Coverage Report
File Grouping.java
Coverage histogram
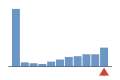
0% of files have more coverage
Classes
| Class | Line # | Actions | |||
|---|---|---|---|---|---|
| Grouping | 40 | 63 | 14 |
Contributing tests
This file is covered by 1 test.
.
Source view
| 1 | /* | |
| 2 | * Jalview - A Sequence Alignment Editor and Viewer ($$Version-Rel$$) | |
| 3 | * Copyright (C) $$Year-Rel$$ The Jalview Authors | |
| 4 | * | |
| 5 | * This file is part of Jalview. | |
| 6 | * | |
| 7 | * Jalview is free software: you can redistribute it and/or | |
| 8 | * modify it under the terms of the GNU General Public License | |
| 9 | * as published by the Free Software Foundation, either version 3 | |
| 10 | * of the License, or (at your option) any later version. | |
| 11 | * | |
| 12 | * Jalview is distributed in the hope that it will be useful, but | |
| 13 | * WITHOUT ANY WARRANTY; without even the implied warranty | |
| 14 | * of MERCHANTABILITY or FITNESS FOR A PARTICULAR | |
| 15 | * PURPOSE. See the GNU General Public License for more details. | |
| 16 | * | |
| 17 | * You should have received a copy of the GNU General Public License | |
| 18 | * along with Jalview. If not, see <http://www.gnu.org/licenses/>. | |
| 19 | * The Jalview Authors are detailed in the 'AUTHORS' file. | |
| 20 | */ | |
| 21 | package jalview.analysis; | |
| 22 | ||
| 23 | import jalview.datamodel.ColumnSelection; | |
| 24 | import jalview.datamodel.SequenceGroup; | |
| 25 | import jalview.datamodel.SequenceI; | |
| 26 | ||
| 27 | import java.util.ArrayList; | |
| 28 | import java.util.HashMap; | |
| 29 | import java.util.List; | |
| 30 | import java.util.Map; | |
| 31 | import java.util.Vector; | |
| 32 | ||
| 33 | /** | |
| 34 | * various methods for defining groups on an alignment based on some other | |
| 35 | * properties | |
| 36 | * | |
| 37 | * @author JimP | |
| 38 | * | |
| 39 | */ | |
| 40 | public class Grouping | |
| 41 | { | |
| 42 | /** | |
| 43 | * Divide the given sequences based on the equivalence of their corresponding | |
| 44 | * selectedChars string. If exgroups is provided, existing groups will be | |
| 45 | * subdivided. | |
| 46 | * | |
| 47 | * @param sequences | |
| 48 | * @param selectedChars | |
| 49 | * @param list | |
| 50 | * @return | |
| 51 | */ | |
| 52 | 1 |  public static SequenceGroup[] makeGroupsFrom(SequenceI[] sequences, public static SequenceGroup[] makeGroupsFrom(SequenceI[] sequences, |
| 53 | String[] selectedChars, List<SequenceGroup> list) | |
| 54 | { | |
| 55 | // TODO: determine how to get/recover input data for group generation | |
| 56 | 1 | Map<String, List<SequenceI>> gps = new HashMap<String, List<SequenceI>>(); |
| 57 | 1 | int width = 0, i; |
| 58 | 1 | Map<String, SequenceGroup> pgroup = new HashMap<String, SequenceGroup>(); |
| 59 | 1 | if (list != null) |
| 60 | { | |
| 61 | 1 | for (SequenceGroup sg : list) |
| 62 | { | |
| 63 | 2 | for (SequenceI sq : sg.getSequences(null)) |
| 64 | { | |
| 65 | 5 | pgroup.put(sq.toString(), sg); |
| 66 | } | |
| 67 | } | |
| 68 | } | |
| 69 | 6 | for (i = 0; i < sequences.length; i++) |
| 70 | { | |
| 71 | 5 | String schar = selectedChars[i]; |
| 72 | 5 | SequenceGroup pgp = pgroup.get(((Object) sequences[i]).toString()); |
| 73 | 5 | if (pgp != null) |
| 74 | { | |
| 75 | 5 | schar = pgp.getName() + ":" + schar; |
| 76 | } | |
| 77 | 5 | List<SequenceI> svec = gps.get(schar); |
