnsemblCdnaTest.testGetGenomicRangesFromFeatures | 1PASS | ||
|
0.007874016
|
jalview.datamodel.AlignedCodonFrameTest.testCouldReplaceSequencejalview.datamodel.AlignedCodonFrameTest.testCouldReplaceSequence | 1PASS | ||
|
0.007874016
|
jalview.datamodel.ResidueCountTest.testGetResiduesForCountjalview.datamodel.ResidueCountTest.testGetResiduesForCount | 1PASS | ||
|
0.007874016
|
jalview.structures.models.AAStructureBindingModelTest.testFindSuperposableResiduesjalview.structures.models.AAStructureBindingModelTest.testFindSuperposableResidues | 1PASS | ||
|
0.007874016
|
jalview.datamodel.SequenceTest.testCreateDatasetSequencejalview.datamodel.SequenceTest.testCreateDatasetSequence | 1PASS | ||
|
0.007874016
|
jalview.analysis.FinderTest.testFindAll_inSelectionjalview.analysis.FinderTest.testFindAll_inSelection | 1PASS | ||
|
0.007874016
|
jalview.datamodel.AlignedCodonFrameTest.testGetCoveringCodonMappingjalview.datamodel.AlignedCodonFrameTest.testGetCoveringCodonMapping | 1PASS | ||
|
0.007874016
|
jalview.ext.ensembl.EnsemblCdnaTest.testGetGenomicRangesFromFeatures_reverseStrandjalview.ext.ensembl.EnsemblCdnaTest.testGetGenomicRangesFromFeatures_reverseStrand | 1PASS | ||
|
0.007874016
|
jalview.analysis.AlignSeqTest.testIndexEncode_nucleotidejalview.analysis.AlignSeqTest.testIndexEncode_nucleotide | 1PASS | ||
|
0.007874016
|
mc_view.PDBChainTest.testMakeCaBondListmc_view.PDBChainTest.testMakeCaBondList | 1PASS | ||
|
0.007874016
|
jalview.util.MapListTest.testTraversejalview.util.MapListTest.testTraverse | 1PASS | ||
|
0.007874016
|
jalview.datamodel.AlignedCodonIteratorTest.testNext_withOffsetjalview.datamodel.AlignedCodonIteratorTest.testNext_withOffset | 1PASS | ||
|
0.007874016
|
jalview.analysis.AlignmentUtilsTests.testMapCdnaToProtein_forSubsequencejalview.analysis.AlignmentUtilsTests.testMapCdnaToProtein_forSubsequence | 1PASS | ||
|
0.007874016
|
jalview.analysis.AlignSeqTest.testIndexEncode_peptidejalview.analysis.AlignSeqTest.testIndexEncode_peptide | 1PASS | ||
|
0.007874016
|
jalview.datamodel.SearchResultsTest.testAppendResultjalview.datamodel.SearchResultsTest.testAppendResult | 1PASS | ||
|
0.007874016
|
jalview.analysis.AlignmentUtilsTests.testTransferFeatures_withOmitjalview.analysis.AlignmentUtilsTests.testTransferFeatures_withOmit | 1PASS | ||
|
0.007874016
|
jalview.datamodel.ResidueCountTest.testGetSymbolCounts_peptidejalview.datamodel.ResidueCountTest.testGetSymbolCounts_peptide | 1PASS | ||
|
0.007874016
|
jalview.analysis.DnaTest.testReverseSequencejalview.analysis.DnaTest.testReverseSequence | 1PASS | ||
|
0.007874016
|
jalview.renderer.seqfeatures.FeatureColourFinderTest.testFindFeatureColour_contactFeaturejalview.renderer.seqfeatures.FeatureColourFinderTest.testFindFeatureColour_contactFeature | 1PASS | ||
|
0.007874016
|
jalview.ext.ensembl.EnsemblGenomeTest.testGetGenomicRangesFromFeaturesjalview.ext.ensembl.EnsemblGenomeTest.testGetGenomicRangesFromFeatures | 1PASS | ||
|
0.007874016
|
jalview.gui.SeqCanvasTest.testClear_HighlightAndSelectionjalview.gui.SeqCanvasTest.testClear_HighlightAndSelection | 1PASS | ||
|
0.007874016
|
jalview.analysis.AlignmentUtilsTests.testTransferGeneLocijalview.analysis.AlignmentUtilsTests.testTransferGeneLoci | 1PASS | ||
|
0.007874016
|
jalview.renderer.seqfeatures.FeatureColourFinderTest.testFindFeatureColour_featureGroupNotDisplayedjalview.renderer.seqfeatures.FeatureColourFinderTest.testFindFeatureColour_featureGroupNotDisplayed | 1PASS | ||
|
0.007874016
|
jalview.datamodel.AlignedCodonFrameTest.testGetMappedCodons_forSubSequencesjalview.datamodel.AlignedCodonFrameTest.testGetMappedCodons_forSubSequences | 1PASS | ||
|
0.007874016
|
jalview.datamodel.AlignedCodonFrameTest.testAddMapjalview.datamodel.AlignedCodonFrameTest.testAddMap | 1PASS | ||
|
0.007874016
|
jalview.datamodel.SequenceTest.testDeleteChars_withDbRefsAndFeaturesjalview.datamodel.SequenceTest.testDeleteChars_withDbRefsAndFeatures | 1PASS | ||
|
0.007874016
|
