Coverage Report
File TCoffeeScoreFile.java
Coverage histogram
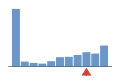
22% of files have more coverage
Classes
| Class | Line # | Actions | |||
|---|---|---|---|---|---|
| TCoffeeScoreFile | 92 | 159 | 70 | ||
| TCoffeeScoreFile.Header | 500 | 2 | 3 | ||
| TCoffeeScoreFile.Block | 524 | 4 | 3 |
Contributing tests
This file is covered by 11 tests.
.
Source view
| 1 | /* | |
| 2 | * Jalview - A Sequence Alignment Editor and Viewer ($$Version-Rel$$) | |
| 3 | * Copyright (C) $$Year-Rel$$ The Jalview Authors | |
| 4 | * | |
| 5 | * This file is part of Jalview. | |
| 6 | * | |
| 7 | * Jalview is free software: you can redistribute it and/or | |
| 8 | * modify it under the terms of the GNU General Public License | |
| 9 | * as published by the Free Software Foundation, either version 3 | |
| 10 | * of the License, or (at your option) any later version. | |
| 11 | * | |
| 12 | * Jalview is distributed in the hope that it will be useful, but | |
| 13 | * WITHOUT ANY WARRANTY; without even the implied warranty | |
| 14 | * of MERCHANTABILITY or FITNESS FOR A PARTICULAR | |
| 15 | * PURPOSE. See the GNU General Public License for more details. | |
| 16 | * | |
| 17 | * You should have received a copy of the GNU General Public License | |
| 18 | * along with Jalview. If not, see <http://www.gnu.org/licenses/>. | |
| 19 | * The Jalview Authors are detailed in the 'AUTHORS' file. | |
| 20 | */ | |
| 21 | package jalview.io; | |
| 22 | ||
| 23 | import jalview.analysis.SequenceIdMatcher; | |
| 24 | import jalview.datamodel.AlignmentAnnotation; | |
| 25 | import jalview.datamodel.AlignmentI; | |
| 26 | import jalview.datamodel.Annotation; | |
| 27 | import jalview.datamodel.SequenceI; | |
| 28 | ||
| 29 | import java.awt.Color; | |
| 30 | import java.io.IOException; | |
| 31 | import java.util.ArrayList; | |
| 32 | import java.util.HashMap; | |
| 33 | import java.util.LinkedHashMap; | |
| 34 | import java.util.List; | |
| 35 | import java.util.Map; | |
| 36 | import java.util.regex.Matcher; | |
| 37 | import java.util.regex.Pattern; | |
| 38 | ||
| 39 | /** | |
| 40 | * A file parser for T-Coffee score ascii format. This file contains the | |
| 41 | * alignment consensus for each residue in any sequence. | |
| 42 | * <p> | |
| 43 | * This file is produced by <code>t_coffee</code> providing the option | |
| 44 | * <code>-output=score_ascii </code> to the program command line | |
| 45 | * | |
| 46 | * An example file is the following | |
| 47 | * | |
| 48 | * <pre> | |
| 49 | * T-COFFEE, Version_9.02.r1228 (2012-02-16 18:15:12 - Revision 1228 - Build 336) | |
| 50 | * Cedric Notredame | |
| 51 | * CPU TIME:0 sec. | |
| 52 | * SCORE=90 | |
| 53 | * * | |
| 54 | * BAD AVG GOOD | |
| 55 | * * | |
| 56 | * 1PHT : 89 | |
| 57 | * 1BB9 : 90 | |
| 58 | * 1UHC : 94 | |
| 59 | * 1YCS : 94 | |
| 60 | * 1OOT : 93 | |
| 61 | * 1ABO : 94 | |
| 62 | * 1FYN : 94 | |
| 63 | * 1QCF : 94 | |
| 64 | * cons : 90 | |
| 65 | * | |
| 66 | * 1PHT 999999999999999999999999998762112222543211112134 | |
| 67 | * 1BB9 99999999999999999999999999987-------4322----2234 | |
| 68 | * 1UHC 99999999999999999999999999987-------5321----2246 | |
| 69 | * 1YCS 99999999999999999999999999986-------4321----1-35 | |
| 70 | * 1OOT 999999999999999999999999999861-------3------1135 | |
