jalviewX
File StockholmFile.java
Coverage histogram
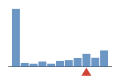
19% of files have more coverage
Classes
| Class | Line # | Actions | ||||
|---|---|---|---|---|---|---|
| StockholmFile | 75 | 454 | 156 | 174 |
Contributing tests
This file is covered by 10 tests.
.
Source view
| 1 | /* | |
| 2 | * Jalview - A Sequence Alignment Editor and Viewer ($$Version-Rel$$) | |
| 3 | * Copyright (C) $$Year-Rel$$ The Jalview Authors | |
| 4 | * | |
| 5 | * This file is part of Jalview. | |
| 6 | * | |
| 7 | * Jalview is free software: you can redistribute it and/or | |
| 8 | * modify it under the terms of the GNU General Public License | |
| 9 | * as published by the Free Software Foundation, either version 3 | |
| 10 | * of the License, or (at your option) any later version. | |
| 11 | * | |
| 12 | * Jalview is distributed in the hope that it will be useful, but | |
| 13 | * WITHOUT ANY WARRANTY; without even the implied warranty | |
| 14 | * of MERCHANTABILITY or FITNESS FOR A PARTICULAR | |
| 15 | * PURPOSE. See the GNU General Public License for more details. | |
| 16 | * | |
| 17 | * You should have received a copy of the GNU General Public License | |
| 18 | * along with Jalview. If not, see <http://www.gnu.org/licenses/>. | |
| 19 | * The Jalview Authors are detailed in the 'AUTHORS' file. | |
| 20 | */ | |
| 21 | /* | |
| 22 | * This extension was written by Benjamin Schuster-Boeckler at sanger.ac.uk | |
| 23 | */ | |
| 24 | package jalview.io; | |
| 25 | ||
| 26 | import jalview.analysis.Rna; | |
| 27 | import jalview.datamodel.AlignmentAnnotation; | |
| 28 | import jalview.datamodel.AlignmentI; | |
| 29 | import jalview.datamodel.Annotation; | |
| 30 | import jalview.datamodel.DBRefEntry; | |
| 31 | import jalview.datamodel.Mapping; | |
| 32 | import jalview.datamodel.Sequence; | |
| 33 | import jalview.datamodel.SequenceFeature; | |
| 34 | import jalview.datamodel.SequenceI; | |
| 35 | import jalview.schemes.ResidueProperties; | |
| 36 | import jalview.util.Comparison; | |
| 37 | import jalview.util.Format; | |
| 38 | import jalview.util.MessageManager; | |
| 39 | ||
| 40 | import java.io.BufferedReader; | |
| 41 | import java.io.FileReader; | |
| 42 | import java.io.IOException; | |
| 43 | import java.util.ArrayList; | |
| 44 | import java.util.Enumeration; | |
| 45 | import java.util.Hashtable; | |
| 46 | import java.util.LinkedHashMap; | |
| 47 | import java.util.List; | |
| 48 | import java.util.Map; | |
| 49 | import java.util.Vector; | |
| 50 | ||
| 51 | import com.stevesoft.pat.Regex; | |
| 52 | ||
| 53 | import fr.orsay.lri.varna.exceptions.ExceptionUnmatchedClosingParentheses; | |
| 54 | import fr.orsay.lri.varna.factories.RNAFactory; | |
| 55 | import fr.orsay.lri.varna.models.rna.RNA; | |
| 56 | ||
| 57 | // import org.apache.log4j.*; | |
| 58 | ||
| 59 | /** | |
| 60 | * This class is supposed to parse a Stockholm format file into Jalview There | |
| 61 | * are TODOs in this class: we do not know what the database source and version | |
| 62 | * is for the file when parsing the #GS= AC tag which associates accessions with | |
| 63 | * sequences. Database references are also not parsed correctly: a separate | |
| 64 | * reference string parser must be added to parse the database reference form | |
| 65 | * into Jalview's local representation. | |
| 66 | * | |
| 67 | * @author bsb at sanger.ac.uk | |
| 68 | * @author Natasha Shersnev (Dundee, UK) (Stockholm file writer) | |
| 69 | * @author Lauren Lui (UCSC, USA) (RNA secondary structure annotation import as | |
| 70 | * stockholm) | |
| 71 | * @author Anne Menard (Paris, FR) (VARNA parsing of Stockholm file data) | |
| 72 | * @version 0.3 + jalview mods | |
| 73 | * | |
| 74 | */ | |
| 75 | public class StockholmFile extends AlignFile | |
| 76 | { | |
| 77 | private static final String ANNOTATION = "annotation"; | |
| 78 | ||
| 79 | private static final Regex OPEN_PAREN = new Regex("(<|\\[)", "("); | |
| 80 | ||
| 81 | private static final Regex CLOSE_PAREN = new Regex("(>|\\])", ")"); | |
| 82 | ||
| 83 | public static final Regex DETECT_BRACKETS = new Regex( | |
| 84 | "(<|>|\\[|\\]|\\(|\\)|\\{|\\})"); | |
| 85 | ||
| 86 | StringBuffer out; // output buffer | |
| 87 | ||
| 88 | AlignmentI al; | |
| 89 | ||
| 90 | 0 |  public StockholmFile() public StockholmFile() |
| 91 | { | |
| 92 | } | |
| 93 | ||
| 94 | /** | |
| 95 | * Creates a new StockholmFile object for output. | |
| 96 | */ | |
| 97 | 9 | public StockholmFile(AlignmentI al) |
| 98 | { | |
| 99 | 9 | this.al = al; |
| 100 | } | |
| 101 | ||
| 102 | 0 | public StockholmFile(String inFile, DataSourceType type) |
| 103 | throws IOException | |
| 104 | { | |
| 105 | 0 | super(inFile, type); |
| 106 | } | |
| 107 | ||
| 108 | 37 | public StockholmFile(FileParse source) throws IOException |
| 109 | { | |
| 110 | 37 | super(source); |
| 111 | } | |
| 112 | ||
| 113 | 46 | @Override |
| 114 | public void initData() | |
| 115 | { | |
| 116 | 46 | super.initData(); |
| 117 | } | |
| 118 | ||
| 119 | /** | |
| 120 | * Parse a file in Stockholm format into Jalview's data model using VARNA | |
| 121 | * | |
| 122 | * @throws IOException | |
| 123 | * If there is an error with the input file | |
| 124 | */ | |
| 125 | 0 | public void parse_with_VARNA(java.io.File inFile) throws IOException |
| 126 | { | |
| 127 | 0 | FileReader fr = null; |
| 128 | 0 | fr = new FileReader(inFile); |
| 129 | ||
| 130 | 0 | BufferedReader r = new BufferedReader(fr); |
| 131 | 0 | List<RNA> result = null; |
| 132 | 0 | try |
| 133 | { | |
| 134 | 0 | result = RNAFactory.loadSecStrStockholm(r); |
| 135 | } catch (ExceptionUnmatchedClosingParentheses umcp) | |
| 136 | { | |