jalview.util.DBRefUtilsTest.testParseToDbRef_PDBjalview.util.DBRefUtilsTest.testParseToDbRef_PDB | 1PASS | ||
|
0.007874016
|
jalview.schemes.Blosum62ColourSchemeTest.testFindColourjalview.schemes.Blosum62ColourSchemeTest.testFindColour | 1PASS | ||
|
0.007874016
|
jalview.datamodel.SearchResultsTest.testInvolvesSequencejalview.datamodel.SearchResultsTest.testInvolvesSequence | 1PASS | ||
|
0.007874016
|
jalview.datamodel.AlignedCodonFrameTest.testGetMappedRegionjalview.datamodel.AlignedCodonFrameTest.testGetMappedRegion | 1PASS | ||
|
0.007874016
|
jalview.datamodel.SequenceGroupTest.testAddOrRemovejalview.datamodel.SequenceGroupTest.testAddOrRemove | 1PASS | ||
|
0.007874016
|
jalview.renderer.seqfeatures.FeatureColourFinderTest.testFindFeatureColour_gapPositionjalview.renderer.seqfeatures.FeatureColourFinderTest.testFindFeatureColour_gapPosition | 1PASS | ||
|
0.007874016
|
jalview.datamodel.ResidueCountTest.testGetModalCountjalview.datamodel.ResidueCountTest.testGetModalCount | 1PASS | ||
|
0.007874016
|
jalview.commands.EditCommandTest.testPriorState_singleInsertWithOffsetjalview.commands.EditCommandTest.testPriorState_singleInsertWithOffset | 1PASS | ||
|
0.007874016
|
jalview.datamodel.SequenceTest.testCopyConstructor_noDatasetjalview.datamodel.SequenceTest.testCopyConstructor_noDataset | 1PASS | ||
|
0.007874016
|
jalview.analysis.AlignmentUtilsTests.testHaveCrossRefjalview.analysis.AlignmentUtilsTests.testHaveCrossRef | 1PASS | ||
|
0.007874016
|
jalview.analysis.AlignmentUtilsTests.testAlignSequenceAs_withTrailingPeptidejalview.analysis.AlignmentUtilsTests.testAlignSequenceAs_withTrailingPeptide | 1PASS | ||
|
0.007874016
|
jalview.datamodel.SequenceTest.testCopyConstructor_withDatasetjalview.datamodel.SequenceTest.testCopyConstructor_withDataset | 1PASS | ||
|
0.007874016
|
jalview.analysis.ConservationTest.testCalculate_noThresholdjalview.analysis.ConservationTest.testCalculate_noThreshold | 1PASS | ||
|
0.007874016
|
jalview.datamodel.SequenceTest.testDeriveSequence_noDatasetGappedjalview.datamodel.SequenceTest.testDeriveSequence_noDatasetGapped | 1PASS | ||
|
0.007874016
|
jalview.analysis.AlignmentUtilsTests.testFindCdsForProtein_noUTRjalview.analysis.AlignmentUtilsTests.testFindCdsForProtein_noUTR | 1PASS | ||
|
0.007874016
|
jalview.datamodel.SequenceTest.testFindIndex_withCursorjalview.datamodel.SequenceTest.testFindIndex_withCursor | 1PASS | ||
|
0.007874016
|
jalview.io.ClustalFileTest.testParse_noNumberingjalview.io.ClustalFileTest.testParse_noNumbering | 1PASS | ||
|
0.007874016
|
jalview.analysis.FinderTest.testFind_featuresOnlyjalview.analysis.FinderTest.testFind_featuresOnly | 1PASS | ||
|
0.007874016
|
jalview.ext.ensembl.EnsemblGeneTest.testGetGenomicRangesFromFeaturesjalview.ext.ensembl.EnsemblGeneTest.testGetGenomicRangesFromFeatures | 1PASS | ||
|
0.007874016
|
jalview.util.MapListTest.testLocateInTo_noIntronsjalview.util.MapListTest.testLocateInTo_noIntrons | 1PASS | ||
|
0.007874016
|
jalview.datamodel.SearchResultsTest.testAddResultjalview.datamodel.SearchResultsTest.testAddResult | 1PASS | ||
|
0.007874016
|
jalview.util.MappingUtilsTest.testFindMappingsForSequenceAndOthersjalview.util.MappingUtilsTest.testFindMappingsForSequenceAndOthers | 1PASS | ||
|
0.007874016
|
jalview.datamodel.MappingTest.testCopyConstructorjalview.datamodel.MappingTest.testCopyConstructor | 1PASS | ||
|
0.007874016
|
jalview.datamodel.ResidueCountTest.testPutjalview.datamodel.ResidueCountTest.testPut | 1PASS | ||
|
0.007874016
|
jalview.analysis.FinderTest.testFind_findAllInSelectionWithShortSequencejalview.analysis.FinderTest.testFind_findAllInSelectionWithShortSequence | 1PASS | ||
|
0.007874016
|
jalview.datamodel.SequenceTest.testFindFeaturesjalview.datamodel.SequenceTest.testFindFeatures | 1PASS | ||
|
0.007874016
|
jalview.datamodel.ResidueCountTest.testGetSymbolCounts_nucleotidejalview.datamodel.ResidueCountTest.testGetSymbolCounts_nucleotide | 1PASS | ||
|
0.007874016
|
jalview.analysis.FinderTest.testFind_regexjalview.analysis.FinderTest.testFind_regex | 1PASS |