| 71 | * 1ABO 99999999999999999999999999986-------422-------34 | |
| 72 | * 1FYN 99999999999999999999999999985-------32--------35 | |
| 73 | * 1QCF 99999999999999999999999999974-------2---------24 | |
| 74 | * cons 999999999999999999999999999851000110321100001134 | |
| 75 | * | |
| 76 | * | |
| 77 | * 1PHT ----------5666642367889999999999889 | |
| 78 | * 1BB9 1111111111676653-355679999999999889 | |
| 79 | * 1UHC ----------788774--66789999999999889 | |
| 80 | * 1YCS ----------78777--356789999999999889 | |
| 81 | * 1OOT ----------78877--356789999999997-67 | |
| 82 | * 1ABO ----------687774--56779999999999889 | |
| 83 | * 1FYN ----------6888842356789999999999889 | |
| 84 | * 1QCF ----------6878742356789999999999889 | |
| 85 | * cons 00100000006877641356789999999999889 | |
| 86 | * </pre> | |
| 87 | * | |
| 88 | * | |
| 89 | * @author Paolo Di Tommaso | |
| 90 | * | |
| 91 | */ | |
| 92 | public class TCoffeeScoreFile extends AlignFile | |
| 93 | { | |
| 94 | ||
| 95 | /** | |
| 96 | * TCOFFEE score colourscheme | |
| 97 | */ | |
| 98 | static final Color[] colors = { new Color(102, 102, 255), // 0: lilac #6666FF | |
| 99 | new Color(0, 255, 0), // 1: green #00FF00 | |
| 100 | new Color(102, 255, 0), // 2: lime green #66FF00 | |
| 101 | new Color(204, 255, 0), // 3: greeny yellow #CCFF00 | |
| 102 | new Color(255, 255, 0), // 4: yellow #FFFF00 | |
| 103 | new Color(255, 204, 0), // 5: orange #FFCC00 | |
| 104 | new Color(255, 153, 0), // 6: deep orange #FF9900 | |
| 105 | new Color(255, 102, 0), // 7: ochre #FF6600 | |
| 106 | new Color(255, 51, 0), // 8: red #FF3300 | |
| 107 | new Color(255, 34, 0) // 9: redder #FF2000 | |
| 108 | }; | |
| 109 | ||
| 110 | public final static String TCOFFEE_SCORE = "TCoffeeScore"; | |
| 111 | ||
| 112 | static Pattern SCORES_WITH_RESIDUE_NUMS = Pattern | |
| 113 | .compile("^\\d+\\s([^\\s]+)\\s+\\d+$"); | |
| 114 | ||
| 115 | /** The {@link Header} structure holder */ | |
| 116 | Header header; | |
| 117 | ||
| 118 | /** | |
| 119 | * Holds the consensues values for each sequences. It uses a LinkedHashMap to | |
| 120 | * maintaint the insertion order. | |
| 121 | */ | |
| 122 | LinkedHashMap<String, StringBuilder> scores; | |
| 123 | ||
| 124 | Integer fWidth; | |
| 125 | ||
| 126 | 10 |  public TCoffeeScoreFile(Object inFile, DataSourceType fileSourceType) public TCoffeeScoreFile(Object inFile, DataSourceType fileSourceType) |
| 127 | throws IOException | |
| 128 | { | |
| 129 | // BH 2018 allows File or String | |
| 130 | 10 | super(inFile, fileSourceType); |
| 131 | ||
| 132 | } | |
| 133 | ||
| 134 | 0 | public TCoffeeScoreFile(FileParse source) throws IOException |
| 135 | { | |
| 136 | 0 | super(source); |
| 137 | } | |
| 138 | ||
| 139 | /** | |
| 140 | * Parse the provided reader for the T-Coffee scores file format | |
| 141 | * | |
| 142 | * @param reader | |
| 143 | * public static TCoffeeScoreFile load(Reader reader) { | |
| 144 | * | |
| 145 | * try { BufferedReader in = (BufferedReader) (reader instanceof | |
| 146 | * BufferedReader ? reader : new BufferedReader(reader)); | |
| 147 | * TCoffeeScoreFile result = new TCoffeeScoreFile(); | |
| 148 | * result.doParsing(in); return result.header != null && | |
| 149 | * result.scores != null ? result : null; } catch( Exception e) { | |