| 78 | 5 | if (svec == null) |
| 79 | { | |
| 80 | 4 | svec = new ArrayList<SequenceI>(); |
| 81 | 4 | gps.put(schar, svec); |
| 82 | } | |
| 83 | 5 | if (width < sequences[i].getLength()) |
| 84 | { | |
| 85 | 1 | width = sequences[i].getLength(); |
| 86 | } | |
| 87 | 5 | svec.add(sequences[i]); |
| 88 | } | |
| 89 | // make some groups | |
| 90 | 1 | SequenceGroup[] groups = new SequenceGroup[gps.size()]; |
| 91 | 1 | i = 0; |
| 92 | 1 | for (String key : gps.keySet()) |
| 93 | { | |
| 94 | 4 | SequenceGroup group = new SequenceGroup(gps.get(key), |
| 95 | "Subseq: " + key, null, true, true, false, 0, width - 1); | |
| 96 | ||
| 97 | 4 | groups[i++] = group; |
| 98 | } | |
| 99 | 1 | gps.clear(); |
| 100 | 1 | pgroup.clear(); |
| 101 | 1 | return groups; |
| 102 | } | |
| 103 | ||
| 104 | /** | |
| 105 | * Divide the given sequences based on the equivalence of characters at | |
| 106 | * selected columns If exgroups is provided, existing groups will be | |
| 107 | * subdivided. | |
| 108 | * | |
| 109 | * @param sequences | |
| 110 | * @param columnSelection | |
| 111 | * @param list | |
| 112 | * @return | |
| 113 | */ | |
| 114 | 1 | public static SequenceGroup[] makeGroupsFromCols(SequenceI[] sequences, |
| 115 | ColumnSelection cs, List<SequenceGroup> list) | |
| 116 | { | |
| 117 | // TODO: determine how to get/recover input data for group generation | |
| 118 | 1 | Map<String, List<SequenceI>> gps = new HashMap<String, List<SequenceI>>(); |
| 119 | 1 | Map<String, SequenceGroup> pgroup = new HashMap<String, SequenceGroup>(); |
| 120 | 1 | if (list != null) |
| 121 | { | |
| 122 | 1 | for (SequenceGroup sg : list) |
| 123 | { | |
| 124 | 2 | for (SequenceI sq : sg.getSequences(null)) |
| 125 | { | |
| 126 | 5 | pgroup.put(sq.toString(), sg); |
| 127 | } | |
| 128 | } | |
| 129 | } | |
| 130 | ||
| 131 | /* | |
| 132 | * get selected columns (in the order they were selected); | |
| 133 | * note this could include right-to-left ranges | |
| 134 | */ | |
| 135 | 1 | int[] spos = new int[cs.getSelected().size()]; |
| 136 | 1 | int width = -1; |
| 137 | 1 | int i = 0; |
| 138 | 1 | for (Integer pos : cs.getSelected()) |
| 139 | { | |
| 140 | 3 | spos[i++] = pos.intValue(); |
| 141 | } | |
| 142 | ||
| 143 | 6 | for (i = 0; i < sequences.length; i++) |
| 144 | { | |
| 145 | 5 | int slen = sequences[i].getLength(); |
| 146 | 5 | if (width < slen) |
| 147 | { | |
| 148 | 1 | width = slen; |
| 149 | } | |
| 150 | ||
| 151 | 5 | SequenceGroup pgp = pgroup.get(((Object) sequences[i]).toString()); |
| 152 | 5 | StringBuilder schar = new StringBuilder(); |
| 153 | 5 | if (pgp != null) |
| 154 | { | |
| 155 | 5 | schar.append(pgp.getName() + ":"); |
| 156 | } | |
| 157 | 5 | for (int p : spos) |
| 158 | { | |
| 159 | 15 | if (p >= slen) |
| 160 | { | |
| 161 | 0 | schar.append("~"); |
| 162 | } | |
| 163 | else | |
| 164 | { | |
| 165 | 15 | schar.append(sequences[i].getCharAt(p)); |
| 166 | } | |
| 167 | } | |
| 168 | 5 | List<SequenceI> svec = gps.get(schar.toString()); |
| 169 | 5 | if (svec == null) |
| 170 | { | |
| 171 | 4 | svec = new ArrayList<SequenceI>(); |
| 172 | 4 | gps.put(schar.toString(), svec); |
| 173 | } | |
| 174 | 5 | svec.add(sequences[i]); |
| 175 | } | |
| 176 | // make some groups | |
| 177 | 1 | SequenceGroup[] groups = new SequenceGroup[gps.size()]; |
| 178 | 1 | i = 0; |
| 179 | 1 | for (String key : gps.keySet()) |