Source view
| 1 | /* | ||||||
| 2 | * Jalview - A Sequence Alignment Editor and Viewer ($$Version-Rel$$) | ||||||
| 3 | * Copyright (C) $$Year-Rel$$ The Jalview Authors | ||||||
| 4 | * | ||||||
| 5 | * This file is part of Jalview. | ||||||
| 6 | * | ||||||
| 7 | * Jalview is free software: you can redistribute it and/or | ||||||
| 8 | * modify it under the terms of the GNU General Public License | ||||||
| 9 | * as published by the Free Software Foundation, either version 3 | ||||||
| 10 | * of the License, or (at your option) any later version. | ||||||
| 11 | * | ||||||
| 12 | * Jalview is distributed in the hope that it will be useful, but | ||||||
| 13 | * WITHOUT ANY WARRANTY; without even the implied warranty | ||||||
| 14 | * of MERCHANTABILITY or FITNESS FOR A PARTICULAR | ||||||
| 15 | * PURPOSE. See the GNU General Public License for more details. | ||||||
| 16 | * | ||||||
| 17 | * You should have received a copy of the GNU General Public License | ||||||
| 18 | * along with Jalview. If not, see <http://www.gnu.org/licenses/>. | ||||||
| 19 | * The Jalview Authors are detailed in the 'AUTHORS' file. | ||||||
| 20 | */ | ||||||
| 21 | package jalview.util; | ||||||
| 22 | |||||||
| 23 | import java.util.ArrayList; | ||||||
| 24 | import java.util.List; | ||||||
| 25 | |||||||
| 26 | import jalview.bin.Cache; | ||||||
| 27 | import jalview.bin.Console; | ||||||
| 28 | import jalview.datamodel.SequenceI; | ||||||
| 29 | |||||||
| 30 | /** | ||||||
| 31 | * Assorted methods for analysing or comparing sequences. | ||||||
| 32 | */ | ||||||
|
|||||||
| 33 | public class Comparison | ||||||
| 34 | { | ||||||
| 35 | private static final int EIGHTY_FIVE = 85; | ||||||
| 36 | |||||||
| 37 | private static final int NUCLEOTIDE_COUNT_PERCENT; | ||||||
| 38 | |||||||
| 39 | private static final int NUCLEOTIDE_COUNT_LONG_SEQUENCE_AMBIGUITY_PERCENT; | ||||||
| 40 | |||||||
| 41 | private static final int NUCLEOTIDE_COUNT_SHORT_SEQUENCE; | ||||||
| 42 | |||||||
| 43 | private static final int NUCLEOTIDE_COUNT_VERY_SHORT_SEQUENCE; | ||||||
| 44 | |||||||
| 45 | private static final boolean NUCLEOTIDE_AMBIGUITY_DETECTION; | ||||||
| 46 | |||||||
| 47 | public static final char GAP_SPACE = ' '; | ||||||
| 48 | |||||||
| 49 | public static final char GAP_DOT = '.'; | ||||||
| 50 | |||||||
| 51 | public static final char GAP_DASH = '-'; | ||||||
| 52 | |||||||
| 53 | public static final String GapChars = new String( | ||||||
| 54 | new char[] | ||||||
| 55 | { GAP_SPACE, GAP_DOT, GAP_DASH }); | ||||||
| 56 | |||||||
|
|||||||
| 57 | 54 |  static... static... |
|||||
| 58 | { | ||||||
| 59 | // these options read only at start of session | ||||||
| 60 | 54 | NUCLEOTIDE_COUNT_PERCENT = Cache.getDefault("NUCLEOTIDE_COUNT_PERCENT", | |||||
| 61 | 55); | ||||||
| 62 | 54 | NUCLEOTIDE_COUNT_LONG_SEQUENCE_AMBIGUITY_PERCENT = Cache.getDefault( | |||||
| 63 | "NUCLEOTIDE_COUNT_LONG_SEQUENCE_AMBIGUITY_PERCENT", 95); | ||||||
| 64 | 54 | NUCLEOTIDE_COUNT_SHORT_SEQUENCE = Cache | |||||
| 65 | .getDefault("NUCLEOTIDE_COUNT_SHORT", 100); | ||||||
| 66 | 54 | NUCLEOTIDE_COUNT_VERY_SHORT_SEQUENCE = Cache | |||||
| 67 | .getDefault("NUCLEOTIDE_COUNT_VERY_SHORT", 4); | ||||||
| 68 | 54 | NUCLEOTIDE_AMBIGUITY_DETECTION = Cache | |||||
| 69 | .getDefault("NUCLEOTIDE_AMBIGUITY_DETECTION", true); | ||||||
| 70 | } | ||||||
| 71 | |||||||
| 72 | /** | ||||||
| 73 | * DOCUMENT ME! | ||||||
| 74 | * | ||||||
| 75 | * @param ii | ||||||
| 76 | * DOCUMENT ME! | ||||||
| 77 | * @param jj | ||||||
| 78 | * DOCUMENT ME! | ||||||
| 79 | * | ||||||
| 80 | * @return DOCUMENT ME! | ||||||
| 81 | */ | ||||||
|
|||||||
| 82 | 0 | public static final float compare(SequenceI ii, SequenceI jj)... |
|||||
| 83 | { | ||||||
| 84 | 0 | return Comparison.compare(ii, jj, 0, ii.getLength() - 1); | |||||
| 85 | } | ||||||
| 86 | |||||||
| 87 | /** | ||||||
| 88 | * this was supposed to be an ungapped pid calculation | ||||||
| 89 | * | ||||||
| 90 | * @param ii | ||||||
| 91 | * SequenceI | ||||||