| 137 | 0 | errormessage = "Unmatched parentheses in annotation. Aborting (" |
| 138 | + umcp.getMessage() + ")"; | |
| 139 | 0 | throw new IOException(umcp); |
| 140 | } | |
| 141 | // DEBUG System.out.println("this is the secondary scructure:" | |
| 142 | // +result.size()); | |
| 143 | 0 | SequenceI[] seqs = new SequenceI[result.size()]; |
| 144 | 0 | String id = null; |
| 145 | 0 | for (int i = 0; i < result.size(); i++) |
| 146 | { | |
| 147 | // DEBUG System.err.println("Processing i'th sequence in Stockholm file") | |
| 148 | 0 | RNA current = result.get(i); |
| 149 | ||
| 150 | 0 | String seq = current.getSeq(); |
| 151 | 0 | String rna = current.getStructDBN(true); |
| 152 | // DEBUG System.out.println(seq); | |
| 153 | // DEBUG System.err.println(rna); | |
| 154 | 0 | int begin = 0; |
| 155 | 0 | int end = seq.length() - 1; |
| 156 | 0 | id = safeName(getDataName()); |
| 157 | 0 | seqs[i] = new Sequence(id, seq, begin, end); |
| 158 | 0 | String[] annot = new String[rna.length()]; |
| 159 | 0 | Annotation[] ann = new Annotation[rna.length()]; |
| 160 | 0 | for (int j = 0; j < rna.length(); j++) |
| 161 | { | |
| 162 | 0 | annot[j] = rna.substring(j, j + 1); |
| 163 | ||
| 164 | } | |
| 165 | ||
| 166 | 0 | for (int k = 0; k < rna.length(); k++) |
| 167 | { | |
| 168 | 0 | ann[k] = new Annotation(annot[k], "", |
| 169 | Rna.getRNASecStrucState(annot[k]).charAt(0), 0f); | |
| 170 | ||
| 171 | } | |
| 172 | 0 | AlignmentAnnotation align = new AlignmentAnnotation("Sec. str.", |
| 173 | current.getID(), ann); | |
| 174 | ||
| 175 | 0 | seqs[i].addAlignmentAnnotation(align); |
| 176 | 0 | seqs[i].setRNA(result.get(i)); |
| 177 | 0 | this.annotations.addElement(align); |
| 178 | } | |
| 179 | 0 | this.setSeqs(seqs); |
| 180 | ||
| 181 | } | |
| 182 | ||
| 183 | /** | |
| 184 | * Parse a file in Stockholm format into Jalview's data model. The file has to | |
| 185 | * be passed at construction time | |
| 186 | * | |
| 187 | * @throws IOException | |
| 188 | * If there is an error with the input file | |
| 189 | */ | |
| 190 | 37 | @Override |
| 191 | public void parse() throws IOException | |
| 192 | { | |
| 193 | 37 | StringBuffer treeString = new StringBuffer(); |
| 194 | 37 | String treeName = null; |
| 195 | // --------------- Variable Definitions ------------------- | |
| 196 | 37 | String line; |
| 197 | 37 | String version; |
| 198 | // String id; | |
| 199 | 37 | Hashtable seqAnn = new Hashtable(); // Sequence related annotations |
| 200 | 37 | LinkedHashMap<String, String> seqs = new LinkedHashMap<String, String>(); |
| 201 | 37 | Regex p, r, rend, s, x; |
| 202 | // Temporary line for processing RNA annotation | |
| 203 | // String RNAannot = ""; | |
| 204 | ||
| 205 | // ------------------ Parsing File ---------------------- | |
| 206 | // First, we have to check that this file has STOCKHOLM format, i.e. the | |
| 207 | // first line must match | |
| 208 | ||
| 209 | 37 | r = new Regex("# STOCKHOLM ([\\d\\.]+)"); |
| 210 | 37 | if (!r.search(nextLine())) |
| 211 | { | |
| 212 | 0 | throw new IOException(MessageManager |
| 213 | .getString("exception.stockholm_invalid_format")); | |
| 214 | } | |
| 215 | else | |
| 216 | { | |
| 217 | 37 | version = r.stringMatched(1); |
| 218 | ||
| 219 | // logger.debug("Stockholm version: " + version); | |
| 220 | } | |
| 221 | ||
| 222 | // We define some Regexes here that will be used regularily later | |
| 223 | 37 | rend = new Regex("^\\s*\\/\\/"); // Find the end of an alignment |
| 224 | 37 | p = new Regex("(\\S+)\\/(\\d+)\\-(\\d+)"); // split sequence id in |
| 225 | // id/from/to | |
| 226 | 37 | s = new Regex("(\\S+)\\s+(\\S*)\\s+(.*)"); // Parses annotation subtype |
| 227 | 37 | r = new Regex("#=(G[FSRC]?)\\s+(.*)"); // Finds any annotation line |
| 228 | 37 | x = new Regex("(\\S+)\\s+(\\S+)"); // split id from sequence |
| 229 | ||
| 230 | // Convert all bracket types to parentheses (necessary for passing to VARNA) | |
| 231 | 37 | Regex openparen = new Regex("(<|\\[)", "("); |
| 232 | 37 | Regex closeparen = new Regex("(>|\\])", ")"); |
| 233 | ||
| 234 | // Detect if file is RNA by looking for bracket types | |
| 235 | 37 | Regex detectbrackets = new Regex("(<|>|\\[|\\]|\\(|\\))"); |
| 236 | ||
| 237 | 37 | rend.optimize(); |
| 238 | 37 | p.optimize(); |
| 239 | 37 | s.optimize(); |
| 240 | 37 | r.optimize(); |
| 241 | 37 | x.optimize(); |
| 242 | 37 | openparen.optimize(); |
| 243 | 37 | closeparen.optimize(); |
| 244 | ||
| 245 | ? | while ((line = nextLine()) != null) |
| 246 | { | |
| 247 | 2436 | if (line.length() == 0) |
| 248 | { | |
| 249 | 6 | continue; |
| 250 | } | |
| 251 | 2430 | if (rend.search(line)) |
| 252 | { | |
| 253 | // End of the alignment, pass stuff back | |
| 254 | 37 | this.noSeqs = seqs.size(); |
| 255 | ||
| 256 | 37 | String seqdb, dbsource = null; |
| 257 | 37 | Regex pf = new Regex("PF[0-9]{5}(.*)"); // Finds AC for Pfam |
| 258 | 37 | Regex rf = new Regex("RF[0-9]{5}(.*)"); // Finds AC for Rfam |
| 259 | 37 | if (getAlignmentProperty("AC") != null) |
| 260 | { | |
| 261 | 6 | String dbType = getAlignmentProperty("AC").toString(); |
| 262 | 6 | if (pf.search(dbType)) |
| 263 | { | |
| 264 | // PFAM Alignment - so references are typically from Uniprot | |
| 265 | 3 | dbsource = "PFAM"; |
| 266 | } | |
| 267 | 3 | else if (rf.search(dbType)) |
| 268 | { | |
| 269 | 3 | dbsource = "RFAM"; |
| 270 | } | |
| 271 | } | |
| 272 | // logger.debug("Number of sequences: " + this.noSeqs); | |
| 273 | 37 | for (Map.Entry<String, String> skey : seqs.entrySet()) |
| 274 | { | |
| 275 | // logger.debug("Processing sequence " + acc); | |
| 276 | 899 | String acc = skey.getKey(); |
| 277 | 899 | String seq = skey.getValue(); |