| 180 | { | |
| 181 | 4 | SequenceGroup group = new SequenceGroup(gps.get(key), |
| 182 | "Subseq: " + key, null, true, true, false, 0, width - 1); | |
| 183 | ||
| 184 | 4 | groups[i++] = group; |
| 185 | } | |
| 186 | 1 | gps.clear(); |
| 187 | 1 | pgroup.clear(); |
| 188 | 1 | return groups; |
| 189 | } | |
| 190 | ||
| 191 | /** | |
| 192 | * subdivide the given sequences based on the distribution of features | |
| 193 | * | |
| 194 | * @param featureLabels | |
| 195 | * - null or one or more feature types to filter on. | |
| 196 | * @param groupLabels | |
| 197 | * - null or set of groups to filter features on | |
| 198 | * @param start | |
| 199 | * - range for feature filter | |
| 200 | * @param stop | |
| 201 | * - range for feature filter | |
| 202 | * @param sequences | |
| 203 | * - sequences to be divided | |
| 204 | * @param exgroups | |
| 205 | * - existing groups to be subdivided | |
| 206 | * @param method | |
| 207 | * - density, description, score | |
| 208 | */ | |
| 209 | 0 | public static void divideByFeature(String[] featureLabels, |
| 210 | String[] groupLabels, int start, int stop, SequenceI[] sequences, | |
| 211 | Vector exgroups, String method) | |
| 212 | { | |
| 213 | // TODO implement divideByFeature | |
| 214 | /* | |
| 215 | * if (method!=AlignmentSorter.FEATURE_SCORE && | |
| 216 | * method!=AlignmentSorter.FEATURE_LABEL && | |
| 217 | * method!=AlignmentSorter.FEATURE_DENSITY) { throw newError( | |
| 218 | * "Implementation Error - sortByFeature method must be one of FEATURE_SCORE, FEATURE_LABEL or FEATURE_DENSITY." | |
| 219 | * ); } boolean ignoreScore=method!=AlignmentSorter.FEATURE_SCORE; | |
| 220 | * StringBuffer scoreLabel = new StringBuffer(); | |
| 221 | * scoreLabel.append(start+stop+method); // This doesn't work yet - we'd | |
| 222 | * like to have a canonical ordering that can be preserved from call to call | |
| 223 | * for (int i=0;featureLabels!=null && i<featureLabels.length; i++) { | |
| 224 | * scoreLabel.append(featureLabels[i]==null ? "null" : featureLabels[i]); } | |
| 225 | * for (int i=0;groupLabels!=null && i<groupLabels.length; i++) { | |
| 226 | * scoreLabel.append(groupLabels[i]==null ? "null" : groupLabels[i]); } | |
| 227 | * SequenceI[] seqs = alignment.getSequencesArray(); | |
| 228 | * | |
| 229 | * boolean[] hasScore = new boolean[seqs.length]; // per sequence score // | |
| 230 | * presence int hasScores = 0; // number of scores present on set double[] | |
| 231 | * scores = new double[seqs.length]; int[] seqScores = new int[seqs.length]; | |
| 232 | * Object[] feats = new Object[seqs.length]; double min = 0, max = 0; for | |
| 233 | * (int i = 0; i < seqs.length; i++) { SequenceFeature[] sf = | |
| 234 | * seqs[i].getSequenceFeatures(); if (sf==null && | |
| 235 | * seqs[i].getDatasetSequence()!=null) { sf = | |
| 236 | * seqs[i].getDatasetSequence().getSequenceFeatures(); } if (sf==null) { sf | |
| 237 | * = new SequenceFeature[0]; } else { SequenceFeature[] tmp = new | |
| 238 | * SequenceFeature[sf.length]; for (int s=0; s<tmp.length;s++) { tmp[s] = | |
| 239 | * sf[s]; } sf = tmp; } int sstart = (start==-1) ? start : | |
| 240 | * seqs[i].findPosition(start); int sstop = (stop==-1) ? stop : | |
| 241 | * seqs[i].findPosition(stop); seqScores[i]=0; scores[i]=0.0; int | |
| 242 | * n=sf.length; for (int f=0;f<sf.length;f++) { // filter for selection | |