| 92 | * @param jj | ||||||
| 93 | * SequenceI | ||||||
| 94 | * @param start | ||||||
| 95 | * int | ||||||
| 96 | * @param end | ||||||
| 97 | * int | ||||||
| 98 | * @return float | ||||||
| 99 | */ | ||||||
|
|||||||
| 100 | 0 | public static float compare(SequenceI ii, SequenceI jj, int start,... |
|||||
| 101 | int end) | ||||||
| 102 | { | ||||||
| 103 | 0 | String si = ii.getSequenceAsString(); | |||||
| 104 | 0 | String sj = jj.getSequenceAsString(); | |||||
| 105 | |||||||
| 106 | 0 | int ilen = si.length() - 1; | |||||
| 107 | 0 | int jlen = sj.length() - 1; | |||||
| 108 | |||||||
| 109 | 0 | while (Comparison.isGap(si.charAt(start + ilen))) | |||||
| 110 | { | ||||||
| 111 | 0 | ilen--; | |||||
| 112 | } | ||||||
| 113 | |||||||
| 114 | 0 | while (Comparison.isGap(sj.charAt(start + jlen))) | |||||
| 115 | { | ||||||
| 116 | 0 | jlen--; | |||||
| 117 | } | ||||||
| 118 | |||||||
| 119 | 0 | int match = 0; | |||||
| 120 | 0 | float pid = -1; | |||||
| 121 | |||||||
| 122 | 0 | if (ilen > jlen) | |||||
| 123 | { | ||||||
| 124 | 0 | for (int j = 0; j < jlen; j++) | |||||
| 125 | { | ||||||
| 126 | 0 | if (si.substring(start + j, start + j + 1) | |||||
| 127 | .equals(sj.substring(start + j, start + j + 1))) | ||||||
| 128 | { | ||||||
| 129 | 0 | match++; | |||||
| 130 | } | ||||||
| 131 | } | ||||||
| 132 | |||||||
| 133 | 0 | pid = (float) match / (float) ilen * 100; | |||||
| 134 | } | ||||||
| 135 | else | ||||||
| 136 | { | ||||||
| 137 | 0 | for (int j = 0; j < jlen; j++) | |||||
| 138 | { | ||||||
| 139 | 0 | if (si.substring(start + j, start + j + 1) | |||||
| 140 | .equals(sj.substring(start + j, start + j + 1))) | ||||||
| 141 | { | ||||||
| 142 | 0 | match++; | |||||
| 143 | } | ||||||
| 144 | } | ||||||
| 145 | |||||||
| 146 | 0 | pid = (float) match / (float) jlen * 100; | |||||
| 147 | } | ||||||
| 148 | |||||||
| 149 | 0 | return pid; | |||||
| 150 | } | ||||||
| 151 | |||||||
| 152 | /** | ||||||
| 153 | * this is a gapped PID calculation | ||||||
| 154 | * | ||||||
| 155 | * @param s1 | ||||||
| 156 | * SequenceI | ||||||
| 157 | * @param s2 | ||||||
| 158 | * SequenceI | ||||||
| 159 | * @return float | ||||||
| 160 | * @deprecated use PIDModel.computePID() | ||||||
| 161 | */ | ||||||
|
|||||||
| 162 | 8 | @Deprecated... |
|||||
| 163 | public final static float PID(String seq1, String seq2) | ||||||
| 164 | { | ||||||
| 165 | 8 | return PID(seq1, seq2, 0, seq1.length()); | |||||
| 166 | } | ||||||
| 167 | |||||||
| 168 | static final int caseShift = 'a' - 'A'; | ||||||
| 169 | |||||||
| 170 | // Another pid with region specification | ||||||
| 171 | /** | ||||||
| 172 | * @deprecated use PIDModel.computePID() | ||||||
| 173 | */ | ||||||
|
|||||||
| 174 | 8 | @Deprecated... |
|||||
| 175 | public final static float PID(String seq1, String seq2, int start, | ||||||
| 176 | int end) | ||||||
| 177 | { | ||||||
| 178 | 8 | return PID(seq1, seq2, start, end, true, false); | |||||
| 179 | } | ||||||
| 180 | |||||||
| 181 | /** | ||||||
| 182 | * Calculate percent identity for a pair of sequences over a particular range, | ||||||
| 183 | * with different options for ignoring gaps. | ||||||
| 184 | * | ||||||
| 185 | * @param seq1 | ||||||
| 186 | * @param seq2 | ||||||
| 187 | * @param start | ||||||
| 188 | * - position in seqs | ||||||
| 189 | * @param end | ||||||
| 190 | * - position in seqs | ||||||
| 191 | * @param wcGaps | ||||||
| 192 | * - if true - gaps match any character, if false, do not match | ||||||
| 193 | * anything | ||||||
| 194 | * @param ungappedOnly | ||||||
| 195 | * - if true - only count PID over ungapped columns | ||||||
| 196 | * @return | ||||||
| 197 | * @deprecated use PIDModel.computePID() | ||||||
| 198 | */ | ||||||
|
|||||||
| 199 | 12 | @Deprecated... |
|||||
| 200 | public final static float PID(String seq1, String seq2, int start, | ||||||
| 201 | int end, boolean wcGaps, boolean ungappedOnly) | ||||||
| 202 | { | ||||||
| 203 | 12 | int s1len = seq1.length(); | |||||