| 278 | 899 | if (maxLength < seq.length()) |
| 279 | { | |
| 280 | 37 | maxLength = seq.length(); |
| 281 | } | |
| 282 | 899 | int start = 1; |
| 283 | 899 | int end = -1; |
| 284 | 899 | String sid = acc; |
| 285 | /* | |
| 286 | * Retrieve hash of annotations for this accession Associate | |
| 287 | * Annotation with accession | |
| 288 | */ | |
| 289 | 899 | Hashtable accAnnotations = null; |
| 290 | ||
| 291 | 899 | if (seqAnn != null && seqAnn.containsKey(acc)) |
| 292 | { | |
| 293 | 884 | accAnnotations = (Hashtable) seqAnn.remove(acc); |
| 294 | // TODO: add structures to sequence | |
| 295 | } | |
| 296 | ||
| 297 | // Split accession in id and from/to | |
| 298 | 899 | if (p.search(acc)) |
| 299 | { | |
| 300 | 684 | sid = p.stringMatched(1); |
| 301 | 684 | start = Integer.parseInt(p.stringMatched(2)); |
| 302 | 684 | end = Integer.parseInt(p.stringMatched(3)); |
| 303 | } | |
| 304 | // logger.debug(sid + ", " + start + ", " + end); | |
| 305 | ||
| 306 | 899 | Sequence seqO = new Sequence(sid, seq, start, end); |
| 307 | // Add Description (if any) | |
| 308 | 899 | if (accAnnotations != null && accAnnotations.containsKey("DE")) |
| 309 | { | |
| 310 | 0 | String desc = (String) accAnnotations.get("DE"); |
| 311 | 0 | seqO.setDescription((desc == null) ? "" : desc); |
| 312 | } | |
| 313 | // Add DB References (if any) | |
| 314 | 899 | if (accAnnotations != null && accAnnotations.containsKey("DR")) |
| 315 | { | |
| 316 | 26 | String dbr = (String) accAnnotations.get("DR"); |
| 317 | 26 | if (dbr != null && dbr.indexOf(";") > -1) |
| 318 | { | |
| 319 | 26 | String src = dbr.substring(0, dbr.indexOf(";")); |
| 320 | 26 | String acn = dbr.substring(dbr.indexOf(";") + 1); |
| 321 | 26 | jalview.util.DBRefUtils.parseToDbRef(seqO, src, "0", acn); |
| 322 | } | |
| 323 | } | |
| 324 | ||
| 325 | 899 | if (accAnnotations != null && accAnnotations.containsKey("AC")) |
| 326 | { | |
| 327 | 879 | if (dbsource != null) |
| 328 | { | |
| 329 | 801 | String dbr = (String) accAnnotations.get("AC"); |
| 330 | 801 | if (dbr != null) |
| 331 | { | |
| 332 | // we could get very clever here - but for now - just try to | |
| 333 | // guess accession type from source of alignment plus structure | |
| 334 | // of accession | |
| 335 | 801 | guessDatabaseFor(seqO, dbr, dbsource); |
| 336 | ||
| 337 | } | |
| 338 | } | |
| 339 | // else - do what ? add the data anyway and prompt the user to | |
| 340 | // specify what references these are ? | |
| 341 | } | |
| 342 | ||
| 343 | 899 | Hashtable features = null; |
| 344 | // We need to adjust the positions of all features to account for gaps | |
| 345 | 899 | try |
| 346 | { | |
| 347 | 899 | features = (Hashtable) accAnnotations.remove("features"); |
| 348 | } catch (java.lang.NullPointerException e) | |
| 349 | { | |
| 350 | // loggerwarn("Getting Features for " + acc + ": " + | |
| 351 | // e.getMessage()); | |
| 352 | // continue; | |
| 353 | } | |
| 354 | // if we have features | |
| 355 | 899 | if (features != null) |
| 356 | { | |
| 357 | 305 | int posmap[] = seqO.findPositionMap(); |
| 358 | 305 | Enumeration i = features.keys(); |
| 359 | 610 | while (i.hasMoreElements()) |
| 360 | { | |
| 361 | // TODO: parse out secondary structure annotation as annotation | |
| 362 | // row | |
| 363 | // TODO: parse out scores as annotation row | |
| 364 | // TODO: map coding region to core jalview feature types | |
| 365 | 305 | String type = i.nextElement().toString(); |
| 366 | 305 | Hashtable content = (Hashtable) features.remove(type); |
| 367 | ||
| 368 | // add alignment annotation for this feature | |
| 369 | 305 | String key = type2id(type); |
| 370 | ||
| 371 | /* | |
| 372 | * have we added annotation rows for this type ? | |
| 373 | */ | |
| 374 | 305 | boolean annotsAdded = false; |
| 375 | 305 | if (key != null) |
| 376 | { | |
| 377 | 305 | if (accAnnotations != null |
| 378 | && accAnnotations.containsKey(key)) | |
| 379 | { | |
| 380 | 305 | Vector vv = (Vector) accAnnotations.get(key); |
| 381 | 610 | for (int ii = 0; ii < vv.size(); ii++) |
| 382 | { | |
| 383 | 305 | annotsAdded = true; |
| 384 | 305 | AlignmentAnnotation an = (AlignmentAnnotation) vv |
| 385 | .elementAt(ii); | |
| 386 | 305 | seqO.addAlignmentAnnotation(an); |
| 387 | 305 | annotations.add(an); |
| 388 | } | |
| 389 | } | |
| 390 | } | |
| 391 | ||
| 392 | 305 | Enumeration j = content.keys(); |
| 393 | 610 | while (j.hasMoreElements()) |
| 394 | { | |
| 395 | 305 | String desc = j.nextElement().toString(); |
| 396 | 305 | if (ANNOTATION.equals(desc) && annotsAdded) |
| 397 | { | |
| 398 | // don't add features if we already added an annotation row | |
| 399 | 305 | continue; |
| 400 | } | |
| 401 | 0 | String ns = content.get(desc).toString(); |
| 402 | 0 | char[] byChar = ns.toCharArray(); |
| 403 | 0 | for (int k = 0; k < byChar.length; k++) |
| 404 | { | |
| 405 | 0 | char c = byChar[k]; |
| 406 | 0 | if (!(c == ' ' || c == '_' || c == '-' || c == '.')) // PFAM |
| 407 | // uses | |
| 408 | // '.' | |
| 409 | // for | |
| 410 | // feature | |
| 411 | // background | |
| 412 | { | |
| 413 | 0 | int new_pos = posmap[k]; // look up nearest seqeunce |
| 414 | // position to this column | |
| 415 | 0 | SequenceFeature feat = new SequenceFeature(type, desc, |
| 416 | new_pos, new_pos, null); | |
| 417 | ||
| 418 | 0 | seqO.addSequenceFeature(feat); |
| 419 | } | |
| 420 | } | |
| 421 | } | |
| 422 | ||
| 423 | } | |
| 424 | ||
| 425 | } | |
| 426 | // garbage collect | |
| 427 | ||
| 428 | // logger.debug("Adding seq " + acc + " from " + start + " to " + end | |
| 429 | // + ": " + seq); | |
| 430 | 899 | this.seqs.addElement(seqO); |
| 431 | } | |
