Coverage Report
File SequenceOntologyLite.java
Coverage histogram
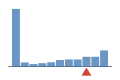
20% of files have more coverage
Classes
| Class | Line # | Actions | |||
|---|---|---|---|---|---|
| SequenceOntologyLite | 41 | 35 | 15 |
Contributing tests
This file is covered by 16 tests.
.
Source view
| 1 | /* | |
| 2 | * Jalview - A Sequence Alignment Editor and Viewer ($$Version-Rel$$) | |
| 3 | * Copyright (C) $$Year-Rel$$ The Jalview Authors | |
| 4 | * | |
| 5 | * This file is part of Jalview. | |
| 6 | * | |
| 7 | * Jalview is free software: you can redistribute it and/or | |
| 8 | * modify it under the terms of the GNU General Public License | |
| 9 | * as published by the Free Software Foundation, either version 3 | |
| 10 | * of the License, or (at your option) any later version. | |
| 11 | * | |
| 12 | * Jalview is distributed in the hope that it will be useful, but | |
| 13 | * WITHOUT ANY WARRANTY; without even the implied warranty | |
| 14 | * of MERCHANTABILITY or FITNESS FOR A PARTICULAR | |
| 15 | * PURPOSE. See the GNU General Public License for more details. | |
| 16 | * | |
| 17 | * You should have received a copy of the GNU General Public License | |
| 18 | * along with Jalview. If not, see <http://www.gnu.org/licenses/>. | |
| 19 | * The Jalview Authors are detailed in the 'AUTHORS' file. | |
| 20 | */ | |
| 21 | package jalview.io.gff; | |
| 22 | ||
| 23 | import java.util.ArrayList; | |
| 24 | import java.util.Collections; | |
| 25 | import java.util.HashMap; | |
| 26 | import java.util.List; | |
| 27 | import java.util.Map; | |
| 28 | ||
| 29 | /** | |
| 30 | * An implementation of SequenceOntologyI that hard codes terms of interest. | |
| 31 | * | |
| 32 | * Use this in unit testing by calling SequenceOntology.setInstance(new | |
| 33 | * SequenceOntologyLite()). | |
| 34 | * | |
| 35 | * May also become a stand-in for SequenceOntology in the applet if we want to | |
| 36 | * avoid the additional jars needed for parsing the full SO. | |
| 37 | * | |
| 38 | * @author gmcarstairs | |
| 39 | * | |
| 40 | */ | |
| 41 | public class SequenceOntologyLite implements SequenceOntologyI | |
| 42 | { | |
| 43 | /* | |
| 44 | * initial selection of types of interest when processing Ensembl features | |
| 45 | * NB unlike the full SequenceOntology we don't traverse indirect | |
| 46 | * child-parent relationships here so e.g. need to list every sub-type | |
| 47 | * (direct or indirect) that is of interest | |
| 48 | */ | |
| 49 | // @formatter:off | |
| 50 | private final String[][] TERMS = new String[][] { | |
| 51 | ||
| 52 | /* | |
| 53 | * gene sub-types: | |
| 54 | */ | |
| 55 | { "gene", "gene" }, | |
| 56 | { "ncRNA_gene", "gene" }, | |
| 57 | { "snRNA_gene", "gene" }, | |
| 58 | { "miRNA_gene", "gene" }, | |
| 59 | { "lincRNA_gene", "gene" }, | |
| 60 | { "rRNA_gene", "gene" }, | |
| 61 | ||
| 62 | /* | |
| 63 | * transcript sub-types: | |
| 64 | */ | |
| 65 | { "transcript", "transcript" }, | |
| 66 | { "mature_transcript", "transcript" }, | |
| 67 | { "processed_transcript", "transcript" }, | |