| 204 | 12 | int s2len = seq2.length(); | |||||
| 205 | |||||||
| 206 | 12 | int len = Math.min(s1len, s2len); | |||||
| 207 | |||||||
| 208 | 12 | if (end < len) | |||||
| 209 | { | ||||||
| 210 | 0 | len = end; | |||||
| 211 | } | ||||||
| 212 | |||||||
| 213 | 12 | if (len < start) | |||||
| 214 | { | ||||||
| 215 | 0 | start = len - 1; // we just use a single residue for the difference | |||||
| 216 | } | ||||||
| 217 | |||||||
| 218 | 12 | int elen = len - start, bad = 0; | |||||
| 219 | 12 | char chr1; | |||||
| 220 | 12 | char chr2; | |||||
| 221 | 12 | boolean agap; | |||||
| 222 | 109 | for (int i = start; i < len; i++) | |||||
| 223 | { | ||||||
| 224 | 97 | chr1 = seq1.charAt(i); | |||||
| 225 | |||||||
| 226 | 97 | chr2 = seq2.charAt(i); | |||||
| 227 | 97 | agap = isGap(chr1) || isGap(chr2); | |||||
| 228 | 97 | if ('a' <= chr1 && chr1 <= 'z') | |||||
| 229 | { | ||||||
| 230 | // TO UPPERCASE !!! | ||||||
| 231 | // Faster than toUpperCase | ||||||
| 232 | 35 | chr1 -= caseShift; | |||||
| 233 | } | ||||||
| 234 | 97 | if ('a' <= chr2 && chr2 <= 'z') | |||||
| 235 | { | ||||||
| 236 | // TO UPPERCASE !!! | ||||||
| 237 | // Faster than toUpperCase | ||||||
| 238 | 48 | chr2 -= caseShift; | |||||
| 239 | } | ||||||
| 240 | |||||||
| 241 | 97 | if (chr1 != chr2) | |||||
| 242 | { | ||||||
| 243 | 30 | if (agap) | |||||
| 244 | { | ||||||
| 245 | 18 | if (ungappedOnly) | |||||
| 246 | { | ||||||
| 247 | 4 | elen--; | |||||
| 248 | } | ||||||
| 249 | 14 | else if (!wcGaps) | |||||
| 250 | { | ||||||
| 251 | 2 | bad++; | |||||
| 252 | } | ||||||
| 253 | } | ||||||
| 254 | else | ||||||
| 255 | { | ||||||
| 256 | 12 | bad++; | |||||
| 257 | } | ||||||
| 258 | } | ||||||
| 259 | |||||||
| 260 | } | ||||||
| 261 | 12 | if (elen < 1) | |||||
| 262 | { | ||||||
| 263 | 0 | return 0f; | |||||
| 264 | } | ||||||
| 265 | 12 | return ((float) 100 * (elen - bad)) / elen; | |||||
| 266 | } | ||||||
| 267 | |||||||
| 268 | /** | ||||||
| 269 | * Answers true if the supplied character is a recognised gap character, else | ||||||
| 270 | * false. Currently hard-coded to recognise '-', '-' or ' ' (hyphen / dot / | ||||||
| 271 | * space). | ||||||
| 272 | * | ||||||
| 273 | * @param c | ||||||
| 274 | * | ||||||
| 275 | * @return | ||||||
| 276 | */ | ||||||
|
|||||||
| 277 | 50280941 | public static final boolean isGap(char c)... |
|||||
| 278 | { | ||||||
| 279 | 50543687 | return c == GAP_DASH || c == GAP_DOT || c == GAP_SPACE; | |||||
| 280 | } | ||||||
| 281 | |||||||
| 282 | /** | ||||||
| 283 | * Overloaded method signature to test whether a single sequence is nucleotide | ||||||
| 284 | * (that is, more than 85% CGTAUNX) | ||||||
| 285 | * | ||||||
| 286 | * @param seq | ||||||
| 287 | * @return | ||||||
| 288 | */ | ||||||
|
|||||||
| 289 | 2427 | public static final boolean isNucleotide(SequenceI seq)... |
|||||
| 290 | { | ||||||
| 291 | 2427 | if (seq == null || seq.getLength() == 0) | |||||
| 292 | { | ||||||
| 293 | 1 | return false; | |||||
| 294 | } | ||||||
| 295 | 2426 | long ntCount = 0; // nucleotide symbol count (does not include ntaCount) | |||||
| 296 | 2426 | long aaCount = 0; // non-nucleotide, non-gap symbol count (includes nCount | |||||
| 297 | // and ntaCount) | ||||||
| 298 | 2426 | long nCount = 0; // "Unknown" (N) symbol count | |||||
| 299 | 2426 | long xCount = 0; // Also used as "Unknown" (X) symbol count | |||||
| 300 | 2426 | long ntaCount = 0; // nucleotide ambiguity symbol count | |||||
| 301 | |||||||
| 302 | 2426 | int len = seq.getLength(); | |||||
| 303 | 5383191 | for (int i = 0; i < len; i++) | |||||
| 304 | { | ||||||
| 305 | 5380765 | char c = seq.getCharAt(i); | |||||
| 306 | 5380765 | if (isNucleotide(c)) | |||||
| 307 | { | ||||||
| 308 | 1015871 | ntCount++; | |||||
| 309 | } | ||||||
| 310 | 4364894 | else if (!isGap(c)) | |||||
| 311 | { | ||||||
| 312 | 79435 | aaCount++; | |||||
| 313 | 79435 | if (isN(c)) | |||||
| 314 | { | ||||||
| 315 | 2997 | nCount++; | |||||
| 316 | } | ||||||