| 432 | 37 | return; // finished parsing this segment of source |
| 433 | } | |
| 434 | 2393 | else if (!r.search(line)) |
| 435 | { | |
| 436 | // System.err.println("Found sequence line: " + line); | |
| 437 | ||
| 438 | // Split sequence in sequence and accession parts | |
| 439 | 899 | if (!x.search(line)) |
| 440 | { | |
| 441 | // logger.error("Could not parse sequence line: " + line); | |
| 442 | 0 | throw new IOException(MessageManager.formatMessage( |
| 443 | "exception.couldnt_parse_sequence_line", new String[] | |
| 444 | { line })); | |
| 445 | } | |
| 446 | 899 | String ns = seqs.get(x.stringMatched(1)); |
| 447 | 899 | if (ns == null) |
| 448 | { | |
| 449 | 899 | ns = ""; |
| 450 | } | |
| 451 | 899 | ns += x.stringMatched(2); |
| 452 | ||
| 453 | 899 | seqs.put(x.stringMatched(1), ns); |
| 454 | } | |
| 455 | else | |
| 456 | { | |
| 457 | 1494 | String annType = r.stringMatched(1); |
| 458 | 1494 | String annContent = r.stringMatched(2); |
| 459 | ||
| 460 | // System.err.println("type:" + annType + " content: " + annContent); | |
| 461 | ||
| 462 | 1494 | if (annType.equals("GF")) |
| 463 | { | |
| 464 | /* | |
| 465 | * Generic per-File annotation, free text Magic features: #=GF NH | |
| 466 | * <tree in New Hampshire eXtended format> #=GF TN <Unique identifier | |
| 467 | * for the next tree> Pfam descriptions: 7. DESCRIPTION OF FIELDS | |
| 468 | * | |
| 469 | * Compulsory fields: ------------------ | |
| 470 | * | |
| 471 | * AC Accession number: Accession number in form PFxxxxx.version or | |
| 472 | * PBxxxxxx. ID Identification: One word name for family. DE | |
| 473 | * Definition: Short description of family. AU Author: Authors of the | |
| 474 | * entry. SE Source of seed: The source suggesting the seed members | |
| 475 | * belong to one family. GA Gathering method: Search threshold to | |
| 476 | * build the full alignment. TC Trusted Cutoff: Lowest sequence score | |
| 477 | * and domain score of match in the full alignment. NC Noise Cutoff: | |
| 478 | * Highest sequence score and domain score of match not in full | |
| 479 | * alignment. TP Type: Type of family -- presently Family, Domain, | |
| 480 | * Motif or Repeat. SQ Sequence: Number of sequences in alignment. AM | |
| 481 | * Alignment Method The order ls and fs hits are aligned to the model | |
| 482 | * to build the full align. // End of alignment. | |
| 483 | * | |
| 484 | * Optional fields: ---------------- | |
| 485 | * | |
| 486 | * DC Database Comment: Comment about database reference. DR Database | |
| 487 | * Reference: Reference to external database. RC Reference Comment: | |
| 488 | * Comment about literature reference. RN Reference Number: Reference | |
| 489 | * Number. RM Reference Medline: Eight digit medline UI number. RT | |
| 490 | * Reference Title: Reference Title. RA Reference Author: Reference | |
| 491 | * Author RL Reference Location: Journal location. PI Previous | |
| 492 | * identifier: Record of all previous ID lines. KW Keywords: Keywords. | |
| 493 | * CC Comment: Comments. NE Pfam accession: Indicates a nested domain. | |
| 494 | * NL Location: Location of nested domains - sequence ID, start and | |
| 495 | * end of insert. | |
| 496 | * | |
| 497 | * Obsolete fields: ----------- AL Alignment method of seed: The | |
| 498 | * method used to align the seed members. | |
| 499 | */ | |
| 500 | // Let's save the annotations, maybe we'll be able to do something | |
| 501 | // with them later... | |
| 502 | 150 | Regex an = new Regex("(\\w+)\\s*(.*)"); |
| 503 | 150 | if (an.search(annContent)) |
| 504 | { | |
| 505 | 150 | if (an.stringMatched(1).equals("NH")) |
| 506 | { | |
| 507 | 0 | treeString.append(an.stringMatched(2)); |
| 508 | } | |
| 509 | 150 | else if (an.stringMatched(1).equals("TN")) |
| 510 | { | |
| 511 | 0 | if (treeString.length() > 0) |
| 512 | { | |
| 513 | 0 | if (treeName == null) |
| 514 | { | |
| 515 | 0 | treeName = "Tree " + (getTreeCount() + 1); |
| 516 | } | |
| 517 | 0 | addNewickTree(treeName, treeString.toString()); |
| 518 | } | |
| 519 | 0 | treeName = an.stringMatched(2); |
| 520 | 0 | treeString = new StringBuffer(); |
| 521 | } | |
| 522 | 150 | setAlignmentProperty(an.stringMatched(1), an.stringMatched(2)); |
| 523 | } | |
| 524 | } | |
| 525 | 1344 | else if (annType.equals("GS")) |
| 526 | { | |
| 527 | // Generic per-Sequence annotation, free text | |
| 528 | /* | |
| 529 | * Pfam uses these features: Feature Description --------------------- | |
| 530 | * ----------- AC <accession> ACcession number DE <freetext> | |
| 531 | * DEscription DR <db>; <accession>; Database Reference OS <organism> | |
| 532 | * OrganiSm (species) OC <clade> Organism Classification (clade, etc.) | |
| 533 | * LO <look> Look (Color, etc.) | |
| 534 | */ | |
| 535 | 1027 | if (s.search(annContent)) |
| 536 | { | |
| 537 | 1027 | String acc = s.stringMatched(1); |
| 538 | 1027 | String type = s.stringMatched(2); |
| 539 | 1027 | String content = s.stringMatched(3); |
| 540 | // TODO: store DR in a vector. | |
| 541 | // TODO: store AC according to generic file db annotation. | |
| 542 | 1027 | Hashtable ann; |
| 543 | 1027 | if (seqAnn.containsKey(acc)) |
| 544 | { | |
| 545 | 148 | ann = (Hashtable) seqAnn.get(acc); |
| 546 | } | |
| 547 | else | |
| 548 | { | |
| 549 | 879 | ann = new Hashtable(); |
| 550 | } | |
| 551 | 1027 | ann.put(type, content); |
| 552 | 1027 | seqAnn.put(acc, ann); |
| 553 | } | |
| 554 | else | |
| 555 | { | |
| 556 | // throw new IOException("Error parsing " + line); | |
| 557 | 0 | System.err.println(">> missing annotation: " + line); |
| 558 | } | |
| 559 | } | |
| 560 | 317 | else if (annType.equals("GC")) |
| 561 | { | |
