Coverage Report
File SecondaryStructureDistanceModel.java
Coverage histogram
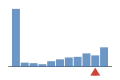
13% of files have more coverage
Classes
| Class | Line # | Actions | |||
|---|---|---|---|---|---|
| SecondaryStructureDistanceModel | 47 | 104 | 47 |
Contributing tests
This file is covered by 12 tests.
.
Source view
| 1 | /* | |
| 2 | * Jalview - A Sequence Alignment Editor and Viewer ($$Version-Rel$$) | |
| 3 | * Copyright (C) $$Year-Rel$$ The Jalview Authors | |
| 4 | * | |
| 5 | * This file is part of Jalview. | |
| 6 | * | |
| 7 | * Jalview is free software: you can redistribute it and/or | |
| 8 | * modify it under the terms of the GNU General Public License | |
| 9 | * as published by the Free Software Foundation, either version 3 | |
| 10 | * of the License, or (at your option) any later version. | |
| 11 | * | |
| 12 | * Jalview is distributed in the hope that it will be useful, but | |
| 13 | * WITHOUT ANY WARRANTY; without even the implied warranty | |
| 14 | * of MERCHANTABILITY or FITNESS FOR A PARTICULAR | |
| 15 | * PURPOSE. See the GNU General Public License for more details. | |
| 16 | * | |
| 17 | * You should have received a copy of the GNU General Public License | |
| 18 | * along with Jalview. If not, see <http://www.gnu.org/licenses/>. | |
| 19 | * The Jalview Authors are detailed in the 'AUTHORS' file. | |
| 20 | */ | |
| 21 | package jalview.analysis.scoremodels; | |
| 22 | ||
| 23 | import jalview.analysis.AlignmentAnnotationUtils; | |
| 24 | import jalview.analysis.AlignmentUtils; | |
| 25 | import jalview.api.AlignmentViewPanel; | |
| 26 | import jalview.api.FeatureRenderer; | |
| 27 | import jalview.api.analysis.ScoreModelI; | |
| 28 | import jalview.api.analysis.SimilarityParamsI; | |
| 29 | import jalview.datamodel.AlignmentAnnotation; | |
| 30 | import jalview.datamodel.AlignmentView; | |
| 31 | import jalview.datamodel.SeqCigar; | |
| 32 | import jalview.datamodel.SequenceI; | |
| 33 | import jalview.math.Matrix; | |
| 34 | import jalview.math.MatrixI; | |
| 35 | import jalview.util.Constants; | |
| 36 | ||
| 37 | import java.util.ArrayList; | |
| 38 | import java.util.HashMap; | |
| 39 | import java.util.HashSet; | |
| 40 | import java.util.List; | |
| 41 | import java.util.Map; | |
| 42 | import java.util.Set; | |
| 43 | ||
| 44 | /* This class contains methods to calculate distance score between | |
| 45 | * secondary structure annotations of the sequences. | |
| 46 | */ | |
| 47 | public class SecondaryStructureDistanceModel extends DistanceScoreModel | |
| 48 | { | |
| 49 | private static final String NAME = "Secondary Structure Similarity"; | |
| 50 | ||
| 51 | private ScoreMatrix ssRateMatrix; | |
| 52 | ||
| 53 | private String description; | |
| 54 | ||
| 55 | FeatureRenderer fr; | |
| 56 | ||
| 57 | /** | |
| 58 | * Constructor | |
| 59 | */ | |
| 60 | 88 |  public SecondaryStructureDistanceModel() public SecondaryStructureDistanceModel() |
| 61 | { | |
| 62 | ||
| 63 | } | |
| 64 | ||
| 65 | 8 | @Override |
| 66 | public ScoreModelI getInstance(AlignmentViewPanel view) | |
| 67 | { | |
| 68 | 8 | SecondaryStructureDistanceModel instance; |
| 69 | 8 | try |
| 70 | { | |