| 317 | else | ||||||
| 318 | { | ||||||
| 319 | 76438 | if (isX(c)) | |||||
| 320 | { | ||||||
| 321 | 82 | xCount++; | |||||
| 322 | } | ||||||
| 323 | 76438 | if (isNucleotideAmbiguity(c)) | |||||
| 324 | { | ||||||
| 325 | 47089 | ntaCount++; | |||||
| 326 | } | ||||||
| 327 | } | ||||||
| 328 | } | ||||||
| 329 | } | ||||||
| 330 | 2426 | long allCount = ntCount + aaCount; | |||||
| 331 | |||||||
| 332 | 2426 | if (NUCLEOTIDE_AMBIGUITY_DETECTION) | |||||
| 333 | { | ||||||
| 334 | 2426 | Console.debug("Performing new nucleotide detection routine"); | |||||
| 335 | 2426 | if (allCount > NUCLEOTIDE_COUNT_SHORT_SEQUENCE) | |||||
| 336 | { | ||||||
| 337 | // a long sequence. | ||||||
| 338 | // check for at least 55% nucleotide, and nucleotide and ambiguity codes | ||||||
| 339 | // (including N) must make up 95% | ||||||
| 340 | 404 | return ntCount * 100 >= NUCLEOTIDE_COUNT_PERCENT * allCount | |||||
| 341 | && 100 * (ntCount + nCount | ||||||
| 342 | + ntaCount) >= NUCLEOTIDE_COUNT_LONG_SEQUENCE_AMBIGUITY_PERCENT | ||||||
| 343 | * allCount; | ||||||
| 344 | } | ||||||
| 345 | 2022 | else if (allCount > NUCLEOTIDE_COUNT_VERY_SHORT_SEQUENCE) | |||||
| 346 | { | ||||||
| 347 | // a short sequence. | ||||||
| 348 | // check if a short sequence is at least 55% nucleotide and the rest of | ||||||
| 349 | // the symbols are all X or all N | ||||||
| 350 | 1698 | if (ntCount * 100 >= NUCLEOTIDE_COUNT_PERCENT * allCount | |||||
| 351 | && (nCount == aaCount || xCount == aaCount)) | ||||||
| 352 | { | ||||||
| 353 | 850 | return true; | |||||
| 354 | } | ||||||
| 355 | |||||||
| 356 | // a short sequence. | ||||||
| 357 | // check for at least x% nucleotide and all the rest nucleotide | ||||||
| 358 | // ambiguity codes (including N), where x slides from 75% for sequences | ||||||
| 359 | // of length 4 (i.e. only one non-nucleotide) to 55% for sequences of | ||||||
| 360 | // length 100 | ||||||
| 361 | 848 | return myShortSequenceNucleotideProportionCount(ntCount, allCount) | |||||
| 362 | && nCount + ntaCount == aaCount; | ||||||
| 363 | } | ||||||
| 364 | else | ||||||
| 365 | { | ||||||
| 366 | // a very short sequence. (<4) | ||||||
| 367 | // all bases must be nucleotide | ||||||
| 368 | 324 | return ntCount > 0 && ntCount == allCount; | |||||
| 369 | } | ||||||
| 370 | } | ||||||
| 371 | else | ||||||
| 372 | { | ||||||
| 373 | 0 | Console.debug("Performing old nucleotide detection routine"); | |||||
| 374 | /* | ||||||
| 375 | * Check for nucleotide count > 85% of total count (in a form that evades | ||||||
| 376 | * int / float conversion or divide by zero). | ||||||
| 377 | */ | ||||||
| 378 | 0 | if ((ntCount + nCount) * 100 > EIGHTY_FIVE * allCount) | |||||
| 379 | { | ||||||
| 380 | 0 | return ntCount > 0; // all N is considered protein. Could use a | |||||
| 381 | // threshold here too | ||||||
| 382 | } | ||||||
| 383 | } | ||||||
| 384 | 0 | return false; | |||||
| 385 | } | ||||||
| 386 | |||||||
|
|||||||
| 387 | 858 | protected static boolean myShortSequenceNucleotideProportionCount(... |
|||||
| 388 | long ntCount, long allCount) | ||||||
| 389 | { | ||||||
| 390 | /** | ||||||
| 391 | * this method is valid only for NUCLEOTIDE_COUNT_VERY_SHORT_SEQUENCE <= | ||||||
| 392 | * allCount <= NUCLEOTIDE_COUNT_SHORT_SEQUENCE | ||||||
| 393 | */ | ||||||
| 394 | // the following is a simplified integer version of: | ||||||
| 395 | // | ||||||
| 396 | // a := allCount # the number of bases in the sequence | ||||||
| 397 | // n : = ntCount # the number of definite nucleotide bases | ||||||
| 398 | // vs := NUCLEOTIDE_COUNT_VERY_SHORT_SEQUENCE | ||||||
| 399 | // s := NUCLEOTIDE_COUNT_SHORT_SEQUENCE | ||||||
| 400 | // lp := NUCLEOTIDE_COUNT_LOWER_PERCENT | ||||||
| 401 | // vsp := 1 - (1/a) # this is the proportion of required definite | ||||||
| 402 | // nucleotides | ||||||
| 403 | // # in a VERY_SHORT Sequence (4 bases). | ||||||
| 404 | // # This should be equivalent to all but one base in the sequence. | ||||||