| 150 | * throw new RuntimeException(e); } } | |
| 151 | */ | |
| 152 | ||
| 153 | /** | |
| 154 | * @return The 'height' of the score matrix i.e. the numbers of score rows | |
| 155 | * that should matches the number of sequences in the alignment | |
| 156 | */ | |
| 157 | 3 | public int getHeight() |
| 158 | { | |
| 159 | // the last entry will always be the 'global' alingment consensus scores, so | |
| 160 | // it is removed | |
| 161 | // from the 'height' count to make this value compatible with the number of | |
| 162 | // sequences in the MSA | |
| 163 | 3 | return scores != null && scores.size() > 0 ? scores.size() - 1 : 0; |
| 164 | } | |
| 165 | ||
| 166 | /** | |
| 167 | * @return The 'width' of the score matrix i.e. the number of columns. Since | |
| 168 | * the score value are supposed to be calculated for an 'aligned' MSA, | |
| 169 | * all the entries have to have the same width. | |
| 170 | */ | |
| 171 | 3 | public int getWidth() |
| 172 | { | |
| 173 | 3 | return fWidth != null ? fWidth : 0; |
| 174 | } | |
| 175 | ||
| 176 | /** | |
| 177 | * Get the string of score values for the specified seqeunce ID. | |
| 178 | * | |
| 179 | * @param id | |
| 180 | * The sequence ID | |
| 181 | * @return The scores as a string of values e.g. {@code 99999987-------432}. | |
| 182 | * It return an empty string when the specified ID is missing. | |
| 183 | */ | |
| 184 | 9 | public String getScoresFor(String id) |
| 185 | { | |
| 186 | 9 | return scores != null && scores.containsKey(id) |
| 187 | ? scores.get(id).toString() | |
| 188 | : ""; | |
| 189 | } | |
| 190 | ||
| 191 | /** | |
| 192 | * @return The list of score string as a {@link List} object, in the same | |
| 193 | * ordeer of the insertion i.e. in the MSA | |
| 194 | */ | |
| 195 | 1 | public List<String> getScoresList() |
| 196 | { | |
| 197 | 1 | if (scores == null) |
| 198 | { | |
| 199 | 0 | return null; |
| 200 | } | |
| 201 | 1 | List<String> result = new ArrayList<String>(scores.size()); |
| 202 | 1 | for (Map.Entry<String, StringBuilder> it : scores.entrySet()) |
| 203 | { | |
| 204 | 9 | result.add(it.getValue().toString()); |
| 205 | } | |
| 206 | ||
| 207 | 1 | return result; |
| 208 | } | |
| 209 | ||
| 210 | /** | |
| 211 | * @return The parsed score values a matrix of bytes | |
| 212 | */ | |
| 213 | 2 | public byte[][] getScoresArray() |
| 214 | { | |
| 215 | 2 | if (scores == null) |
| 216 | { | |
| 217 | 0 | return null; |
| 218 | } | |
| 219 | 2 | byte[][] result = new byte[scores.size()][]; |
| 220 | ||
| 221 | 2 | int rowCount = 0; |
| 222 | 2 | for (Map.Entry<String, StringBuilder> it : scores.entrySet()) |
| 223 | { | |
| 224 | 25 | String line = it.getValue().toString(); |
| 225 | 25 | byte[] seqValues = new byte[line.length()]; |
| 226 | 3284 | for (int j = 0, c = line.length(); j < c; j++) |
| 227 | { | |
| 228 | ||
| 229 | 3259 | byte val = (byte) (line.charAt(j) - '0'); |
| 230 | ||
| 231 | 3259 | seqValues[j] = (val >= 0 && val <= 9) ? val : -1; |
| 232 | } | |
| 233 | ||
| 234 | 25 | result[rowCount++] = seqValues; |
| 235 | } | |
| 236 | ||
| 237 | 2 | return result; |
| 238 | } | |
| 239 | ||
| 240 | 10 | @Override |
| 241 | public void parse() throws IOException | |
| 242 | { | |
| 243 | /* | |