| 71 | 8 | instance = this.getClass().getDeclaredConstructor().newInstance(); |
| 72 | 8 | instance.configureFromAlignmentView(view); |
| 73 | 8 | return instance; |
| 74 | } catch (InstantiationException | IllegalAccessException e) | |
| 75 | { | |
| 76 | 0 | jalview.bin.Console.errPrintln("Error in " + getClass().getName() |
| 77 | + ".getInstance(): " + e.getMessage()); | |
| 78 | 0 | return null; |
| 79 | } catch (ReflectiveOperationException roe) | |
| 80 | { | |
| 81 | 0 | return null; |
| 82 | } | |
| 83 | } | |
| 84 | ||
| 85 | 8 | boolean configureFromAlignmentView(AlignmentViewPanel view) |
| 86 | ||
| 87 | { | |
| 88 | 8 | fr = view.cloneFeatureRenderer(); |
| 89 | 8 | return true; |
| 90 | } | |
| 91 | ||
| 92 | ArrayList<AlignmentAnnotation> ssForSeqs = null; | |
| 93 | ||
| 94 | 8 | @Override |
| 95 | public SequenceI[] expandSeqData(SequenceI[] sequences, | |
| 96 | AlignmentView seqData, SimilarityParamsI scoreParams, | |
| 97 | List<String> labels, ArrayList<AlignmentAnnotation> ssAnnotationForSeqs, | |
| 98 | HashMap<Integer, String> annotationDetails) | |
| 99 | { | |
| 100 | 8 | ssForSeqs = new ArrayList<AlignmentAnnotation>(); |
| 101 | 8 | List<SequenceI> newSequences = new ArrayList<SequenceI>(); |
| 102 | 8 | List<SeqCigar> newCigs = new ArrayList<SeqCigar>(); |
| 103 | 8 | int sq = 0; |
| 104 | ||
| 105 | 8 | AlignmentAnnotation[] alignAnnotList = fr.getViewport().getAlignment() |
| 106 | .getAlignmentAnnotation(); | |
| 107 | ||
| 108 | 8 | String ssSource = scoreParams.getSecondaryStructureSource(); |
| 109 | 8 | if (ssSource == null || ssSource == "") |
| 110 | { | |
| 111 | 0 | ssSource = Constants.SS_ALL_PROVIDERS; |
| 112 | } | |
| 113 | ||
| 114 | /* | |
| 115 | * Add secondary structure annotations that are added to the annotation track | |
| 116 | * to the map | |
| 117 | */ | |
| 118 | 8 | Map<SequenceI, ArrayList<AlignmentAnnotation>> ssAlignmentAnnotationForSequences = AlignmentUtils |
| 119 | .getSequenceAssociatedAlignmentAnnotations(alignAnnotList, | |
| 120 | ssSource); | |
| 121 | ||
| 122 | 8 | for (SeqCigar scig : seqData.getSequences()) |
| 123 | { | |
| 124 | // get the next sequence that should be bound to this scig: may be null | |
| 125 | 29 | SequenceI alSeq = sequences[sq++]; |
| 126 | 29 | List<AlignmentAnnotation> ssec = ssAlignmentAnnotationForSequences |
| 127 | .get(scig.getRefSeq()); | |
| 128 | ||
| 129 | 29 | if (ssec == null && scoreParams.getExcludeSeqWithoutAnnot()) |
| 130 | { | |
| 131 | 0 | continue; |
| 132 | } | |
| 133 | 29 | else if (ssec == null) |
| 134 | { | |
| 135 | // not defined | |
| 136 | 28 | newSequences.add(alSeq); |
| 137 | 28 | if (alSeq != null) |
| 138 | { | |
| 139 | //labels.add("No Secondary Structure"); | |
| 140 | 14 | labels.add(Constants.STRUCTURE_PROVIDERS.get("None")); |
| 141 | } | |
| 142 | 28 | SeqCigar newSeqCigar = scig; // new SeqCigar(scig); |
| 143 | 28 | newCigs.add(newSeqCigar); |
| 144 | 28 | ssForSeqs.add(null); |
| 145 | } | |
| 146 | else | |
| 147 | { | |
| 148 | 5 | for (int i = 0; i < ssec.size(); i++) |
| 149 | { | |
| 150 | 4 | if (alSeq != null) |
| 151 | { | |
| 152 | // Add annotationDetails if the annotation has | |
