jalviewX
File EmblEntry.java
Coverage histogram
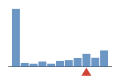
19% of files have more coverage
Classes
| Class | Line # | Actions | ||||
|---|---|---|---|---|---|---|
| EmblEntry | 55 | 232 | 94 | 81 |
Contributing tests
This file is covered by 4 tests.
.
Source view
| 1 | /* | |
| 2 | * Jalview - A Sequence Alignment Editor and Viewer ($$Version-Rel$$) | |
| 3 | * Copyright (C) $$Year-Rel$$ The Jalview Authors | |
| 4 | * | |
| 5 | * This file is part of Jalview. | |
| 6 | * | |
| 7 | * Jalview is free software: you can redistribute it and/or | |
| 8 | * modify it under the terms of the GNU General Public License | |
| 9 | * as published by the Free Software Foundation, either version 3 | |
| 10 | * of the License, or (at your option) any later version. | |
| 11 | * | |
| 12 | * Jalview is distributed in the hope that it will be useful, but | |
| 13 | * WITHOUT ANY WARRANTY; without even the implied warranty | |
| 14 | * of MERCHANTABILITY or FITNESS FOR A PARTICULAR | |
| 15 | * PURPOSE. See the GNU General Public License for more details. | |
| 16 | * | |
| 17 | * You should have received a copy of the GNU General Public License | |
| 18 | * along with Jalview. If not, see <http://www.gnu.org/licenses/>. | |
| 19 | * The Jalview Authors are detailed in the 'AUTHORS' file. | |
| 20 | */ | |
| 21 | package jalview.datamodel.xdb.embl; | |
| 22 | ||
| 23 | import jalview.analysis.SequenceIdMatcher; | |
| 24 | import jalview.bin.Cache; | |
| 25 | import jalview.datamodel.DBRefEntry; | |
| 26 | import jalview.datamodel.DBRefSource; | |
| 27 | import jalview.datamodel.FeatureProperties; | |
| 28 | import jalview.datamodel.Mapping; | |
| 29 | import jalview.datamodel.Sequence; | |
| 30 | import jalview.datamodel.SequenceFeature; | |
| 31 | import jalview.datamodel.SequenceI; | |
| 32 | import jalview.util.DBRefUtils; | |
| 33 | import jalview.util.DnaUtils; | |
| 34 | import jalview.util.MapList; | |
| 35 | import jalview.util.MappingUtils; | |
| 36 | import jalview.util.StringUtils; | |
| 37 | ||
| 38 | import java.text.ParseException; | |
| 39 | import java.util.Arrays; | |
| 40 | import java.util.Hashtable; | |
| 41 | import java.util.List; | |
| 42 | import java.util.Map; | |
| 43 | import java.util.Map.Entry; | |
| 44 | import java.util.Vector; | |
| 45 | import java.util.regex.Pattern; | |
| 46 | ||
| 47 | /** | |
| 48 | * Data model for one entry returned from an EMBL query, as marshalled by a | |
| 49 | * Castor binding file | |
| 50 | * | |
| 51 | * For example: http://www.ebi.ac.uk/ena/data/view/J03321&display=xml | |
| 52 | * | |
| 53 | * @see embl_mapping.xml | |
| 54 | */ | |
| 55 | public class EmblEntry | |
| 56 | { | |
| 57 | private static final Pattern SPACE_PATTERN = Pattern.compile(" "); | |
| 58 | ||
| 59 | String accession; | |
| 60 | ||
| 61 | String entryVersion; | |
| 62 | ||
| 63 | String sequenceVersion; | |
| 64 | ||
| 65 | String dataClass; | |
| 66 | ||
| 67 | String moleculeType; | |
| 68 | ||
| 69 | String topology; | |
| 70 | ||
| 71 | String sequenceLength; | |
| 72 | ||
| 73 | String taxonomicDivision; | |
| 74 | ||
| 75 | String description; | |
| 76 | ||
| 77 | String firstPublicDate; | |
| 78 | ||
| 79 | String firstPublicRelease; | |
| 80 | ||
| 81 | String lastUpdatedDate; | |
| 82 | ||
| 83 | String lastUpdatedRelease; | |
| 84 | ||
| 85 | Vector<String> keywords; | |
| 86 | ||
| 87 | Vector<DBRefEntry> dbRefs; | |
| 88 | ||
| 89 | Vector<EmblFeature> features; | |
| 90 | ||
| 91 | EmblSequence sequence; | |
| 92 | ||
| 93 | /** | |
| 94 | * @return the accession | |
| 95 | */ | |
| 96 | 6 |  public String getAccession() public String getAccession() |
| 97 | { | |
| 98 | 6 | return accession; |
| 99 | } | |
| 100 | ||
| 101 | /** | |
| 102 | * @param accession | |