| 562 | // Generic per-Column annotation, exactly 1 char per column | |
| 563 | // always need a label. | |
| 564 | 12 | if (x.search(annContent)) |
| 565 | { | |
| 566 | // parse out and create alignment annotation directly. | |
| 567 | 12 | parseAnnotationRow(annotations, x.stringMatched(1), |
| 568 | x.stringMatched(2)); | |
| 569 | } | |
| 570 | } | |
| 571 | 305 | else if (annType.equals("GR")) |
| 572 | { | |
| 573 | // Generic per-Sequence AND per-Column markup, exactly 1 char per | |
| 574 | // column | |
| 575 | /* | |
| 576 | * Feature Description Markup letters ------- ----------- | |
| 577 | * -------------- SS Secondary Structure [HGIEBTSCX] SA Surface | |
| 578 | * Accessibility [0-9X] (0=0%-10%; ...; 9=90%-100%) TM TransMembrane | |
| 579 | * [Mio] PP Posterior Probability [0-9*] (0=0.00-0.05; 1=0.05-0.15; | |
| 580 | * *=0.95-1.00) LI LIgand binding [*] AS Active Site [*] IN INtron (in | |
| 581 | * or after) [0-2] | |
| 582 | */ | |
| 583 | 305 | if (s.search(annContent)) |
| 584 | { | |
| 585 | 305 | String acc = s.stringMatched(1); |
| 586 | 305 | String type = s.stringMatched(2); |
| 587 | 305 | String oseq = s.stringMatched(3); |
| 588 | /* | |
| 589 | * copy of annotation field that may be processed into whitespace chunks | |
| 590 | */ | |
| 591 | 305 | String seq = new String(oseq); |
| 592 | ||
| 593 | 305 | Hashtable ann; |
| 594 | // Get an object with all the annotations for this sequence | |
| 595 | 305 | if (seqAnn.containsKey(acc)) |
| 596 | { | |
| 597 | // logger.debug("Found annotations for " + acc); | |
| 598 | 300 | ann = (Hashtable) seqAnn.get(acc); |
| 599 | } | |
| 600 | else | |
| 601 | { | |
| 602 | // logger.debug("Creating new annotations holder for " + acc); | |
| 603 | 5 | ann = new Hashtable(); |
| 604 | 5 | seqAnn.put(acc, ann); |
| 605 | } | |
| 606 | ||
| 607 | // // start of block for appending annotation lines for wrapped | |
| 608 | // stokchholm file | |
| 609 | // TODO test structure, call parseAnnotationRow with vector from | |
| 610 | // hashtable for specific sequence | |
| 611 | ||
| 612 | 305 | Hashtable features; |
| 613 | // Get an object with all the content for an annotation | |
| 614 | 305 | if (ann.containsKey("features")) |
| 615 | { | |
| 616 | // logger.debug("Found features for " + acc); | |
| 617 | 0 | features = (Hashtable) ann.get("features"); |
| 618 | } | |
| 619 | else | |
| 620 | { | |
| 621 | // logger.debug("Creating new features holder for " + acc); | |
| 622 | 305 | features = new Hashtable(); |
| 623 | 305 | ann.put("features", features); |
| 624 | } | |
| 625 | ||
| 626 | 305 | Hashtable content; |
| 627 | 305 | if (features.containsKey(this.id2type(type))) |
| 628 | { | |
| 629 | // logger.debug("Found content for " + this.id2type(type)); | |
| 630 | 0 | content = (Hashtable) features.get(this.id2type(type)); |
| 631 | } | |
| 632 | else | |
| 633 | { | |
| 634 | // logger.debug("Creating new content holder for " + | |
| 635 | // this.id2type(type)); | |
| 636 | 305 | content = new Hashtable(); |
| 637 | 305 | features.put(this.id2type(type), content); |
| 638 | } | |
| 639 | 305 | String ns = (String) content.get(ANNOTATION); |
| 640 | ||
| 641 | 305 | if (ns == null) |
| 642 | { | |
| 643 | 305 | ns = ""; |
| 644 | } | |
| 645 | // finally, append the annotation line | |
| 646 | 305 | ns += seq; |
| 647 | 305 | content.put(ANNOTATION, ns); |
| 648 | // // end of wrapped annotation block. | |
| 649 | // // Now a new row is created with the current set of data | |
| 650 | ||
| 651 | 305 | Hashtable strucAnn; |
| 652 | 305 | if (seqAnn.containsKey(acc)) |
| 653 | { | |
| 654 | 305 | strucAnn = (Hashtable) seqAnn.get(acc); |
| 655 | } | |
| 656 | else | |
| 657 | { | |
| 658 | 0 | strucAnn = new Hashtable(); |
| 659 | } | |
| 660 | ||
| 661 | 305 | Vector<AlignmentAnnotation> newStruc = new Vector<AlignmentAnnotation>(); |
| 662 | 305 | parseAnnotationRow(newStruc, type, ns); |
| 663 | 305 | for (AlignmentAnnotation alan : newStruc) |
| 664 | { | |
| 665 | 305 | alan.visible = false; |
| 666 | } | |
| 667 | // new annotation overwrites any existing annotation... | |
| 668 | ||
| 669 | 305 | strucAnn.put(type, newStruc); |
| 670 | 305 | seqAnn.put(acc, strucAnn); |
| 671 | } | |
| 672 | // } | |
| 673 | else | |
| 674 | { | |
| 675 | 0 | System.err.println( |
| 676 | "Warning - couldn't parse sequence annotation row line:\n" | |
| 677 | + line); | |
| 678 | // throw new IOException("Error parsing " + line); | |
| 679 | } | |
| 680 | } | |
| 681 | else | |
| 682 | { | |
| 683 | 0 | throw new IOException(MessageManager.formatMessage( |
| 684 | "exception.unknown_annotation_detected", new String[] | |
| 685 | { annType, annContent })); | |
| 686 | } | |
| 687 | } | |
| 688 | } | |
| 689 | 0 | if (treeString.length() > 0) |
| 690 | { | |
| 691 | 0 | if (treeName == null) |
| 692 | { | |
| 693 | 0 | treeName = "Tree " + (1 + getTreeCount()); |
| 694 | } | |
| 695 | 0 | addNewickTree(treeName, treeString.toString()); |
| 696 | } | |
| 697 | } | |
| 698 | ||
| 699 | /** | |
| 700 | * Demangle an accession string and guess the originating sequence database | |
| 701 | * for a given sequence | |
| 702 | * | |
| 703 | * @param seqO | |
| 704 | * sequence to be annotated | |
| 705 | * @param dbr | |
| 706 | * Accession string for sequence | |
| 707 | * @param dbsource | |
| 708 | * source database for alignment (PFAM or RFAM) | |
| 709 | */ | |
| 710 | 801 | private void guessDatabaseFor(Sequence seqO, String dbr, String dbsource) |
| 711 | { | |
| 712 | 801 | DBRefEntry dbrf = null; |
| 713 | 801 | List<DBRefEntry> dbrs = new ArrayList<DBRefEntry>(); |
| 714 | 801 | String seqdb = "Unknown", sdbac = "" + dbr; |