| 153 | // ANNOTATION_DETAILS property value (additional metadata) | |
| 154 | ||
| 155 | 4 | if (ssec.get(i).hasAnnotationDetailsProperty()) |
| 156 | { | |
| 157 | // using key = labels.size() gives the position of the node | |
| 158 | 0 | annotationDetails.put(labels.size(), ssec.get(i).getAnnotationDetailsProperty()); |
| 159 | } | |
| 160 | ||
| 161 | 4 | String provider = AlignmentAnnotationUtils |
| 162 | .extractSSSourceFromAnnotationDescription(ssec.get(i)); | |
| 163 | 4 | labels.add(provider); |
| 164 | } | |
| 165 | 4 | newSequences.add(alSeq); |
| 166 | 4 | SeqCigar newSeqCigar = scig; // new SeqCigar(scig); |
| 167 | 4 | newCigs.add(newSeqCigar); |
| 168 | 4 | ssForSeqs.add(ssec.get(i)); |
| 169 | } | |
| 170 | } | |
| 171 | } | |
| 172 | 8 | ssAnnotationForSeqs.addAll(ssForSeqs); |
| 173 | 8 | seqData.setSequences(newCigs.toArray(new SeqCigar[0])); |
| 174 | 8 | return newSequences.toArray(new SequenceI[0]); |
| 175 | ||
| 176 | } | |
| 177 | ||
| 178 | /** | |
| 179 | * Calculates distance score [i][j] between each pair of protein sequences | |
| 180 | * based on their secondary structure annotations (H, E, C). The final score | |
| 181 | * is normalised by the number of alignment columns processed, providing an | |
| 182 | * average similarity score. | |
| 183 | * <p> | |
| 184 | * The parameters argument can include settings for handling gap-residue | |
| 185 | * aligned positions and may determine if the score calculation is based on | |
| 186 | * the longer or shorter sequence in each pair. This can be important for | |
| 187 | * handling partial alignments or sequences of significantly different | |
| 188 | * lengths. | |
| 189 | * | |
| 190 | * @param seqData | |
| 191 | * The aligned sequence data including secondary structure | |
| 192 | * annotations. | |
| 193 | * @param params | |
| 194 | * Additional parameters for customising the scoring process, such as | |
| 195 | * gap handling and sequence length consideration. | |
| 196 | */ | |
| 197 | 11 | @Override |
| 198 | public MatrixI findDistances(AlignmentView seqData, | |
| 199 | SimilarityParamsI params) | |
| 200 | { | |
| 201 | 11 | if (ssForSeqs == null |
| 202 | || ssForSeqs.size() != seqData.getSequences().length) | |
| 203 | { | |
| 204 | // expandSeqData needs to be called to initialise the hash | |
| 205 | 7 | SequenceI[] sequences = new SequenceI[seqData.getSequences().length]; |
| 206 | // we throw away the new labels in this case.. | |
| 207 | 7 | expandSeqData(sequences, seqData, params, new ArrayList<String>(), |
| 208 | new ArrayList<AlignmentAnnotation>(), new HashMap<Integer, String>()); | |
| 209 | } | |
| 210 | 11 | SeqCigar[] seqs = seqData.getSequences(); |
| 211 | 11 | int noseqs = seqs.length; // no of sequences |
| 212 | 11 | int cpwidth = 0; |
| 213 | 11 | double[][] similarities = new double[noseqs][noseqs]; // matrix to store |
| 214 | // similarity score | |
| 215 | // secondary structure source parameter selected by the user from the drop | |
| 216 | // down. | |
| 217 | 11 | String ssSource = params.getSecondaryStructureSource(); |
| 218 | 11 | if (ssSource == null || ssSource == "") |
| 219 | { | |
| 220 | 0 | ssSource = Constants.SS_ALL_PROVIDERS; |