| 103 | * the accession to set | |
| 104 | */ | |
| 105 | 2 | public void setAccession(String accession) |
| 106 | { | |
| 107 | 2 | this.accession = accession; |
| 108 | } | |
| 109 | ||
| 110 | /** | |
| 111 | * @return the dbRefs | |
| 112 | */ | |
| 113 | 14 | public Vector<DBRefEntry> getDbRefs() |
| 114 | { | |
| 115 | 14 | return dbRefs; |
| 116 | } | |
| 117 | ||
| 118 | /** | |
| 119 | * @param dbRefs | |
| 120 | * the dbRefs to set | |
| 121 | */ | |
| 122 | 2 | public void setDbRefs(Vector<DBRefEntry> dbRefs) |
| 123 | { | |
| 124 | 2 | this.dbRefs = dbRefs; |
| 125 | } | |
| 126 | ||
| 127 | /** | |
| 128 | * @return the features | |
| 129 | */ | |
| 130 | 18 | public Vector<EmblFeature> getFeatures() |
| 131 | { | |
| 132 | 18 | return features; |
| 133 | } | |
| 134 | ||
| 135 | /** | |
| 136 | * @param features | |
| 137 | * the features to set | |
| 138 | */ | |
| 139 | 2 | public void setFeatures(Vector<EmblFeature> features) |
| 140 | { | |
| 141 | 2 | this.features = features; |
| 142 | } | |
| 143 | ||
| 144 | /** | |
| 145 | * @return the keywords | |
| 146 | */ | |
| 147 | 9 | public Vector<String> getKeywords() |
| 148 | { | |
| 149 | 9 | return keywords; |
| 150 | } | |
| 151 | ||
| 152 | /** | |
| 153 | * @param keywords | |
| 154 | * the keywords to set | |
| 155 | */ | |
| 156 | 2 | public void setKeywords(Vector<String> keywords) |
| 157 | { | |
| 158 | 2 | this.keywords = keywords; |
| 159 | } | |
| 160 | ||
| 161 | /** | |
| 162 | * @return the sequence | |
| 163 | */ | |
| 164 | 3 | public EmblSequence getSequence() |
| 165 | { | |
| 166 | 3 | return sequence; |
| 167 | } | |
| 168 | ||
| 169 | /** | |
| 170 | * @param sequence | |
| 171 | * the sequence to set | |
| 172 | */ | |
| 173 | 2 | public void setSequence(EmblSequence sequence) |
| 174 | { | |
| 175 | 2 | this.sequence = sequence; |
| 176 | } | |
| 177 | ||
| 178 | /** | |
| 179 | * Recover annotated sequences from EMBL file | |
| 180 | * | |
| 181 | * @param sourceDb | |
| 182 | * @param peptides | |
| 183 | * a list of protein products found so far (to add to) | |
| 184 | * @return dna dataset sequence with DBRefs and features | |
| 185 | */ | |
| 186 | 0 | public SequenceI getSequence(String sourceDb, List<SequenceI> peptides) |
| 187 | { | |
| 188 | 0 | SequenceI dna = makeSequence(sourceDb); |
| 189 | 0 | if (dna == null) |
| 190 | { | |
| 191 | 0 | return null; |
| 192 | } | |
| 193 | 0 | dna.setDescription(description); |
| 194 | 0 | DBRefEntry retrievedref = new DBRefEntry(sourceDb, getSequenceVersion(), |
| 195 | accession); | |
| 196 | 0 | dna.addDBRef(retrievedref); |
| 197 | // add map to indicate the sequence is a valid coordinate frame for the | |
| 198 | // dbref | |
| 199 | 0 | retrievedref |
| 200 | .setMap(new Mapping(null, new int[] | |
| 201 | { 1, dna.getLength() }, new int[] { 1, dna.getLength() }, 1, | |
| 202 | 1)); | |
| 203 | ||
| 204 | /* | |
| 205 | * transform EMBL Database refs to canonical form | |
| 206 | */ | |
| 207 | 0 | if (dbRefs != null) |
| 208 | { | |
| 209 | 0 | for (DBRefEntry dbref : dbRefs) |
| 210 | { | |
| 211 | 0 | dbref.setSource(DBRefUtils.getCanonicalName(dbref.getSource())); |
| 212 | 0 | dna.addDBRef(dbref); |
| 213 | } | |
| 214 | } | |
| 215 | ||
| 216 | 0 | SequenceIdMatcher matcher = new SequenceIdMatcher(peptides); |
| 217 | 0 | try |
| 218 | { | |
| 219 | 0 | for (EmblFeature feature : features) |
| 220 | { | |
| 221 | 0 | if (FeatureProperties.isCodingFeature(sourceDb, feature.getName())) |
| 222 | { | |
| 223 | 0 | parseCodingFeature(feature, sourceDb, dna, peptides, matcher); |
| 224 | } | |
| 225 | } | |
| 226 | } catch (Exception e) | |
| 227 | { | |
| 228 | 0 | System.err.println("EMBL Record Features parsing error!"); |
| 229 | 0 | System.err |
| 230 | .println("Please report the following to help@jalview.org :"); | |