| 68 | { "aberrant_processed_transcript", "transcript" }, | |
| 69 | { "ncRNA", "transcript" }, | |
| 70 | { "snRNA", "transcript" }, | |
| 71 | { "miRNA", "transcript" }, | |
| 72 | { "lincRNA", "transcript" }, | |
| 73 | { "lnc_RNA", "transcript" }, | |
| 74 | { "rRNA", "transcript" }, | |
| 75 | { "mRNA", "transcript" }, | |
| 76 | // there are many more sub-types of ncRNA... | |
| 77 | ||
| 78 | /* | |
| 79 | * sequence_variant sub-types | |
| 80 | */ | |
| 81 | { "sequence_variant", "sequence_variant" }, | |
| 82 | { "structural_variant", "sequence_variant" }, | |
| 83 | { "feature_variant", "sequence_variant" }, | |
| 84 | { "gene_variant", "sequence_variant" }, | |
| 85 | { "transcript_variant", "sequence_variant" }, | |
| 86 | // NB Ensembl uses NMD_transcript_variant as if a 'transcript' | |
| 87 | // but we model it here correctly as per the SO | |
| 88 | { "NMD_transcript_variant", "sequence_variant" }, | |
| 89 | { "missense_variant", "sequence_variant" }, | |
| 90 | { "synonymous_variant", "sequence_variant" }, | |
| 91 | { "frameshift_variant", "sequence_variant" }, | |
| 92 | { "5_prime_UTR_variant", "sequence_variant" }, | |
| 93 | { "3_prime_UTR_variant", "sequence_variant" }, | |
| 94 | { "stop_gained", "sequence_variant" }, | |
| 95 | { "stop_lost", "sequence_variant" }, | |
| 96 | { "inframe_deletion", "sequence_variant" }, | |
| 97 | { "inframe_insertion", "sequence_variant" }, | |
| 98 | { "splice_region_variant", "sequence_variant" }, | |
| 99 | ||
| 100 | /* | |
| 101 | * no sub-types of exon or CDS yet seen in Ensembl | |
| 102 | * some added here for testing purposes | |
| 103 | */ | |
| 104 | { "exon", "exon" }, | |
| 105 | { "coding_exon", "exon" }, | |
| 106 | { "CDS", "CDS" }, | |
| 107 | { "CDS_predicted", "CDS" }, | |
| 108 | ||
| 109 | /* | |
| 110 | * terms used in exonerate or PASA GFF | |
| 111 | */ | |
| 112 | { "protein_match", "protein_match"}, | |
| 113 | { "nucleotide_match", "nucleotide_match"}, | |
| 114 | { "cDNA_match", "nucleotide_match"}, | |
| 115 | ||
| 116 | /* | |
| 117 | * used in InterProScan GFF | |
| 118 | */ | |
| 119 | { "polypeptide", "polypeptide" } | |
| 120 | }; | |
| 121 | // @formatter:on | |
| 122 | ||
| 123 | /* | |
| 124 | * hard-coded list of any parents (direct or indirect) | |
| 125 | * that we care about for a term | |
| 126 | */ | |
| 127 | private Map<String, List<String>> parents; | |
| 128 | ||
| 129 | private List<String> termsFound; | |
| 130 | ||
| 131 | private List<String> termsNotFound; | |
| 132 | ||
| 133 | 6 |  public SequenceOntologyLite() public SequenceOntologyLite() |
| 134 | { | |
| 135 | 6 | termsFound = new ArrayList<>(); |
| 136 | 6 | termsNotFound = new ArrayList<>(); |
| 137 | 6 | loadStaticData(); |
| 138 | } | |
| 139 | ||
| 140 | /** | |
| 141 | * Loads hard-coded data into a lookup table of {term, {list_of_parents}} | |
| 142 | */ | |
| 143 | 6 | private void loadStaticData() |
| 144 | { | |
| 145 | 6 | parents = new HashMap<>(); |
| 146 | 6 | for (String[] pair : TERMS) |
| 147 | { | |
| 148 | 246 | List<String> p = parents.get(pair[0]); |