| 715 | 801 | int st = -1, en = -1, p; |
| 716 | ? | if ((st = sdbac.indexOf("/")) > -1) |
| 717 | { | |
| 718 | 183 | String num, range = sdbac.substring(st + 1); |
| 719 | 183 | sdbac = sdbac.substring(0, st); |
| 720 | ? | if ((p = range.indexOf("-")) > -1) |
| 721 | { | |
| 722 | 183 | p++; |
| 723 | 183 | if (p < range.length()) |
| 724 | { | |
| 725 | 183 | num = range.substring(p).trim(); |
| 726 | 183 | try |
| 727 | { | |
| 728 | 183 | en = Integer.parseInt(num); |
| 729 | } catch (NumberFormatException x) | |
| 730 | { | |
| 731 | // could warn here that index is invalid | |
| 732 | 0 | en = -1; |
| 733 | } | |
| 734 | } | |
| 735 | } | |
| 736 | else | |
| 737 | { | |
| 738 | 0 | p = range.length(); |
| 739 | } | |
| 740 | 183 | num = range.substring(0, p).trim(); |
| 741 | 183 | try |
| 742 | { | |
| 743 | 183 | st = Integer.parseInt(num); |
| 744 | } catch (NumberFormatException x) | |
| 745 | { | |
| 746 | // could warn here that index is invalid | |
| 747 | 183 | st = -1; |
| 748 | } | |
| 749 | } | |
| 750 | 801 | if (dbsource.equals("PFAM")) |
| 751 | { | |
| 752 | 618 | seqdb = "UNIPROT"; |
| 753 | 618 | if (sdbac.indexOf(".") > -1) |
| 754 | { | |
| 755 | // strip of last subdomain | |
| 756 | 618 | sdbac = sdbac.substring(0, sdbac.indexOf(".")); |
| 757 | 618 | dbrf = jalview.util.DBRefUtils.parseToDbRef(seqO, seqdb, dbsource, |
| 758 | sdbac); | |
| 759 | 618 | if (dbrf != null) |
| 760 | { | |
| 761 | 618 | dbrs.add(dbrf); |
| 762 | } | |
| 763 | } | |
| 764 | 618 | dbrf = jalview.util.DBRefUtils.parseToDbRef(seqO, dbsource, dbsource, |
| 765 | dbr); | |
| 766 | 618 | if (dbr != null) |
| 767 | { | |
| 768 | 618 | dbrs.add(dbrf); |
| 769 | } | |
| 770 | } | |
| 771 | else | |
| 772 | { | |
| 773 | 183 | seqdb = "EMBL"; // total guess - could be ENA, or something else these |
| 774 | // days | |
| 775 | 183 | if (sdbac.indexOf(".") > -1) |
| 776 | { | |
| 777 | // strip off last subdomain | |
| 778 | 183 | sdbac = sdbac.substring(0, sdbac.indexOf(".")); |
| 779 | 183 | dbrf = jalview.util.DBRefUtils.parseToDbRef(seqO, seqdb, dbsource, |
| 780 | sdbac); | |
| 781 | 183 | if (dbrf != null) |
| 782 | { | |
| 783 | 183 | dbrs.add(dbrf); |
| 784 | } | |
| 785 | } | |
| 786 | ||
| 787 | 183 | dbrf = jalview.util.DBRefUtils.parseToDbRef(seqO, dbsource, dbsource, |
| 788 | dbr); | |
| 789 | 183 | if (dbrf != null) |
| 790 | { | |
| 791 | 183 | dbrs.add(dbrf); |
| 792 | } | |
| 793 | } | |
| 794 | 801 | if (st != -1 && en != -1) |
| 795 | { | |
| 796 | 0 | for (DBRefEntry d : dbrs) |
| 797 | { | |
| 798 | 0 | jalview.util.MapList mp = new jalview.util.MapList( |
| 799 | new int[] | |
| 800 | { seqO.getStart(), seqO.getEnd() }, new int[] { st, en }, 1, | |
| 801 | 1); | |
| 802 | 0 | jalview.datamodel.Mapping mping = new Mapping(mp); |
| 803 | 0 | d.setMap(mping); |
| 804 | } | |
| 805 | } | |
| 806 | } | |
| 807 | ||
| 808 | 317 | protected static AlignmentAnnotation parseAnnotationRow( |
| 809 | Vector<AlignmentAnnotation> annotation, String label, | |
| 810 | String annots) | |
| 811 | { | |
| 812 | 317 | String convert1, convert2 = null; |
| 813 | ||
| 814 | // convert1 = OPEN_PAREN.replaceAll(annots); | |
| 815 | // convert2 = CLOSE_PAREN.replaceAll(convert1); | |
| 816 | // annots = convert2; | |
| 817 | ||
| 818 | 317 | String type = label; |
| 819 | 317 | if (label.contains("_cons")) |
| 820 | { | |
| 821 | 10 | type = (label.indexOf("_cons") == label.length() - 5) |
| 822 | ? label.substring(0, label.length() - 5) | |
| 823 | : label; | |
| 824 | } | |
| 825 | 317 | boolean ss = false, posterior = false; |
| 826 | 317 | type = id2type(type); |
| 827 | 317 | if (type.equalsIgnoreCase("secondary structure")) |
| 828 | { | |
| 829 | 311 | ss = true; |
| 830 | } | |
| 831 | 317 | if (type.equalsIgnoreCase("posterior probability")) |
| 832 | { | |
| 833 | 0 | posterior = true; |
| 834 | } | |
| 835 | // decide on secondary structure or not. | |
| 836 | 317 | Annotation[] els = new Annotation[annots.length()]; |
| 837 | 25652 | for (int i = 0; i < annots.length(); i++) |
| 838 | { | |
| 839 | 25335 | String pos = annots.substring(i, i + 1); |
| 840 | 25335 | Annotation ann; |
| 841 | 25335 | ann = new Annotation(pos, "", ' ', 0f); // 0f is 'valid' null - will not |
| 842 | // be written out | |
| 843 | 25335 | if (ss) |
| 844 | { | |
| 845 | // if (" .-_".indexOf(pos) == -1) | |
| 846 | { | |
| 847 | 24684 | if (DETECT_BRACKETS.search(pos)) |
| 848 | { | |
| 849 | 7906 | ann.secondaryStructure = Rna.getRNASecStrucState(pos).charAt(0); |
| 850 | 7906 | ann.displayCharacter = "" + pos.charAt(0); |
| 851 | } | |
| 852 | else | |
| 853 | { | |
| 854 | 16778 | ann.secondaryStructure = ResidueProperties.getDssp3state(pos) |
| 855 | .charAt(0); | |
| 856 | ||
| 857 | 16778 | if (ann.secondaryStructure == pos.charAt(0)) |
| 858 | { | |
| 859 | 3538 | ann.displayCharacter = ""; // null; // " "; |
| 860 | } | |
| 861 | else | |
| 862 | { | |
| 863 | 13240 | ann.displayCharacter = " " + ann.displayCharacter; |
| 864 | } | |
| 865 | } | |
| 866 | } | |
| 867 | ||
| 868 | } | |
| 869 | 25335 | if (posterior && !ann.isWhitespace() |
| 870 | && !Comparison.isGap(pos.charAt(0))) | |
| 871 | { | |
| 872 | 0 | float val = 0; |
| 873 | // symbol encodes values - 0..*==0..10 | |
| 874 | 0 | if (pos.charAt(0) == '*') |
| 875 | { | |
| 876 | 0 | val = 10; |
| 877 | } | |
| 878 | else | |
| 879 | { | |
| 880 | 0 | val = pos.charAt(0) - '0'; |
| 881 | 0 | if (val > 9) |
| 882 | { | |
| 883 | 0 | val = 10; |
| 884 | } | |
| 885 | } | |
| 886 | 0 | ann.value = val; |
| 887 | } | |
| 888 | ||
| 889 | 25335 | els[i] = ann; |
| 890 | } | |
| 891 | 317 | AlignmentAnnotation annot = null; |