| 231 | 0 | System.err.println("EMBL Record " + accession); |
| 232 | 0 | System.err.println("Resulted in exception: " + e.getMessage()); |
| 233 | 0 | e.printStackTrace(System.err); |
| 234 | } | |
| 235 | ||
| 236 | 0 | return dna; |
| 237 | } | |
| 238 | ||
| 239 | /** | |
| 240 | * @param sourceDb | |
| 241 | * @return | |
| 242 | */ | |
| 243 | 1 | SequenceI makeSequence(String sourceDb) |
| 244 | { | |
| 245 | 1 | if (sequence == null) |
| 246 | { | |
| 247 | 0 | System.err.println( |
| 248 | "No sequence was returned for ENA accession " + accession); | |
| 249 | 0 | return null; |
| 250 | } | |
| 251 | 1 | SequenceI dna = new Sequence(sourceDb + "|" + accession, |
| 252 | sequence.getSequence()); | |
| 253 | 1 | return dna; |
| 254 | } | |
| 255 | ||
| 256 | /** | |
| 257 | * Extracts coding region and product from a CDS feature and properly decorate | |
| 258 | * it with annotations. | |
| 259 | * | |
| 260 | * @param feature | |
| 261 | * coding feature | |
| 262 | * @param sourceDb | |
| 263 | * source database for the EMBLXML | |
| 264 | * @param dna | |
| 265 | * parent dna sequence for this record | |
| 266 | * @param peptides | |
| 267 | * list of protein product sequences for Embl entry | |
| 268 | * @param matcher | |
| 269 | * helper to match xrefs in already retrieved sequences | |
| 270 | */ | |
| 271 | 3 | void parseCodingFeature(EmblFeature feature, String sourceDb, |
| 272 | SequenceI dna, List<SequenceI> peptides, | |
| 273 | SequenceIdMatcher matcher) | |
| 274 | { | |
| 275 | 3 | boolean isEmblCdna = sourceDb.equals(DBRefSource.EMBLCDS); |
| 276 | ||
| 277 | 3 | int[] exons = getCdsRanges(feature); |
| 278 | ||
| 279 | 3 | String translation = null; |
| 280 | 3 | String proteinName = ""; |
| 281 | 3 | String proteinId = null; |
| 282 | 3 | Map<String, String> vals = new Hashtable<>(); |
| 283 | ||
| 284 | /* | |
| 285 | * codon_start 1/2/3 in EMBL corresponds to phase 0/1/2 in CDS | |
| 286 | * (phase is required for CDS features in GFF3 format) | |
| 287 | */ | |
| 288 | 3 | int codonStart = 1; |
| 289 | ||
| 290 | /* | |
| 291 | * parse qualifiers, saving protein translation, protein id, | |
| 292 | * codon start position, product (name), and 'other values' | |
| 293 | */ | |
| 294 | 3 | if (feature.getQualifiers() != null) |
| 295 | { | |
| 296 | 3 | for (Qualifier q : feature.getQualifiers()) |
| 297 | { | |
| 298 | 7 | String qname = q.getName(); |
| 299 | 7 | if (qname.equals("translation")) |
| 300 | { | |
| 301 | // remove all spaces (precompiled String.replaceAll(" ", "")) | |
| 302 | 3 | translation = SPACE_PATTERN.matcher(q.getValues()[0]) |
| 303 | .replaceAll(""); | |
| 304 | } | |
| 305 | 4 | else if (qname.equals("protein_id")) |
| 306 | { | |
| 307 | 3 | proteinId = q.getValues()[0].trim(); |
| 308 | } | |
| 309 | 1 | else if (qname.equals("codon_start")) |
| 310 | { | |
| 311 | 0 | try |
| 312 | { | |
| 313 | 0 | codonStart = Integer.parseInt(q.getValues()[0].trim()); |
| 314 | } catch (NumberFormatException e) | |
| 315 | { | |
| 316 | 0 | System.err.println("Invalid codon_start in XML for " + accession |
| 317 | + ": " + e.getMessage()); | |
| 318 | } | |
| 319 | } | |
| 320 | 1 | else if (qname.equals("product")) |
| 321 | { | |
| 322 | // sometimes name is returned e.g. for V00488 | |
| 323 | 0 | proteinName = q.getValues()[0].trim(); |
| 324 | } | |
| 325 | else | |
| 326 | { | |
| 327 | // throw anything else into the additional properties hash | |
| 328 | 1 | String[] qvals = q.getValues(); |
| 329 | 1 | if (qvals != null) |
| 330 | { | |
| 331 | 1 | String commaSeparated = StringUtils.arrayToSeparatorList(qvals, |
| 332 | ","); | |
| 333 | 1 | vals.put(qname, commaSeparated); |
| 334 | } | |
| 335 | } | |
| 336 | } | |
| 337 | } | |
| 338 | ||