| 405 | // p := (a - vs)/(s - vs) # proportion of the way between | ||||||
| 406 | // # VERY_SHORT and SHORT thresholds. | ||||||
| 407 | // tp := vsp + p * (lp/100 - vsp) # the proportion of definite nucleotides | ||||||
| 408 | // # required for this length of sequence. | ||||||
| 409 | // minNt := tp * a # the minimum number of definite nucleotide bases | ||||||
| 410 | // # required for this length of sequence. | ||||||
| 411 | // | ||||||
| 412 | // We are then essentially returning: | ||||||
| 413 | // # ntCount >= 55% of allCount and the rest are all nucleotide ambiguity: | ||||||
| 414 | // ntCount >= tp * allCount && nCount + ntaCount == aaCount | ||||||
| 415 | // but without going into float/double land | ||||||
| 416 | 858 | long LHS = 100 * allCount | |||||
| 417 | * (NUCLEOTIDE_COUNT_SHORT_SEQUENCE | ||||||
| 418 | - NUCLEOTIDE_COUNT_VERY_SHORT_SEQUENCE) | ||||||
| 419 | * (ntCount - allCount + 1); | ||||||
| 420 | 858 | long RHS = allCount * (allCount - NUCLEOTIDE_COUNT_VERY_SHORT_SEQUENCE) | |||||
| 421 | * (allCount * NUCLEOTIDE_COUNT_PERCENT - 100 * allCount + 100); | ||||||
| 422 | 858 | return LHS >= RHS; | |||||
| 423 | } | ||||||
| 424 | |||||||
| 425 | /** | ||||||
| 426 | * Answers true if more than 85% of the sequence residues (ignoring gaps) are | ||||||
| 427 | * A, G, C, T or U, else false. This is just a heuristic guess and may give a | ||||||
| 428 | * wrong answer (as AGCT are also amino acid codes). | ||||||
| 429 | * | ||||||
| 430 | * @param seqs | ||||||
| 431 | * @return | ||||||
| 432 | */ | ||||||
|
|||||||
| 433 | 1841 | public static final boolean isNucleotide(SequenceI[] seqs)... |
|||||
| 434 | { | ||||||
| 435 | 1841 | if (seqs == null) | |||||
| 436 | { | ||||||
| 437 | 1 | return false; | |||||
| 438 | } | ||||||
| 439 | // true if we have seen a nucleotide sequence | ||||||
| 440 | 1840 | boolean na = false; | |||||
| 441 | 1840 | for (SequenceI seq : seqs) | |||||
| 442 | { | ||||||
| 443 | 2669 | if (seq == null) | |||||
| 444 | { | ||||||
| 445 | 0 | continue; | |||||
| 446 | } | ||||||
| 447 | 2669 | na = true; | |||||
| 448 | // TODO could possibly make an informed guess just from the first sequence | ||||||
| 449 | // to save a lengthy calculation | ||||||
| 450 | 2669 | if (seq.isProtein()) | |||||
| 451 | { | ||||||
| 452 | // if even one looks like protein, the alignment is protein | ||||||
| 453 | 1479 | return false; | |||||
| 454 | } | ||||||
| 455 | } | ||||||
| 456 | 361 | return na; | |||||
| 457 | } | ||||||
| 458 | |||||||
| 459 | /** | ||||||
| 460 | * Answers true if the character is one of aAcCgGtTuU | ||||||
| 461 | * | ||||||
| 462 | * @param c | ||||||
| 463 | * @return | ||||||
| 464 | */ | ||||||
|
|||||||
| 465 | 16035598 | public static boolean isNucleotide(char c)... |
|||||
| 466 | { | ||||||
| 467 | 16047045 | return isNucleotide(c, false); | |||||
| 468 | } | ||||||
| 469 | |||||||
| 470 | /** | ||||||
| 471 | * includeAmbiguity = true also includes Nucleotide Ambiguity codes | ||||||
| 472 | */ | ||||||
|
|||||||
| 473 | 16085176 | public static boolean isNucleotide(char c, boolean includeAmbiguity)... |
|||||
| 474 | { | ||||||
| 475 | 16100636 | char C = Character.toUpperCase(c); | |||||
| 476 | 16101557 | switch (C) | |||||
| 477 | { | ||||||
| 478 | 591625 | case 'A': | |||||
| 479 | 374349 | case 'C': | |||||
| 480 | 435548 | case 'G': | |||||
| 481 | 577425 | case 'T': | |||||
| 482 | 11379 | case 'U': | |||||
| 483 | 1989912 | return true; | |||||
| 484 | } | ||||||
| 485 | 14119766 | if (includeAmbiguity) | |||||
| 486 | { | ||||||
| 487 | 16 | boolean ambiguity = isNucleotideAmbiguity(C); | |||||
| 488 | 16 | if (ambiguity) | |||||
| 489 | 12 | return true; | |||||
| 490 | } | ||||||
| 491 | 14122973 | return false; | |||||
| 492 | } | ||||||
| 493 | |||||||
| 494 | /** | ||||||
| 495 | * Tests *only* nucleotide ambiguity codes (and not definite nucleotide codes) | ||||||
| 496 | */ | ||||||
|
|||||||
| 497 | 76454 | public static boolean isNucleotideAmbiguity(char c)... |