| 244 | * read the header | |
| 245 | */ | |
| 246 | 10 | header = readHeader(this); |
| 247 | ||
| 248 | 10 | if (header == null) |
| 249 | { | |
| 250 | 3 | error = true; |
| 251 | 3 | return; |
| 252 | } | |
| 253 | 7 | scores = new LinkedHashMap<String, StringBuilder>(); |
| 254 | ||
| 255 | /* | |
| 256 | * initilize the structure | |
| 257 | */ | |
| 258 | 7 | for (Map.Entry<String, Integer> entry : header.scores.entrySet()) |
| 259 | { | |
| 260 | 67 | scores.put(entry.getKey(), new StringBuilder()); |
| 261 | } | |
| 262 | ||
| 263 | /* | |
| 264 | * go with the reading | |
| 265 | */ | |
| 266 | 7 | Block block; |
| 267 | ? | while ((block = readBlock(this, header.scores.size())) != null) |
| 268 | { | |
| 269 | ||
| 270 | /* | |
| 271 | * append sequences read in the block | |
| 272 | */ | |
| 273 | 16 | for (Map.Entry<String, String> entry : block.items.entrySet()) |
| 274 | { | |
| 275 | 166 | StringBuilder scoreStringBuilder = scores.get(entry.getKey()); |
| 276 | 166 | if (scoreStringBuilder == null) |
| 277 | { | |
| 278 | 0 | error = true; |
| 279 | 0 | errormessage = String.format( |
| 280 | "Invalid T-Coffee score file: Sequence ID '%s' is not declared in header section", | |
| 281 | entry.getKey()); | |
| 282 | 0 | return; |
| 283 | } | |
| 284 | ||
| 285 | 166 | scoreStringBuilder.append(entry.getValue()); |
| 286 | } | |
| 287 | } | |
| 288 | ||
| 289 | /* | |
| 290 | * verify that all rows have the same width | |
| 291 | */ | |
| 292 | 7 | for (StringBuilder str : scores.values()) |
| 293 | { | |
| 294 | 67 | if (fWidth == null) |
| 295 | { | |
| 296 | 7 | fWidth = str.length(); |
| 297 | } | |
| 298 | 60 | else if (fWidth != str.length()) |
| 299 | { | |
| 300 | 0 | error = true; |
| 301 | 0 | errormessage = "Invalid T-Coffee score file: All the score sequences must have the same length"; |
| 302 | 0 | return; |
| 303 | } | |
| 304 | } | |
| 305 | ||
| 306 | 7 | return; |
| 307 | } | |
| 308 | ||
| 309 | 74 | static int parseInt(String str) |
| 310 | { | |
| 311 | 74 | try |
| 312 | { | |
| 313 | 74 | return Integer.parseInt(str); |
| 314 | } catch (NumberFormatException e) | |
| 315 | { | |
| 316 | // TODO report a warning ? | |
| 317 | 0 | return 0; |
| 318 | } | |
| 319 | } | |
| 320 | ||
| 321 | /** | |
| 322 | * Reaad the header section in the T-Coffee score file format | |
| 323 | * | |
| 324 | * @param reader | |
| 325 | * The scores reader | |
| 326 | * @return The parser {@link Header} instance | |
| 327 | * @throws RuntimeException | |
| 328 | * when the header is not in the expected format | |
| 329 | */ | |
| 330 | 10 | static Header readHeader(FileParse reader) throws IOException |
| 331 | { | |
| 332 | ||
| 333 | 10 | Header result = null; |
| 334 | 10 | try |
| 335 | { | |
| 336 | 10 | result = new Header(); |
| 337 | 10 | result.head = reader.nextLine(); |
| 338 | ||
| 339 | 10 | String line; |
| 340 | ||
| 341 | ? | while ((line = reader.nextLine()) != null) |
| 342 | { | |
| 343 | 64 | if (line.startsWith("SCORE=")) |
| 344 | { | |
| 345 | 7 | result.score = parseInt(line.substring(6).trim()); |
| 346 | 7 | break; |
| 347 | } | |
| 348 | } | |
| 349 | ||
| 350 | ? | if ((line = reader.nextLine()) == null || !"*".equals(line.trim())) |
| 351 | { | |
| 352 | 3 | error(reader, |