| 339 | 3 | DBRefEntry proteinToEmblProteinRef = null; |
| 340 | 3 | exons = MappingUtils.removeStartPositions(codonStart - 1, exons); |
| 341 | ||
| 342 | 3 | SequenceI product = null; |
| 343 | 3 | Mapping dnaToProteinMapping = null; |
| 344 | 3 | if (translation != null && proteinName != null && proteinId != null) |
| 345 | { | |
| 346 | 3 | int translationLength = translation.length(); |
| 347 | ||
| 348 | /* | |
| 349 | * look for product in peptides list, if not found, add it | |
| 350 | */ | |
| 351 | 3 | product = matcher.findIdMatch(proteinId); |
| 352 | 3 | if (product == null) |
| 353 | { | |
| 354 | 3 | product = new Sequence(proteinId, translation, 1, |
| 355 | translationLength); | |
| 356 | 3 | product.setDescription(((proteinName.length() == 0) |
| 357 | ? "Protein Product from " + sourceDb | |
| 358 | : proteinName)); | |
| 359 | 3 | peptides.add(product); |
| 360 | 3 | matcher.add(product); |
| 361 | } | |
| 362 | ||
| 363 | // we have everything - create the mapping and perhaps the protein | |
| 364 | // sequence | |
| 365 | 3 | if (exons == null || exons.length == 0) |
| 366 | { | |
| 367 | /* | |
| 368 | * workaround until we handle dna location for CDS sequence | |
| 369 | * e.g. location="X53828.1:60..1058" correctly | |
| 370 | */ | |
| 371 | 0 | System.err.println( |
| 372 | "Implementation Notice: EMBLCDS records not properly supported yet - Making up the CDNA region of this sequence... may be incorrect (" | |
| 373 | + sourceDb + ":" + getAccession() + ")"); | |
| 374 | 0 | int dnaLength = dna.getLength(); |
| 375 | 0 | if (translationLength * 3 == (1 - codonStart + dnaLength)) |
| 376 | { | |
| 377 | 0 | System.err.println( |
| 378 | "Not allowing for additional stop codon at end of cDNA fragment... !"); | |
| 379 | // this might occur for CDS sequences where no features are marked | |
| 380 | 0 | exons = new int[] { dna.getStart() + (codonStart - 1), |
| 381 | dna.getEnd() }; | |
| 382 | 0 | dnaToProteinMapping = new Mapping(product, exons, |
| 383 | new int[] | |
| 384 | { 1, translationLength }, 3, 1); | |
| 385 | } | |
| 386 | 0 | if ((translationLength + 1) * 3 == (1 - codonStart + dnaLength)) |
| 387 | { | |
| 388 | 0 | System.err.println( |
| 389 | "Allowing for additional stop codon at end of cDNA fragment... will probably cause an error in VAMSAs!"); | |
| 390 | 0 | exons = new int[] { dna.getStart() + (codonStart - 1), |
| 391 | dna.getEnd() - 3 }; | |
| 392 | 0 | dnaToProteinMapping = new Mapping(product, exons, |
| 393 | new int[] | |
| 394 | { 1, translationLength }, 3, 1); | |
| 395 | } | |
| 396 | } | |
| 397 | else | |
| 398 | { | |
| 399 | // Trim the exon mapping if necessary - the given product may only be a | |
| 400 | // fragment of a larger protein. (EMBL:AY043181 is an example) | |
| 401 | ||
| 402 | 3 | if (isEmblCdna) |
| 403 | { | |
| 404 | // TODO: Add a DbRef back to the parent EMBL sequence with the exon | |
| 405 | // map | |
| 406 | // if given a dataset reference, search dataset for parent EMBL | |
| 407 | // sequence if it exists and set its map | |
| 408 | // make a new feature annotating the coding contig | |
| 409 | } | |
| 410 | else | |
| 411 | { | |
| 412 | // final product length truncation check | |
| 413 | 3 | int[] cdsRanges = adjustForProteinLength(translationLength, |
| 414 | exons); | |
| 415 | 3 | dnaToProteinMapping = new Mapping(product, cdsRanges, |
| 416 | new int[] | |
| 417 | { 1, translationLength }, 3, 1); | |
| 418 | 3 | if (product != null) |
| 419 | { | |
| 420 | /* | |
| 421 | * make xref with mapping from protein to EMBL dna | |
| 422 | */ | |
| 423 | 3 | DBRefEntry proteinToEmblRef = new DBRefEntry(DBRefSource.EMBL, |
| 424 | getSequenceVersion(), proteinId, | |
| 425 | new Mapping(dnaToProteinMapping.getMap().getInverse())); | |
| 426 | 3 | product.addDBRef(proteinToEmblRef); |