| 221 | } | |
| 222 | 11 | ssRateMatrix = ScoreModels.getInstance().getSecondaryStructureMatrix(); |
| 223 | ||
| 224 | // need to get real position for view position | |
| 225 | 11 | int[] viscont = seqData.getVisibleContigs(); |
| 226 | ||
| 227 | /* | |
| 228 | * scan each column, compute and add to each similarity[i, j] | |
| 229 | * the number of secondary structure annotation that seqi | |
| 230 | * and seqj do not share | |
| 231 | */ | |
| 232 | 22 | for (int vc = 0; vc < viscont.length; vc += 2) |
| 233 | { | |
| 234 | // Iterates for each column position | |
| 235 | 152 | for (int cpos = viscont[vc]; cpos <= viscont[vc + 1]; cpos++) |
| 236 | { | |
| 237 | 141 | cpwidth++; // used to normalise the similarity score |
| 238 | ||
| 239 | /* | |
| 240 | * get set of sequences without gap in the current column | |
| 241 | */ | |
| 242 | 141 | Set<SeqCigar> seqsWithoutGapAtCol = findSeqsWithoutGapAtColumn(seqs, |
| 243 | cpos); | |
| 244 | ||
| 245 | /* | |
| 246 | * calculate similarity score for each secondary structure annotation on i'th and j'th | |
| 247 | * sequence and add this measure to the similarities matrix | |
| 248 | * for [i, j] for j > i | |
| 249 | */ | |
| 250 | 1898 | for (int i = 0; i < (noseqs - 1); i++) |
| 251 | { | |
| 252 | 1757 | AlignmentAnnotation aa_i = ssForSeqs.get(i); |
| 253 | 1757 | boolean undefinedSS1 = aa_i == null; |
| 254 | // check if the sequence contains gap in the current column | |
| 255 | 1757 | boolean gap1 = !seqsWithoutGapAtCol.contains(seqs[i]); |
| 256 | // secondary structure is fetched only if the current column is not | |
| 257 | // gap for the sequence | |
| 258 | 1757 | char ss1 = '*'; |
| 259 | 1757 | if (!gap1 && !undefinedSS1) |
| 260 | { | |
| 261 | // fetch the position in sequence for the column and finds the | |
| 262 | // corresponding secondary structure annotation | |
| 263 | // TO DO - consider based on priority and displayed | |
| 264 | 376 | int seqPosition_i = seqs[i].findPosition(cpos); |
| 265 | 376 | if (aa_i != null) |
| 266 | 376 | ss1 = AlignmentUtils.findSSAnnotationForGivenSeqposition(aa_i, |
| 267 | seqPosition_i); | |
| 268 | } | |
| 269 | // Iterates for each sequences | |
| 270 | 17250 | for (int j = i + 1; j < noseqs; j++) |
| 271 | { | |
| 272 | ||
| 273 | // check if ss is defined | |
| 274 | 15493 | AlignmentAnnotation aa_j = ssForSeqs.get(j); |
| 275 | 15493 | boolean undefinedSS2 = aa_j == null; |
| 276 | ||
| 277 | // Set similarity to max score if both SS are not defined | |
| 278 | 15493 | if (undefinedSS1 && undefinedSS2) |
| 279 | { | |
| 280 | 9231 | similarities[i][j] += ssRateMatrix.getMaximumScore(); |
| 281 | 9231 | continue; |
| 282 | } | |
| 283 | ||
| 284 | // Set similarity to minimum score if either one SS is not defined | |
| 285 | 6262 | else if (undefinedSS1 || undefinedSS2) |
| 286 | { | |
| 287 | 5656 | similarities[i][j] += ssRateMatrix.getMinimumScore(); |
| 288 | 5656 | continue; |
| 289 | } | |
| 290 | ||
| 291 | 606 | boolean gap2 = !seqsWithoutGapAtCol.contains(seqs[j]); |
| 292 | ||
| 293 | // Variable to store secondary structure at the current column | |
| 294 | 606 | char ss2 = '*'; |
| 295 | ||