| 353 | "Invalid T-COFFEE score format (NO BAD/AVG/GOOD header)"); | |
| 354 | 3 | return null; |
| 355 | } | |
| 356 | ? | if ((line = reader.nextLine()) == null |
| 357 | || !"BAD AVG GOOD".equals(line.trim())) | |
| 358 | { | |
| 359 | 0 | error(reader, |
| 360 | "Invalid T-COFFEE score format (NO BAD/AVG/GOOD header)"); | |
| 361 | 0 | return null; |
| 362 | } | |
| 363 | ? | if ((line = reader.nextLine()) == null || !"*".equals(line.trim())) |
| 364 | { | |
| 365 | 0 | error(reader, |
| 366 | "Invalid T-COFFEE score format (NO BAD/AVG/GOOD header)"); | |
| 367 | 0 | return null; |
| 368 | } | |
| 369 | ||
| 370 | /* | |
| 371 | * now are expected a list if sequences ID up to the first blank line | |
| 372 | */ | |
| 373 | ? | while ((line = reader.nextLine()) != null) |
| 374 | { | |
| 375 | 74 | if ("".equals(line)) |
| 376 | { | |
| 377 | 7 | break; |
| 378 | } | |
| 379 | ||
| 380 | 67 | int p = line.indexOf(":"); |
| 381 | 67 | if (p == -1) |
| 382 | { | |
| 383 | // TODO report a warning | |
| 384 | 0 | continue; |
| 385 | } | |
| 386 | ||
| 387 | 67 | String id = line.substring(0, p).trim(); |
| 388 | 67 | int val = parseInt(line.substring(p + 1).trim()); |
| 389 | 67 | if ("".equals(id)) |
| 390 | { | |
| 391 | // TODO report warning | |
| 392 | 0 | continue; |
| 393 | } | |
| 394 | ||
| 395 | 67 | result.scores.put(id, val); |
| 396 | } | |
| 397 | ||
| 398 | 7 | if (result == null) |
| 399 | { | |
| 400 | 0 | error(reader, "T-COFFEE score file had no per-sequence scores"); |
| 401 | } | |
| 402 | ||
| 403 | } catch (IOException e) | |
| 404 | { | |
| 405 | 0 | error(reader, "Unexpected problem parsing T-Coffee score ascii file"); |
| 406 | 0 | throw e; |
| 407 | } | |
| 408 | ||
| 409 | 7 | return result; |
| 410 | } | |
| 411 | ||
| 412 | 3 | private static void error(FileParse reader, String errm) |
| 413 | { | |
| 414 | 3 | reader.error = true; |
| 415 | 3 | if (reader.errormessage == null) |
| 416 | { | |
| 417 | 0 | reader.errormessage = errm; |
| 418 | } | |
| 419 | else | |
| 420 | { | |
| 421 | 3 | reader.errormessage += "\n" + errm; |
| 422 | } | |
| 423 | } | |
| 424 | ||
| 425 | /** | |
| 426 | * Read a scores block ihe provided stream. | |
| 427 | * | |
| 428 | * @param reader | |
| 429 | * The stream to parse | |
| 430 | * @param size | |
| 431 | * The expected number of the sequence to be read | |
| 432 | * @return The {@link Block} instance read or {link null} null if the end of | |
| 433 | * file has reached. | |
| 434 | * @throws IOException | |
| 435 | * Something went wrong on the 'wire' | |
| 436 | */ | |
| 437 | 24 | static Block readBlock(FileParse reader, int size) throws IOException |
| 438 | { | |
| 439 | 24 | Block result = new Block(size); |
| 440 | 24 | String line; |
| 441 | ||
| 442 | /* | |
| 443 | * read blank lines (eventually) | |
| 444 | */ | |
| 445 | ? | while ((line = reader.nextLine()) != null && "".equals(line.trim())) |
| 446 | { | |
| 447 | // consume blank lines | |
| 448 | } | |
| 449 | ||
| 450 | 24 | if (line == null) |
| 451 | { | |
| 452 | 7 | return null; |
| 453 | } | |
| 454 | ||
| 455 | /* | |
| 456 | * read the scores block | |
| 457 | */ | |
| 458 | 17 | do |
| 459 | { | |
| 460 | 187 | if ("".equals(line.trim())) |
| 461 | { | |
| 462 | // terminated | |
| 463 | 12 | break; |