| 427 | ||
| 428 | /* | |
| 429 | * make xref from protein to EMBLCDS; we assume here that the | |
| 430 | * CDS sequence version is same as dna sequence (?!) | |
| 431 | */ | |
| 432 | 3 | MapList proteinToCdsMapList = new MapList( |
| 433 | new int[] | |
| 434 | { 1, translationLength }, | |
| 435 | new int[] | |
| 436 | { 1 + (codonStart - 1), | |
| 437 | (codonStart - 1) + 3 * translationLength }, | |
| 438 | 1, 3); | |
| 439 | 3 | DBRefEntry proteinToEmblCdsRef = new DBRefEntry( |
| 440 | DBRefSource.EMBLCDS, getSequenceVersion(), proteinId, | |
| 441 | new Mapping(proteinToCdsMapList)); | |
| 442 | 3 | product.addDBRef(proteinToEmblCdsRef); |
| 443 | ||
| 444 | /* | |
| 445 | * make 'direct' xref from protein to EMBLCDSPROTEIN | |
| 446 | */ | |
| 447 | 3 | proteinToEmblProteinRef = new DBRefEntry(proteinToEmblCdsRef); |
| 448 | 3 | proteinToEmblProteinRef.setSource(DBRefSource.EMBLCDSProduct); |
| 449 | 3 | proteinToEmblProteinRef.setMap(null); |
| 450 | 3 | product.addDBRef(proteinToEmblProteinRef); |
| 451 | } | |
| 452 | } | |
| 453 | } | |
| 454 | ||
| 455 | /* | |
| 456 | * add cds features to dna sequence | |
| 457 | */ | |
| 458 | 3 | String cds = feature.getName(); // "CDS" |
| 459 | 7 | for (int xint = 0; exons != null && xint < exons.length - 1; xint += 2) |
| 460 | { | |
| 461 | 4 | int exonStart = exons[xint]; |
| 462 | 4 | int exonEnd = exons[xint + 1]; |
| 463 | 4 | int begin = Math.min(exonStart, exonEnd); |
| 464 | 4 | int end = Math.max(exonStart, exonEnd); |
| 465 | 4 | int exonNumber = xint / 2 + 1; |
| 466 | 4 | String desc = String.format("Exon %d for protein '%s' EMBLCDS:%s", |
| 467 | exonNumber, proteinName, proteinId); | |
| 468 | ||
| 469 | 4 | SequenceFeature sf = makeCdsFeature(cds, desc, begin, end, |
| 470 | sourceDb, vals); | |
| 471 | ||
| 472 | 4 | sf.setEnaLocation(feature.getLocation()); |
| 473 | 4 | boolean forwardStrand = exonStart <= exonEnd; |
| 474 | 4 | sf.setStrand(forwardStrand ? "+" : "-"); |
| 475 | 4 | sf.setPhase(String.valueOf(codonStart - 1)); |
| 476 | 4 | sf.setValue(FeatureProperties.EXONPOS, exonNumber); |
| 477 | 4 | sf.setValue(FeatureProperties.EXONPRODUCT, proteinName); |
| 478 | ||
| 479 | 4 | dna.addSequenceFeature(sf); |
| 480 | } | |
| 481 | } | |
| 482 | ||
| 483 | /* | |
| 484 | * add feature dbRefs to sequence, and mappings for Uniprot xrefs | |
| 485 | */ | |
| 486 | 3 | boolean hasUniprotDbref = false; |
| 487 | 3 | if (feature.dbRefs != null) |
| 488 | { | |
| 489 | 2 | boolean mappingUsed = false; |
| 490 | 2 | for (DBRefEntry ref : feature.dbRefs) |
| 491 | { | |
| 492 | /* | |
| 493 | * ensure UniProtKB/Swiss-Prot converted to UNIPROT | |
| 494 | */ | |
| 495 | 3 | String source = DBRefUtils.getCanonicalName(ref.getSource()); |
| 496 | 3 | ref.setSource(source); |
| 497 | 3 | DBRefEntry proteinDbRef = new DBRefEntry(ref.getSource(), |
| 498 | ref.getVersion(), ref.getAccessionId()); | |
| 499 | 3 | if (source.equals(DBRefSource.UNIPROT)) |
| 500 | { | |
| 501 | 3 | String proteinSeqName = DBRefSource.UNIPROT + "|" |
| 502 | + ref.getAccessionId(); | |
| 503 | 3 | if (dnaToProteinMapping != null |
| 504 | && dnaToProteinMapping.getTo() != null) | |
| 505 | { | |
| 506 | 3 | if (mappingUsed) |
| 507 | { | |
| 508 | /* | |
| 509 | * two or more Uniprot xrefs for the same CDS - | |
| 510 | * each needs a distinct Mapping (as to a different sequence) | |
| 511 | */ | |
| 512 | 1 | dnaToProteinMapping = new Mapping(dnaToProteinMapping); |
| 513 | } | |
| 514 | 3 | mappingUsed = true; |
| 515 | ||
| 516 | /* | |
| 517 | * try to locate the protein mapped to (possibly by a | |
| 518 | * previous CDS feature); if not found, construct it from | |
| 519 | * the EMBL translation | |
| 520 | */ | |
| 521 | 3 | SequenceI proteinSeq = matcher.findIdMatch(proteinSeqName); |