| 296 | 606 | if (!gap2 && !undefinedSS2) |
| 297 | { | |
| 298 | 564 | int seqPosition = seqs[j].findPosition(cpos); |
| 299 | ||
| 300 | 564 | if (aa_j != null) |
| 301 | 564 | ss2 = AlignmentUtils.findSSAnnotationForGivenSeqposition( |
| 302 | aa_j, seqPosition); | |
| 303 | } | |
| 304 | ||
| 305 | 606 | if ((!gap1 && !gap2) || params.includeGaps()) |
| 306 | { | |
| 307 | // Calculate similarity score based on the substitution matrix | |
| 308 | 606 | double similarityScore = ssRateMatrix.getPairwiseScore(ss1, |
| 309 | ss2); | |
| 310 | 606 | similarities[i][j] += similarityScore; |
| 311 | } | |
| 312 | } | |
| 313 | } | |
| 314 | } | |
| 315 | } | |
| 316 | ||
| 317 | /* | |
| 318 | * normalise the similarity scores (summed over columns) by the | |
| 319 | * number of visible columns used in the calculation | |
| 320 | * and fill in the bottom half of the matrix | |
| 321 | */ | |
| 322 | // TODO JAL-2424 cpwidth may be out by 1 - affects scores but not tree shape | |
| 323 | ||
| 324 | 49 | for (int i = 0; i < noseqs; i++) |
| 325 | { | |
| 326 | 201 | for (int j = i + 1; j < noseqs; j++) |
| 327 | { | |
| 328 | 163 | similarities[i][j] /= cpwidth; |
| 329 | 163 | similarities[j][i] = similarities[i][j]; |
| 330 | } | |
| 331 | } | |
| 332 | 11 | return SimilarityScoreModel |
| 333 | .similarityToDistance(new Matrix(similarities)); | |
| 334 | ||
| 335 | } | |
| 336 | ||
| 337 | /** | |
| 338 | * Builds and returns a set containing sequences (SeqCigar) which do not have | |
| 339 | * a gap at the given column position. | |
| 340 | * | |
| 341 | * @param seqs | |
| 342 | * @param columnPosition | |
| 343 | * (0..) | |
| 344 | * @return | |
| 345 | */ | |
| 346 | 141 | private Set<SeqCigar> findSeqsWithoutGapAtColumn(SeqCigar[] seqs, |
| 347 | int columnPosition) | |
| 348 | { | |
| 349 | 141 | Set<SeqCigar> seqsWithoutGapAtCol = new HashSet<>(); |
| 350 | 141 | for (SeqCigar seq : seqs) |
| 351 | { | |
| 352 | 1898 | int spos = seq.findPosition(columnPosition); |
| 353 | 1898 | if (spos != -1) |
| 354 | { | |
| 355 | /* | |
| 356 | * position is not a gap | |
| 357 | */ | |
| 358 | 1587 | seqsWithoutGapAtCol.add(seq); |
| 359 | } | |
| 360 | } | |
| 361 | 141 | return seqsWithoutGapAtCol; |
| 362 | } | |
| 363 | ||
| 364 | 157 | @Override |
| 365 | public String getName() | |
| 366 | { | |
| 367 | 157 | return NAME; |
| 368 | } | |
| 369 | ||
| 370 | 0 | @Override |
| 371 | public String getDescription() | |
| 372 | { | |
| 373 | 0 | return description; |
| 374 | } | |
| 375 | ||
| 376 | 4 | @Override |
| 377 | public boolean isDNA() | |
| 378 | { | |
| 379 | 4 | return false; |
| 380 | } | |
| 381 | ||
| 382 | 2 | @Override |
| 383 | public boolean isProtein() | |
| 384 | { | |
| 385 | 2 | return false; |
| 386 | } | |
| 387 | ||
| 388 | 6 | @Override |
| 389 | public boolean isSecondaryStructure() | |
| 390 | { | |
| 391 | 6 | return true; |
| 392 | } | |
| 393 | ||
| 394 | 0 | @Override |
| 395 | public String toString() | |
| 396 | { | |
| 397 | 0 | return "Score between sequences based on similarity between binary " |
| 398 | + "vectors marking secondary structure displayed at each column"; | |
| 399 | } | |
| 400 | } |