| 892 | 317 | Enumeration<AlignmentAnnotation> e = annotation.elements(); |
| 893 | 323 | while (e.hasMoreElements()) |
| 894 | { | |
| 895 | 6 | annot = e.nextElement(); |
| 896 | 6 | if (annot.label.equals(type)) |
| 897 | { | |
| 898 | 0 | break; |
| 899 | } | |
| 900 | 6 | annot = null; |
| 901 | } | |
| 902 | 317 | if (annot == null) |
| 903 | { | |
| 904 | 317 | annot = new AlignmentAnnotation(type, type, els); |
| 905 | 317 | annotation.addElement(annot); |
| 906 | } | |
| 907 | else | |
| 908 | { | |
| 909 | 0 | Annotation[] anns = new Annotation[annot.annotations.length |
| 910 | + els.length]; | |
| 911 | 0 | System.arraycopy(annot.annotations, 0, anns, 0, |
| 912 | annot.annotations.length); | |
| 913 | 0 | System.arraycopy(els, 0, anns, annot.annotations.length, els.length); |
| 914 | 0 | annot.annotations = anns; |
| 915 | // System.out.println("else: "); | |
| 916 | } | |
| 917 | 317 | return annot; |
| 918 | } | |
| 919 | ||
| 920 | 9 | @Override |
| 921 | public String print(SequenceI[] s, boolean jvSuffix) | |
| 922 | { | |
| 923 | 9 | out = new StringBuffer(); |
| 924 | 9 | out.append("# STOCKHOLM 1.0"); |
| 925 | 9 | out.append(newline); |
| 926 | ||
| 927 | // find max length of id | |
| 928 | 9 | int max = 0; |
| 929 | 9 | int maxid = 0; |
| 930 | 9 | int in = 0; |
| 931 | 9 | Hashtable dataRef = null; |
| 932 | 302 | while ((in < s.length) && (s[in] != null)) |
| 933 | { | |
| 934 | 293 | String tmp = printId(s[in], jvSuffix); |
| 935 | 293 | max = Math.max(max, s[in].getLength()); |
| 936 | ||
| 937 | 293 | if (tmp.length() > maxid) |
| 938 | { | |
| 939 | 14 | maxid = tmp.length(); |
| 940 | } | |
| 941 | 293 | if (s[in].getDBRefs() != null) |
| 942 | { | |
| 943 | 814 | for (int idb = 0; idb < s[in].getDBRefs().length; idb++) |
| 944 | { | |
| 945 | 547 | if (dataRef == null) |
| 946 | { | |
| 947 | 2 | dataRef = new Hashtable(); |
| 948 | } | |
| 949 | ||
| 950 | 547 | String datAs1 = s[in].getDBRefs()[idb].getSource().toString() |
| 951 | + " ; " | |
| 952 | + s[in].getDBRefs()[idb].getAccessionId().toString(); | |
| 953 | 547 | dataRef.put(tmp, datAs1); |
| 954 | } | |
| 955 | } | |
| 956 | 293 | in++; |
| 957 | } | |
| 958 | 9 | maxid += 9; |
| 959 | 9 | int i = 0; |
| 960 | ||
| 961 | // output database type | |
| 962 | 9 | if (al.getProperties() != null) |
| 963 | { | |
| 964 | 2 | if (!al.getProperties().isEmpty()) |
| 965 | { | |
| 966 | 2 | Enumeration key = al.getProperties().keys(); |
| 967 | 2 | Enumeration val = al.getProperties().elements(); |
| 968 | 38 | while (key.hasMoreElements()) |
| 969 | { | |
| 970 | 36 | out.append("#=GF " + key.nextElement() + " " + val.nextElement()); |
| 971 | 36 | out.append(newline); |
| 972 | } | |
| 973 | } | |
| 974 | } | |
| 975 | ||
| 976 | // output database accessions | |
| 977 | 9 | if (dataRef != null) |
| 978 | { | |
| 979 | 2 | Enumeration en = dataRef.keys(); |
| 980 | 269 | while (en.hasMoreElements()) |
| 981 | { | |
| 982 | 267 | Object idd = en.nextElement(); |
| 983 | 267 | String type = (String) dataRef.remove(idd); |
| 984 | 267 | out.append(new Format("%-" + (maxid - 2) + "s") |
| 985 | .form("#=GS " + idd.toString() + " ")); | |
| 986 | 267 | if (type.contains("PFAM") || type.contains("RFAM")) |
| 987 | { | |
| 988 | ||
| 989 | 267 | out.append(" AC " + type.substring(type.indexOf(";") + 1)); |
| 990 | } | |
| 991 | else | |
| 992 | { | |
| 993 | 0 | out.append(" DR " + type + " "); |
| 994 | } | |
| 995 | 267 | out.append(newline); |
| 996 | } | |
| 997 | } | |
| 998 | ||
| 999 | // output annotations | |
| 1000 | 302 | while (i < s.length && s[i] != null) |
| 1001 | { | |
| 1002 | 293 | AlignmentAnnotation[] alAnot = s[i].getAnnotation(); |
| 1003 | 293 | if (alAnot != null) |
| 1004 | { | |
| 1005 | 83 | Annotation[] ann; |
| 1006 | 166 | for (int j = 0; j < alAnot.length; j++) |
| 1007 | { | |
| 1008 | ||
| 1009 | 83 | String key = type2id(alAnot[j].label); |
| 1010 | 83 | boolean isrna = alAnot[j].isValidStruc(); |
| 1011 | ||
| 1012 | 83 | if (isrna) |
| 1013 | { | |
| 1014 | // hardwire to secondary structure if there is RNA secondary | |
| 1015 | // structure on the annotation | |
| 1016 | 66 | key = "SS"; |
| 1017 | } | |
| 1018 | 83 | if (key == null) |
| 1019 | { | |
| 1020 | ||
| 1021 | 4 | continue; |
| 1022 | } | |
| 1023 | ||
| 1024 | // out.append("#=GR "); | |
| 1025 | 79 | out.append(new Format("%-" + maxid + "s").form( |
| 1026 | "#=GR " + printId(s[i], jvSuffix) + " " + key + " ")); | |
| 1027 | 79 | ann = alAnot[j].annotations; |
| 1028 | 79 | String seq = ""; |
| 1029 | 7982 | for (int k = 0; k < ann.length; k++) |
| 1030 | { | |
| 1031 | 7903 | seq += outputCharacter(key, k, isrna, ann, s[i]); |
| 1032 | } | |
| 1033 | 79 | out.append(seq); |
| 1034 | 79 | out.append(newline); |
| 1035 | } | |
| 1036 | } | |
| 1037 | ||
| 1038 | 293 | out.append(new Format("%-" + maxid + "s") |
| 1039 | .form(printId(s[i], jvSuffix) + " ")); | |
| 1040 | 293 | out.append(s[i].getSequenceAsString()); |
| 1041 | 293 | out.append(newline); |
| 1042 | 293 | i++; |
| 1043 | } | |
| 1044 | ||
| 1045 | // alignment annotation | |
| 1046 | 9 | AlignmentAnnotation aa; |
| 1047 | 9 | if (al.getAlignmentAnnotation() != null) |
| 1048 | { | |
| 1049 | 92 | for (int ia = 0; ia < al.getAlignmentAnnotation().length; ia++) |
| 1050 | { | |
| 1051 | 85 | aa = al.getAlignmentAnnotation()[ia]; |
| 1052 | 85 | if (aa.autoCalculated || !aa.visible || aa.sequenceRef != null) |
| 1053 | { | |
| 1054 | 81 | continue; |
| 1055 | } | |
| 1056 | 4 | String seq = ""; |
| 1057 | 4 | String label; |
| 1058 | 4 | String key = ""; |
| 1059 | 4 | if (aa.label.equals("seq")) |
| 1060 | { | |
| 1061 | 1 | label = "seq_cons"; |
| 1062 | } | |