| 522 | 3 | if (proteinSeq == null) |
| 523 | { | |
| 524 | 3 | proteinSeq = new Sequence(proteinSeqName, |
| 525 | product.getSequenceAsString()); | |
| 526 | 3 | matcher.add(proteinSeq); |
| 527 | 3 | peptides.add(proteinSeq); |
| 528 | } | |
| 529 | 3 | dnaToProteinMapping.setTo(proteinSeq); |
| 530 | 3 | dnaToProteinMapping.setMappedFromId(proteinId); |
| 531 | 3 | proteinSeq.addDBRef(proteinDbRef); |
| 532 | 3 | ref.setMap(dnaToProteinMapping); |
| 533 | } | |
| 534 | 3 | hasUniprotDbref = true; |
| 535 | } | |
| 536 | 3 | if (product != null) |
| 537 | { | |
| 538 | /* | |
| 539 | * copy feature dbref to our protein product | |
| 540 | */ | |
| 541 | 3 | DBRefEntry pref = proteinDbRef; |
| 542 | 3 | pref.setMap(null); // reference is direct |
| 543 | 3 | product.addDBRef(pref); |
| 544 | // Add converse mapping reference | |
| 545 | 3 | if (dnaToProteinMapping != null) |
| 546 | { | |
| 547 | 3 | Mapping pmap = new Mapping(dna, |
| 548 | dnaToProteinMapping.getMap().getInverse()); | |
| 549 | 3 | pref = new DBRefEntry(sourceDb, getSequenceVersion(), |
| 550 | this.getAccession()); | |
| 551 | 3 | pref.setMap(pmap); |
| 552 | 3 | if (dnaToProteinMapping.getTo() != null) |
| 553 | { | |
| 554 | 3 | dnaToProteinMapping.getTo().addDBRef(pref); |
| 555 | } | |
| 556 | } | |
| 557 | } | |
| 558 | 3 | dna.addDBRef(ref); |
| 559 | } | |
| 560 | } | |
| 561 | ||
| 562 | /* | |
| 563 | * if we have a product (translation) but no explicit Uniprot dbref | |
| 564 | * (example: EMBL AAFI02000057 protein_id EAL65544.1) | |
| 565 | * then construct mappings to an assumed EMBLCDSPROTEIN accession | |
| 566 | */ | |
| 567 | 3 | if (!hasUniprotDbref && product != null) |
| 568 | { | |
| 569 | 1 | if (proteinToEmblProteinRef == null) |
| 570 | { | |
| 571 | // assuming CDSPROTEIN sequence version = dna version (?!) | |
| 572 | 0 | proteinToEmblProteinRef = new DBRefEntry(DBRefSource.EMBLCDSProduct, |
| 573 | getSequenceVersion(), proteinId); | |
| 574 | } | |
| 575 | 1 | product.addDBRef(proteinToEmblProteinRef); |
| 576 | ||
| 577 | 1 | if (dnaToProteinMapping != null |
| 578 | && dnaToProteinMapping.getTo() != null) | |
| 579 | { | |
| 580 | 1 | DBRefEntry dnaToEmblProteinRef = new DBRefEntry( |
| 581 | DBRefSource.EMBLCDSProduct, getSequenceVersion(), | |
| 582 | proteinId); | |
| 583 | 1 | dnaToEmblProteinRef.setMap(dnaToProteinMapping); |
| 584 | 1 | dnaToProteinMapping.setMappedFromId(proteinId); |
| 585 | 1 | dna.addDBRef(dnaToEmblProteinRef); |
| 586 | } | |
| 587 | } | |
| 588 | } | |
| 589 | ||
| 590 | /** | |
| 591 | * Helper method to construct a SequenceFeature for one cds range | |
| 592 | * | |
| 593 | * @param type | |
| 594 | * feature type ("CDS") | |
| 595 | * @param desc | |
| 596 | * description | |
| 597 | * @param begin | |
| 598 | * start position | |
| 599 | * @param end | |
| 600 | * end position | |
| 601 | * @param group | |
| 602 | * feature group | |
| 603 | * @param vals | |
| 604 | * map of 'miscellaneous values' for feature | |
| 605 | * @return | |
| 606 | */ | |
| 607 | 4 | protected SequenceFeature makeCdsFeature(String type, String desc, |
| 608 | int begin, int end, String group, Map<String, String> vals) | |
| 609 | { | |
| 610 | 4 | SequenceFeature sf = new SequenceFeature(type, desc, begin, end, group); |
| 611 | 4 | if (!vals.isEmpty()) |
| 612 | { | |
| 613 | 1 | StringBuilder sb = new StringBuilder(); |
| 614 | 1 | boolean first = true; |
| 615 | 1 | for (Entry<String, String> val : vals.entrySet()) |
| 616 | { | |
| 617 | 1 | if (!first) |
| 618 | { | |
| 619 | 0 | sb.append(";"); |
| 620 | } | |
| 621 | 1 | sb.append(val.getKey()).append("=").append(val.getValue()); |
| 622 | 1 | first = false; |
| 623 | 1 | sf.setValue(val.getKey(), val.getValue()); |
| 624 | } | |
| 625 | 1 | sf.setAttributes(sb.toString()); |