| 243 | * criteria if ( // ignore features outwith alignment start-stop positions. | |
| 244 | * (sf[f].end < sstart || sf[f].begin > sstop) || // or ignore based on | |
| 245 | * selection criteria (featureLabels != null && | |
| 246 | * !AlignmentSorter.containsIgnoreCase(sf[f].type, featureLabels)) || | |
| 247 | * (groupLabels != null // problem here: we cannot eliminate null feature | |
| 248 | * group features && (sf[f].getFeatureGroup() != null && | |
| 249 | * !AlignmentSorter.containsIgnoreCase(sf[f].getFeatureGroup(), | |
| 250 | * groupLabels)))) { // forget about this feature sf[f] = null; n--; } else | |
| 251 | * { // or, also take a look at the scores if necessary. if (!ignoreScore && | |
| 252 | * sf[f].getScore()!=Float.NaN) { if (seqScores[i]==0) { hasScores++; } | |
| 253 | * seqScores[i]++; hasScore[i] = true; scores[i] += sf[f].getScore(); // | |
| 254 | * take the first instance of this // score. } } } SequenceFeature[] fs; | |
| 255 | * feats[i] = fs = new SequenceFeature[n]; if (n>0) { n=0; for (int | |
| 256 | * f=0;f<sf.length;f++) { if (sf[f]!=null) { ((SequenceFeature[]) | |
| 257 | * feats[i])[n++] = sf[f]; } } if (method==FEATURE_LABEL) { // order the | |
| 258 | * labels by alphabet String[] labs = new String[fs.length]; for (int | |
| 259 | * l=0;l<labs.length; l++) { labs[l] = (fs[l].getDescription()!=null ? | |
| 260 | * fs[l].getDescription() : fs[l].getType()); } | |
| 261 | * jalview.util.QuickSort.sort(labs, ((Object[]) feats[i])); } } if | |
| 262 | * (hasScore[i]) { // compute average score scores[i]/=seqScores[i]; // | |
| 263 | * update the score bounds. if (hasScores == 1) { max = min = scores[i]; } | |
| 264 | * else { if (max < scores[i]) { max = scores[i]; } if (min > scores[i]) { | |
| 265 | * min = scores[i]; } } } } | |
| 266 | * | |
| 267 | * if (method==FEATURE_SCORE) { if (hasScores == 0) { return; // do nothing | |
| 268 | * - no scores present to sort by. } // pad score matrix if (hasScores < | |
| 269 | * seqs.length) { for (int i = 0; i < seqs.length; i++) { if (!hasScore[i]) | |
| 270 | * { scores[i] = (max + i); } else { int nf=(feats[i]==null) ? 0 | |
| 271 | * :((SequenceFeature[]) feats[i]).length; | |
| 272 | * jalview.bin.Console.errPrintln("Sorting on Score: seq "+seqs[i].getName()+ | |
| 273 | * " Feats: "+nf+" Score : "+scores[i]); } } } | |
| 274 | * | |
| 275 | * jalview.util.QuickSort.sort(scores, seqs); } else if | |
| 276 | * (method==FEATURE_DENSITY) { | |
| 277 | * | |
| 278 | * // break ties between equivalent numbers for adjacent sequences by adding | |
| 279 | * 1/Nseq*i on the original order double fr = 0.9/(1.0*seqs.length); for | |
| 280 | * (int i=0;i<seqs.length; i++) { double nf; scores[i] = | |
| 281 | * (0.05+fr*i)+(nf=((feats[i]==null) ? 0.0 :1.0*((SequenceFeature[]) | |
| 282 | * feats[i]).length)); | |
| 283 | * jalview.bin.Console.errPrintln("Sorting on Density: seq "+seqs[i].getName()+ | |
| 284 | * " Feats: "+nf+" Score : "+scores[i]); } | |
| 285 | * jalview.util.QuickSort.sort(scores, seqs); } else { if | |
| 286 | * (method==FEATURE_LABEL) { throw new Error("Not yet implemented."); } } if | |
| 287 | * (lastSortByFeatureScore ==null || | |
| 288 | * scoreLabel.equals(lastSortByFeatureScore)) { setOrder(alignment, seqs); } | |
| 289 | * else { setReverseOrder(alignment, seqs); } lastSortByFeatureScore = | |
| 290 | * scoreLabel.toString(); | |
| 291 | */ | |
| 292 | } | |
| 293 | ||
| 294 | } |