| 464 | } | |
| 465 | ||
| 466 | // split the line on the first blank | |
| 467 | // the first part have to contain the sequence id | |
| 468 | // the remaining part are the scores values | |
| 469 | 175 | int p = line.indexOf(" "); |
| 470 | 175 | if (p == -1) |
| 471 | { | |
| 472 | 0 | if (reader.warningMessage == null) |
| 473 | { | |
| 474 | 0 | reader.warningMessage = ""; |
| 475 | } | |
| 476 | 0 | reader.warningMessage += "Possible parsing error - expected to find a space in line: '" |
| 477 | + line + "'\n"; | |
| 478 | 0 | continue; |
| 479 | } | |
| 480 | ||
| 481 | 175 | String id = line.substring(0, p).trim(); |
| 482 | 175 | String val = line.substring(p + 1).trim(); |
| 483 | ||
| 484 | 175 | Matcher m = SCORES_WITH_RESIDUE_NUMS.matcher(val); |
| 485 | 175 | if (m.matches()) |
| 486 | { | |
| 487 | 12 | val = m.group(1); |
| 488 | } | |
| 489 | ||
| 490 | 175 | result.items.put(id, val); |
| 491 | ||
| 492 | ? | } while ((line = reader.nextLine()) != null); |
| 493 | ||
| 494 | 17 | return result; |
| 495 | } | |
| 496 | ||
| 497 | /* | |
| 498 | * The score file header | |
| 499 | */ | |
| 500 | static class Header | |
| 501 | { | |
| 502 | String head; | |
| 503 | ||
| 504 | int score; | |
| 505 | ||
| 506 | LinkedHashMap<String, Integer> scores = new LinkedHashMap<String, Integer>(); | |
| 507 | ||
| 508 | 1 | public int getScoreAvg() |
| 509 | { | |
| 510 | 1 | return score; |
| 511 | } | |
| 512 | ||
| 513 | 24 | public int getScoreFor(String ID) |
| 514 | { | |
| 515 | ||
| 516 | 24 | return scores.containsKey(ID) ? scores.get(ID) : -1; |
| 517 | ||
| 518 | } | |
| 519 | } | |
| 520 | ||
| 521 | /* | |
| 522 | * Hold a single block values block in the score file | |
| 523 | */ | |
| 524 | static class Block | |
| 525 | { | |
| 526 | int size; | |
| 527 | ||
| 528 | Map<String, String> items; | |
| 529 | ||
| 530 | 24 | public Block(int size) |
| 531 | { | |
| 532 | 24 | this.size = size; |
| 533 | 24 | this.items = new HashMap<String, String>(size); |
| 534 | } | |
| 535 | ||
| 536 | 8 | String getScoresFor(String id) |
| 537 | { | |
| 538 | 8 | return items.get(id); |
| 539 | } | |
| 540 | ||
| 541 | 1 | String getConsensus() |
| 542 | { | |
| 543 | 1 | return items.get("cons"); |
| 544 | } | |
| 545 | } | |
| 546 | ||
| 547 | /** | |
| 548 | * generate annotation for this TCoffee score set on the given alignment | |
| 549 | * | |
| 550 | * @param al | |
| 551 | * alignment to annotate | |
| 552 | * @param matchids | |
| 553 | * if true, annotate sequences based on matching sequence names | |
| 554 | * @return true if alignment annotation was modified, false otherwise. | |
| 555 | */ | |
| 556 | 1 | public boolean annotateAlignment(AlignmentI al, boolean matchids) |
| 557 | { | |
| 558 | 1 | if (al.getHeight() != getHeight() || al.getWidth() != getWidth()) |
| 559 | { | |
| 560 | 0 | String info = String.format( |
| 561 | "align w: %s, h: %s; score: w: %s; h: %s ", al.getWidth(), | |
| 562 | al.getHeight(), getWidth(), getHeight()); | |
| 563 | 0 | warningMessage = "Alignment shape does not match T-Coffee score file shape -- " |
| 564 | + info; | |
| 565 | 0 | return false; |
| 566 | } | |
| 567 | 1 | boolean added = false; |
| 568 | 1 | int i = 0; |
| 569 | 1 | SequenceIdMatcher sidmatcher = new SequenceIdMatcher( |