| 626 | } | |
| 627 | 4 | return sf; |
| 628 | } | |
| 629 | ||
| 630 | /** | |
| 631 | * Returns the CDS positions as a single array of [start, end, start, end...] | |
| 632 | * positions. If on the reverse strand, these will be in descending order. | |
| 633 | * | |
| 634 | * @param feature | |
| 635 | * @return | |
| 636 | */ | |
| 637 | 4 | protected int[] getCdsRanges(EmblFeature feature) |
| 638 | { | |
| 639 | 4 | if (feature.location == null) |
| 640 | { | |
| 641 | 0 | return new int[] {}; |
| 642 | } | |
| 643 | ||
| 644 | 4 | try |
| 645 | { | |
| 646 | 4 | List<int[]> ranges = DnaUtils.parseLocation(feature.location); |
| 647 | 4 | return listToArray(ranges); |
| 648 | } catch (ParseException e) | |
| 649 | { | |
| 650 | 0 | Cache.log.warn( |
| 651 | String.format("Not parsing inexact CDS location %s in ENA %s", | |
| 652 | feature.location, this.accession)); | |
| 653 | 0 | return new int[] {}; |
| 654 | } | |
| 655 | } | |
| 656 | ||
| 657 | /** | |
| 658 | * Converts a list of [start, end] ranges to a single array of [start, end, | |
| 659 | * start, end ...] | |
| 660 | * | |
| 661 | * @param ranges | |
| 662 | * @return | |
| 663 | */ | |
| 664 | 4 | int[] listToArray(List<int[]> ranges) |
| 665 | { | |
| 666 | 4 | int[] result = new int[ranges.size() * 2]; |
| 667 | 4 | int i = 0; |
| 668 | 4 | for (int[] range : ranges) |
| 669 | { | |
| 670 | 9 | result[i++] = range[0]; |
| 671 | 9 | result[i++] = range[1]; |
| 672 | } | |
| 673 | 4 | return result; |
| 674 | } | |
| 675 | ||
| 676 | /** | |
| 677 | * Truncates (if necessary) the exon intervals to match 3 times the length of | |
| 678 | * the protein; also accepts 3 bases longer (for stop codon not included in | |
| 679 | * protein) | |
| 680 | * | |
| 681 | * @param proteinLength | |
| 682 | * @param exon | |
| 683 | * an array of [start, end, start, end...] intervals | |
| 684 | * @return the same array (if unchanged) or a truncated copy | |
| 685 | */ | |
| 686 | 9 | static int[] adjustForProteinLength(int proteinLength, int[] exon) |
| 687 | { | |
| 688 | 9 | if (proteinLength <= 0 || exon == null) |
| 689 | { | |
| 690 | 0 | return exon; |
| 691 | } | |
| 692 | 9 | int expectedCdsLength = proteinLength * 3; |
| 693 | 9 | int exonLength = MappingUtils.getLength(Arrays.asList(exon)); |
| 694 | ||
| 695 | /* | |
| 696 | * if exon length matches protein, or is shorter, or longer by the | |
| 697 | * length of a stop codon (3 bases), then leave it unchanged | |
| 698 | */ | |
| 699 | 9 | if (expectedCdsLength >= exonLength |
| 700 | || expectedCdsLength == exonLength - 3) | |
| 701 | { | |
| 702 | 6 | return exon; |
| 703 | } | |
| 704 | ||
| 705 | 3 | int origxon[]; |
| 706 | 3 | int sxpos = -1; |
| 707 | 3 | int endxon = 0; |
| 708 | 3 | origxon = new int[exon.length]; |
| 709 | 3 | System.arraycopy(exon, 0, origxon, 0, exon.length); |
| 710 | 3 | int cdspos = 0; |
| 711 | 7 | for (int x = 0; x < exon.length; x += 2) |
| 712 | { | |
| 713 | 7 | cdspos += Math.abs(exon[x + 1] - exon[x]) + 1; |
| 714 | 7 | if (expectedCdsLength <= cdspos) |
| 715 | { | |
| 716 | // advanced beyond last codon. | |
| 717 | 3 | sxpos = x; |
| 718 | 3 | if (expectedCdsLength != cdspos) |
| 719 | { | |
| 720 | // System.err | |
| 721 | // .println("Truncating final exon interval on region by " | |
| 722 | // + (cdspos - cdslength)); | |
| 723 | } | |
| 724 | ||
| 725 | /* | |
| 726 | * shrink the final exon - reduce end position if forward | |
| 727 | * strand, increase it if reverse | |
| 728 | */ | |
| 729 | 3 | if (exon[x + 1] >= exon[x]) |
| 730 | { | |
| 731 | 3 | endxon = exon[x + 1] - cdspos + expectedCdsLength; |
| 732 | } | |
| 733 | else | |
| 734 | { | |
| 735 | 0 | endxon = exon[x + 1] + cdspos - expectedCdsLength; |
| 736 | } | |
| 737 | 3 | break; |