|||||
| 498 | { | ||||||
| 499 | 76454 | switch (Character.toUpperCase(c)) | |||||
| 500 | { | ||||||
| 501 | 5330 | case 'I': | |||||
| 502 | 83 | case 'X': | |||||
| 503 | 3175 | case 'R': | |||||
| 504 | 3679 | case 'Y': | |||||
| 505 | 1136 | case 'W': | |||||
| 506 | 7975 | case 'S': | |||||
| 507 | 2140 | case 'M': | |||||
| 508 | 5750 | case 'K': | |||||
| 509 | 175 | case 'B': | |||||
| 510 | 1918 | case 'H': | |||||
| 511 | 8600 | case 'D': | |||||
| 512 | 7140 | case 'V': | |||||
| 513 | 47101 | return true; | |||||
| 514 | 1 | case 'N': // not counting N as nucleotide | |||||
| 515 | } | ||||||
| 516 | 29353 | return false; | |||||
| 517 | } | ||||||
| 518 | |||||||
|
|||||||
| 519 | 79435 | public static boolean isN(char c)... |
|||||
| 520 | { | ||||||
| 521 | 79435 | return 'n' == Character.toLowerCase(c); | |||||
| 522 | } | ||||||
| 523 | |||||||
|
|||||||
| 524 | 76438 | public static boolean isX(char c)... |
|||||
| 525 | { | ||||||
| 526 | 76438 | return 'x' == Character.toLowerCase(c); | |||||
| 527 | } | ||||||
| 528 | |||||||
| 529 | /** | ||||||
| 530 | * Answers true if every character in the string is one of aAcCgGtTuU, or | ||||||
| 531 | * (optionally) a gap character (dot, dash, space), else false | ||||||
| 532 | * | ||||||
| 533 | * @param s | ||||||
| 534 | * @param allowGaps | ||||||
| 535 | * @return | ||||||
| 536 | */ | ||||||
|
|||||||
| 537 | 22 | public static boolean isNucleotideSequence(String s, boolean allowGaps)... |
|||||
| 538 | { | ||||||
| 539 | 22 | return isNucleotideSequence(s, allowGaps, false); | |||||
| 540 | } | ||||||
| 541 | |||||||
|
|||||||
| 542 | 24 | public static boolean isNucleotideSequence(String s, boolean allowGaps,... |
|||||
| 543 | boolean includeAmbiguous) | ||||||
| 544 | { | ||||||
| 545 | 24 | if (s == null) | |||||
| 546 | { | ||||||
| 547 | 1 | return false; | |||||
| 548 | } | ||||||
| 549 | 112 | for (int i = 0; i < s.length(); i++) | |||||
| 550 | { | ||||||
| 551 | 97 | char c = s.charAt(i); | |||||
| 552 | 97 | if (!isNucleotide(c, includeAmbiguous)) | |||||
| 553 | { | ||||||
| 554 | 13 | if (!allowGaps || !isGap(c)) | |||||
| 555 | { | ||||||
| 556 | 8 | return false; | |||||
| 557 | } | ||||||
| 558 | } | ||||||
| 559 | } | ||||||
| 560 | 15 | return true; | |||||
| 561 | } | ||||||
| 562 | |||||||
| 563 | /** | ||||||
| 564 | * Convenience overload of isNucleotide | ||||||
| 565 | * | ||||||
| 566 | * @param seqs | ||||||
| 567 | * @return | ||||||
| 568 | */ | ||||||
|
|||||||
| 569 | 55 | public static boolean isNucleotide(SequenceI[][] seqs)... |
|||||
| 570 | { | ||||||
| 571 | 55 | if (seqs == null) | |||||
| 572 | { | ||||||
| 573 | 1 | return false; | |||||
| 574 | } | ||||||
| 575 | 54 | List<SequenceI> flattened = new ArrayList<SequenceI>(); | |||||
| 576 | 54 | for (SequenceI[] ss : seqs) | |||||
| 577 | { | ||||||
| 578 | 67 | for (SequenceI s : ss) | |||||
| 579 | { | ||||||
| 580 | 94 | flattened.add(s); | |||||
| 581 | } | ||||||
| 582 | } | ||||||
| 583 | 54 | final SequenceI[] oneDArray = flattened | |||||
| 584 | .toArray(new SequenceI[flattened.size()]); | ||||||
| 585 | 54 | return isNucleotide(oneDArray); | |||||
| 586 | } | ||||||
| 587 | |||||||
| 588 | /** | ||||||
| 589 | * Compares two residues either case sensitively or case insensitively | ||||||
| 590 | * depending on the caseSensitive flag | ||||||
| 591 | * | ||||||
| 592 | * @param c1 | ||||||
| 593 | * first char | ||||||
| 594 | * @param c2 | ||||||
| 595 | * second char to compare with | ||||||
| 596 | * @param caseSensitive | ||||||
| 597 | * if true comparison will be case sensitive otherwise its not | ||||||
| 598 | * @return | ||||||
| 599 | */ | ||||||
|
|||||||
| 600 | 42827 | public static boolean isSameResidue(char c1, char c2,... |
|||||
| 601 | boolean caseSensitive) | ||||||
| 602 | { | ||||||
| 603 | 42827 | return caseSensitive ? c1 == c2 | |||||
| 604 | : Character.toUpperCase(c1) == Character.toUpperCase(c2); | ||||||
| 605 | } | ||||||
| 606 | } |