| 570 | al.getSequencesArray()); | |
| 571 | 1 | byte[][] scoreMatrix = getScoresArray(); |
| 572 | // for 2.8 - we locate any existing TCoffee annotation and remove it first | |
| 573 | // before adding this. | |
| 574 | 1 | for (Map.Entry<String, StringBuilder> id : scores.entrySet()) |
| 575 | { | |
| 576 | 16 | byte[] srow = scoreMatrix[i]; |
| 577 | 16 | SequenceI s; |
| 578 | 16 | if (matchids) |
| 579 | { | |
| 580 | 16 | s = sidmatcher.findIdMatch(id.getKey()); |
| 581 | } | |
| 582 | else | |
| 583 | { | |
| 584 | 0 | s = al.getSequenceAt(i); |
| 585 | } | |
| 586 | 16 | i++; |
| 587 | 16 | if (s == null && i != scores.size() && !id.getKey().equals("cons")) |
| 588 | { | |
| 589 | 0 | System.err |
| 590 | 0 | .println("No " + (matchids ? "match " : " sequences left ") |
| 591 | + " for TCoffee score set : " + id.getKey()); | |
| 592 | 0 | continue; |
| 593 | } | |
| 594 | 16 | int jSize = al.getWidth() < srow.length ? al.getWidth() : srow.length; |
| 595 | 16 | Annotation[] annotations = new Annotation[al.getWidth()]; |
| 596 | 2528 | for (int j = 0; j < jSize; j++) |
| 597 | { | |
| 598 | 2512 | byte val = srow[j]; |
| 599 | 2512 | if (s != null && jalview.util.Comparison.isGap(s.getCharAt(j))) |
| 600 | { | |
| 601 | 334 | annotations[j] = null; |
| 602 | 334 | if (val > 0) |
| 603 | { | |
| 604 | 0 | jalview.bin.Console.errPrintln( |
| 605 | "Warning: non-zero value for positional T-COFFEE score for gap at " | |
| 606 | + j + " in sequence " + s.getName()); | |
| 607 | } | |
| 608 | } | |
| 609 | else | |
| 610 | { | |
| 611 | 2178 | annotations[j] = new Annotation(s == null ? "" + val : null, |
| 612 | 2178 | s == null ? "" + val : null, '\0', val * 1f, |
| 613 | 2178 | val >= 0 && val < colors.length ? colors[val] |
| 614 | : Color.white); | |
| 615 | } | |
| 616 | } | |
| 617 | // this will overwrite any existing t-coffee scores for the alignment | |
| 618 | 16 | AlignmentAnnotation aa = al.findOrCreateAnnotation(TCOFFEE_SCORE, |
| 619 | TCOFFEE_SCORE, false, s, null); | |
| 620 | 16 | if (s != null) |
| 621 | { | |
| 622 | 15 | aa.label = "T-COFFEE"; |
| 623 | 15 | aa.description = "" + id.getKey(); |
| 624 | 15 | aa.annotations = annotations; |
| 625 | 15 | aa.visible = false; |
| 626 | 15 | aa.belowAlignment = false; |
| 627 | 15 | aa.setScore(header.getScoreFor(id.getKey())); |
| 628 | 15 | aa.createSequenceMapping(s, s.getStart(), true); |
| 629 | 15 | s.addAlignmentAnnotation(aa); |
| 630 | 15 | aa.adjustForAlignment(); |
| 631 | } | |
| 632 | else | |
| 633 | { | |
| 634 | 1 | aa.graph = AlignmentAnnotation.NO_GRAPH; |
| 635 | 1 | aa.label = "T-COFFEE"; |
| 636 | 1 | aa.description = "TCoffee column reliability score"; |
| 637 | 1 | aa.annotations = annotations; |
| 638 | 1 | aa.belowAlignment = true; |
| 639 | 1 | aa.visible = true; |
| 640 | 1 | aa.setScore(header.getScoreAvg()); |
| 641 | } | |
| 642 | 16 | aa.showAllColLabels = true; |
| 643 | 16 | aa.validateRangeAndDisplay(); |
| 644 | 16 | added = true; |
| 645 | } | |
| 646 | ||
| 647 | 1 | return added; |
| 648 | } | |
| 649 | ||
| 650 | 0 | @Override |
| 651 | public String print(SequenceI[] sqs, boolean jvsuffix) | |
| 652 | { | |
| 653 | // TODO Auto-generated method stub | |
| 654 | 0 | return "Not valid."; |
| 655 | } | |
| 656 | } |