| 738 | } | |
| 739 | } | |
| 740 | ||
| 741 | 3 | if (sxpos != -1) |
| 742 | { | |
| 743 | // and trim the exon interval set if necessary | |
| 744 | 3 | int[] nxon = new int[sxpos + 2]; |
| 745 | 3 | System.arraycopy(exon, 0, nxon, 0, sxpos + 2); |
| 746 | 3 | nxon[sxpos + 1] = endxon; // update the end boundary for the new exon |
| 747 | // set | |
| 748 | 3 | exon = nxon; |
| 749 | } | |
| 750 | 3 | return exon; |
| 751 | } | |
| 752 | ||
| 753 | 13 | public String getSequenceVersion() |
| 754 | { | |
| 755 | 13 | return sequenceVersion; |
| 756 | } | |
| 757 | ||
| 758 | 2 | public void setSequenceVersion(String sequenceVersion) |
| 759 | { | |
| 760 | 2 | this.sequenceVersion = sequenceVersion; |
| 761 | } | |
| 762 | ||
| 763 | 3 | public String getSequenceLength() |
| 764 | { | |
| 765 | 3 | return sequenceLength; |
| 766 | } | |
| 767 | ||
| 768 | 2 | public void setSequenceLength(String sequenceLength) |
| 769 | { | |
| 770 | 2 | this.sequenceLength = sequenceLength; |
| 771 | } | |
| 772 | ||
| 773 | 3 | public String getEntryVersion() |
| 774 | { | |
| 775 | 3 | return entryVersion; |
| 776 | } | |
| 777 | ||
| 778 | 2 | public void setEntryVersion(String entryVersion) |
| 779 | { | |
| 780 | 2 | this.entryVersion = entryVersion; |
| 781 | } | |
| 782 | ||
| 783 | 3 | public String getMoleculeType() |
| 784 | { | |
| 785 | 3 | return moleculeType; |
| 786 | } | |
| 787 | ||
| 788 | 2 | public void setMoleculeType(String moleculeType) |
| 789 | { | |
| 790 | 2 | this.moleculeType = moleculeType; |
| 791 | } | |
| 792 | ||
| 793 | 3 | public String getTopology() |
| 794 | { | |
| 795 | 3 | return topology; |
| 796 | } | |
| 797 | ||
| 798 | 2 | public void setTopology(String topology) |
| 799 | { | |
| 800 | 2 | this.topology = topology; |
| 801 | } | |
| 802 | ||
| 803 | 3 | public String getTaxonomicDivision() |
| 804 | { | |
| 805 | 3 | return taxonomicDivision; |
| 806 | } | |
| 807 | ||
| 808 | 2 | public void setTaxonomicDivision(String taxonomicDivision) |
| 809 | { | |
| 810 | 2 | this.taxonomicDivision = taxonomicDivision; |
| 811 | } | |
| 812 | ||
| 813 | 3 | public String getDescription() |
| 814 | { | |
| 815 | 3 | return description; |
| 816 | } | |
| 817 | ||
| 818 | 2 | public void setDescription(String description) |
| 819 | { | |
| 820 | 2 | this.description = description; |
| 821 | } | |
| 822 | ||
| 823 | 4 | public String getFirstPublicDate() |
| 824 | { | |
| 825 | 4 | return firstPublicDate; |
| 826 | } | |
| 827 | ||
| 828 | 2 | public void setFirstPublicDate(String firstPublicDate) |
| 829 | { | |
| 830 | 2 | this.firstPublicDate = firstPublicDate; |
| 831 | } | |
| 832 | ||
| 833 | 4 | public String getFirstPublicRelease() |
| 834 | { | |
| 835 | 4 | return firstPublicRelease; |
| 836 | } | |
| 837 | ||
| 838 | 2 | public void setFirstPublicRelease(String firstPublicRelease) |
| 839 | { | |
| 840 | 2 | this.firstPublicRelease = firstPublicRelease; |
| 841 | } | |
| 842 | ||
| 843 | 3 | public String getLastUpdatedDate() |
| 844 | { | |
| 845 | 3 | return lastUpdatedDate; |
| 846 | } | |
| 847 | ||
| 848 | 2 | public void setLastUpdatedDate(String lastUpdatedDate) |
| 849 | { | |
| 850 | 2 | this.lastUpdatedDate = lastUpdatedDate; |
| 851 | } | |
| 852 | ||
| 853 | 3 | public String getLastUpdatedRelease() |
| 854 | { | |
| 855 | 3 | return lastUpdatedRelease; |
| 856 | } | |
| 857 | ||
| 858 | 2 | public void setLastUpdatedRelease(String lastUpdatedRelease) |
| 859 | { | |
| 860 | 2 | this.lastUpdatedRelease = lastUpdatedRelease; |
| 861 | } | |
| 862 | ||
| 863 | 3 | public String getDataClass() |
| 864 | { | |
| 865 | 3 | return dataClass; |
| 866 | } | |
| 867 | ||
| 868 | 2 | public void setDataClass(String dataClass) |
| 869 | { | |
| 870 | 2 | this.dataClass = dataClass; |
| 871 | } | |
| 872 | } |