| 1063 | else | |
| 1064 | { | |
| 1065 | 3 | key = type2id(aa.label.toLowerCase()); |
| 1066 | 3 | if (key == null) |
| 1067 | { | |
| 1068 | 0 | label = aa.label; |
| 1069 | } | |
| 1070 | else | |
| 1071 | { | |
| 1072 | 3 | label = key + "_cons"; |
| 1073 | } | |
| 1074 | } | |
| 1075 | 4 | if (label == null) |
| 1076 | { | |
| 1077 | 0 | label = aa.label; |
| 1078 | } | |
| 1079 | 4 | label = label.replace(" ", "_"); |
| 1080 | ||
| 1081 | 4 | out.append( |
| 1082 | new Format("%-" + maxid + "s").form("#=GC " + label + " ")); | |
| 1083 | 4 | boolean isrna = aa.isValidStruc(); |
| 1084 | 438 | for (int j = 0; j < aa.annotations.length; j++) |
| 1085 | { | |
| 1086 | 434 | seq += outputCharacter(key, j, isrna, aa.annotations, null); |
| 1087 | } | |
| 1088 | 4 | out.append(seq); |
| 1089 | 4 | out.append(newline); |
| 1090 | } | |
| 1091 | } | |
| 1092 | ||
| 1093 | 9 | out.append("//"); |
| 1094 | 9 | out.append(newline); |
| 1095 | ||
| 1096 | 9 | return out.toString(); |
| 1097 | } | |
| 1098 | ||
| 1099 | /** | |
| 1100 | * add an annotation character to the output row | |
| 1101 | * | |
| 1102 | * @param seq | |
| 1103 | * @param key | |
| 1104 | * @param k | |
| 1105 | * @param isrna | |
| 1106 | * @param ann | |
| 1107 | * @param sequenceI | |
| 1108 | */ | |
| 1109 | 8337 | private char outputCharacter(String key, int k, boolean isrna, |
| 1110 | Annotation[] ann, SequenceI sequenceI) | |
| 1111 | { | |
| 1112 | 8337 | char seq = ' '; |
| 1113 | 8337 | Annotation annot = ann[k]; |
| 1114 | 8337 | String ch = (annot == null) |
| 1115 | 2440 | ? ((sequenceI == null) ? "-" |
| 1116 | : Character.toString(sequenceI.getCharAt(k))) | |
| 1117 | : annot.displayCharacter; | |
| 1118 | 8337 | if (key != null && key.equals("SS")) |
| 1119 | { | |
| 1120 | 8120 | if (annot == null) |
| 1121 | { | |
| 1122 | // sensible gap character | |
| 1123 | 2440 | return ' '; |
| 1124 | } | |
| 1125 | else | |
| 1126 | { | |
| 1127 | // valid secondary structure AND no alternative label (e.g. ' B') | |
| 1128 | 5680 | if (annot.secondaryStructure > ' ' && ch.length() < 2) |
| 1129 | { | |
| 1130 | 3064 | return annot.secondaryStructure; |
| 1131 | } | |
| 1132 | } | |
| 1133 | } | |
| 1134 | ||
| 1135 | 2833 | if (ch.length() == 0) |
| 1136 | { | |
| 1137 | 0 | seq = '.'; |
| 1138 | } | |
| 1139 | 2833 | else if (ch.length() == 1) |
| 1140 | { | |
| 1141 | 450 | seq = ch.charAt(0); |
| 1142 | } | |
| 1143 | 2383 | else if (ch.length() > 1) |
| 1144 | { | |
| 1145 | 2383 | seq = ch.charAt(1); |
| 1146 | } | |
| 1147 | 2833 | return seq; |
| 1148 | } | |
| 1149 | ||
| 1150 | 0 | public String print() |
| 1151 | { | |
| 1152 | 0 | out = new StringBuffer(); |
| 1153 | 0 | out.append("# STOCKHOLM 1.0"); |
| 1154 | 0 | out.append(newline); |
| 1155 | 0 | print(getSeqsAsArray(), false); |
| 1156 | ||
| 1157 | 0 | out.append("//"); |
| 1158 | 0 | out.append(newline); |
| 1159 | 0 | return out.toString(); |
| 1160 | } | |
| 1161 | ||
| 1162 | private static Hashtable typeIds = null; | |
| 1163 | ||
| 1164 | 1 | static |
| 1165 | { | |
| 1166 | 1 | if (typeIds == null) |
| 1167 | { | |
| 1168 | 1 | typeIds = new Hashtable(); |
| 1169 | 1 | typeIds.put("SS", "Secondary Structure"); |
| 1170 | 1 | typeIds.put("SA", "Surface Accessibility"); |
| 1171 | 1 | typeIds.put("TM", "transmembrane"); |
| 1172 | 1 | typeIds.put("PP", "Posterior Probability"); |
| 1173 | 1 | typeIds.put("LI", "ligand binding"); |
| 1174 | 1 | typeIds.put("AS", "active site"); |
| 1175 | 1 | typeIds.put("IN", "intron"); |
| 1176 | 1 | typeIds.put("IR", "interacting residue"); |
| 1177 | 1 | typeIds.put("AC", "accession"); |
| 1178 | 1 | typeIds.put("OS", "organism"); |
| 1179 | 1 | typeIds.put("CL", "class"); |
| 1180 | 1 | typeIds.put("DE", "description"); |
| 1181 | 1 | typeIds.put("DR", "reference"); |
| 1182 | 1 | typeIds.put("LO", "look"); |
| 1183 | 1 | typeIds.put("RF", "Reference Positions"); |
| 1184 | ||
| 1185 | } | |
| 1186 | } | |
| 1187 | ||
| 1188 | 927 | protected static String id2type(String id) |
| 1189 | { | |
| 1190 | 927 | if (typeIds.containsKey(id)) |
| 1191 | { | |
| 1192 | 924 | return (String) typeIds.get(id); |
| 1193 | } | |
| 1194 | 3 | System.err.println( |
| 1195 | "Warning : Unknown Stockholm annotation type code " + id); | |
| 1196 | 3 | return id; |
| 1197 | } | |
| 1198 | ||
| 1199 | 391 | protected static String type2id(String type) |
| 1200 | { | |
| 1201 | 391 | String key = null; |
| 1202 | 391 | Enumeration e = typeIds.keys(); |
| 1203 | 4318 | while (e.hasMoreElements()) |
| 1204 | { | |
| 1205 | 4314 | Object ll = e.nextElement(); |
| 1206 | 4314 | if (typeIds.get(ll).toString().equalsIgnoreCase(type)) |
| 1207 | { | |
| 1208 | 387 | key = (String) ll; |
| 1209 | 387 | break; |
| 1210 | } | |
| 1211 | } | |
| 1212 | 391 | if (key != null) |
| 1213 | { | |
| 1214 | 387 | return key; |
| 1215 | } | |
| 1216 | 4 | System.err.println( |
| 1217 | "Warning : Unknown Stockholm annotation type: " + type); | |
| 1218 | 4 | return key; |
| 1219 | } | |
| 1220 | ||
| 1221 | /** | |
| 1222 | * make a friendly ID string. | |
| 1223 | * | |
| 1224 | * @param dataName | |
| 1225 | * @return truncated dataName to after last '/' | |
| 1226 | */ | |
| 1227 | 0 | private String safeName(String dataName) |
| 1228 | { | |
| 1229 | 0 | int b = 0; |
| 1230 | 0 | while ((b = dataName.indexOf("/")) > -1 && b < dataName.length()) |
| 1231 | { | |
| 1232 | 0 | dataName = dataName.substring(b + 1).trim(); |
| 1233 | ||
| 1234 | } | |
| 1235 | 0 | int e = (dataName.length() - dataName.indexOf(".")) + 1; |
| 1236 | 0 | dataName = dataName.substring(1, e).trim(); |
| 1237 | 0 | return dataName; |
| 1238 | } | |
| 1239 | } |