| 149 | 246 | if (p == null) |
| 150 | { | |
| 151 | 246 | p = new ArrayList<>(); |
| 152 | 246 | parents.put(pair[0], p); |
| 153 | } | |
| 154 | 246 | p.add(pair[1]); |
| 155 | } | |
| 156 | } | |
| 157 | ||
| 158 | /** | |
| 159 | * Answers true if 'child' isA 'parent' (including equality). In this | |
| 160 | * implementation, based only on hard-coded values. | |
| 161 | */ | |
| 162 | 90 | @Override |
| 163 | public boolean isA(String child, String parent) | |
| 164 | { | |
| 165 | 90 | if (child == null || parent == null) |
| 166 | { | |
| 167 | 0 | return false; |
| 168 | } | |
| 169 | 90 | if (child.equals(parent)) |
| 170 | { | |
| 171 | 12 | termFound(child); |
| 172 | 12 | return true; |
| 173 | } | |
| 174 | ||
| 175 | 78 | List<String> p = parents.get(child); |
| 176 | 78 | if (p == null) |
| 177 | { | |
| 178 | 11 | termNotFound(child); |
| 179 | 11 | return false; |
| 180 | } | |
| 181 | 67 | termFound(child); |
| 182 | 67 | if (p.contains(parent)) |
| 183 | { | |
| 184 | 35 | return true; |
| 185 | } | |
| 186 | 32 | return false; |
| 187 | } | |
| 188 | ||
| 189 | /** | |
| 190 | * Records a valid term queried for, for reporting purposes | |
| 191 | * | |
| 192 | * @param term | |
| 193 | */ | |
| 194 | 79 | private void termFound(String term) |
| 195 | { | |
| 196 | 79 | if (!termsFound.contains(term)) |
| 197 | { | |
| 198 | 41 | synchronized (termsFound) |
| 199 | { | |
| 200 | 41 | termsFound.add(term); |
| 201 | } | |
| 202 | } | |
| 203 | } | |
| 204 | ||
| 205 | /** | |
| 206 | * Records an invalid term queried for, for reporting purposes | |
| 207 | * | |
| 208 | * @param term | |
| 209 | */ | |
| 210 | 11 | private void termNotFound(String term) |
| 211 | { | |
| 212 | 11 | synchronized (termsNotFound) |
| 213 | { | |
| 214 | 11 | if (!termsNotFound.contains(term)) |
| 215 | { | |
| 216 | // suppress logging here as it reports Uniprot sequence features | |
| 217 | // (which do not use SO terms) when auto-configuring feature colours | |
| 218 | // System.out.println("SO term " + term | |
| 219 | // + " not known - add to model if needed in " | |
| 220 | // + getClass().getName()); | |
| 221 | 5 | termsNotFound.add(term); |
| 222 | } | |
| 223 | } | |
| 224 | } | |
| 225 | ||
| 226 | /** | |
| 227 | * Sorts (case-insensitive) and returns the list of valid terms queried for | |
| 228 | */ | |
| 229 | 0 | @Override |
| 230 | public List<String> termsFound() | |
| 231 | { | |
| 232 | 0 | synchronized (termsFound) |
| 233 | { | |
| 234 | 0 | Collections.sort(termsFound, String.CASE_INSENSITIVE_ORDER); |
| 235 | 0 | return termsFound; |
| 236 | } | |
| 237 | } | |
| 238 | ||
| 239 | /** | |
| 240 | * Sorts (case-insensitive) and returns the list of invalid terms queried for | |
| 241 | */ | |
| 242 | 0 | @Override |
| 243 | public List<String> termsNotFound() | |
| 244 | { | |
| 245 | 0 | synchronized (termsNotFound) |
| 246 | { | |
| 247 | 0 | Collections.sort(termsNotFound, String.CASE_INSENSITIVE_ORDER); |
| 248 | 0 | return termsNotFound; |
| 249 | } | |
| 250 | } | |
| 251 | } |