Coverage Report
File CrossRefAction.java
Coverage histogram
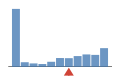
37% of files have more coverage
Classes
Class |
Line # |
Actions |
|||
|---|---|---|---|---|---|
| CrossRefAction | 59 | 141 | 55 |
Contributing tests
This file is covered by 1 test.
.
Source view
| 1 | /* | |
| 2 | * Jalview - A Sequence Alignment Editor and Viewer ($$Version-Rel$$) | |
| 3 | * Copyright (C) $$Year-Rel$$ The Jalview Authors | |
| 4 | * | |
| 5 | * This file is part of Jalview. | |
| 6 | * | |
| 7 | * Jalview is free software: you can redistribute it and/or | |
| 8 | * modify it under the terms of the GNU General Public License | |
| 9 | * as published by the Free Software Foundation, either version 3 | |
| 10 | * of the License, or (at your option) any later version. | |
| 11 | * | |
| 12 | * Jalview is distributed in the hope that it will be useful, but | |
| 13 | * WITHOUT ANY WARRANTY; without even the implied warranty | |
| 14 | * of MERCHANTABILITY or FITNESS FOR A PARTICULAR | |
| 15 | * PURPOSE. See the GNU General Public License for more details. | |
| 16 | * | |
| 17 | * You should have received a copy of the GNU General Public License | |
| 18 | * along with Jalview. If not, see <http://www.gnu.org/licenses/>. | |
| 19 | * The Jalview Authors are detailed in the 'AUTHORS' file. | |
| 20 | */ | |
| 21 | package jalview.gui; | |
| 22 | ||
| 23 | import jalview.analysis.AlignmentUtils; | |
| 24 | import jalview.analysis.CrossRef; | |
| 25 | import jalview.api.AlignmentViewPanel; | |
| 26 | import jalview.api.FeatureSettingsModelI; | |
| 27 | import jalview.bin.Cache; | |
| 28 | import jalview.bin.Console; | |
| 29 | import jalview.datamodel.Alignment; | |
| 30 | import jalview.datamodel.AlignmentI; | |
| 31 | import jalview.datamodel.DBRefEntry; | |
| 32 | import jalview.datamodel.DBRefSource; | |
| 33 | import jalview.datamodel.GeneLociI; | |
| 34 | import jalview.datamodel.SequenceI; | |
| 35 | import jalview.ext.ensembl.EnsemblInfo; | |
| 36 | import jalview.ext.ensembl.EnsemblMap; | |
| 37 | import jalview.io.gff.SequenceOntologyI; | |
| 38 | import jalview.structure.StructureSelectionManager; | |
| 39 | import jalview.util.DBRefUtils; | |
| 40 | import jalview.util.MapList; | |
| 41 | import jalview.util.MappingUtils; | |
| 42 | import jalview.util.MessageManager; | |
| 43 | import jalview.viewmodel.seqfeatures.FeatureRendererModel; | |
| 44 | import jalview.ws.SequenceFetcher; | |
| 45 | ||
| 46 | import java.util.ArrayList; | |
| 47 | import java.util.HashMap; | |
| 48 | import java.util.List; | |
| 49 | import java.util.Map; | |
| 50 | import java.util.Set; | |
| 51 | ||
| 52 | /** | |
| 53 | * Factory constructor and runnable for discovering and displaying | |
| 54 | * cross-references for a set of aligned sequences | |
| 55 | * | |
| 56 | * @author jprocter | |
| 57 | * | |
| 58 | */ | |
| 59 | public class CrossRefAction implements Runnable | |
| 60 | { | |
| 61 | private AlignFrame alignFrame; | |
| 62 | ||
| 63 | private SequenceI[] sel; | |
| 64 | ||
| 65 | private final boolean _odna; | |
| 66 | ||
| 67 | private String source; | |
| 68 | ||
| 69 | List<AlignmentViewPanel> xrefViews = new ArrayList<>(); | |
| 70 | ||
| 71 | 0 |  List<AlignmentViewPanel> getXrefViews() List<AlignmentViewPanel> getXrefViews() |
| 72 | { | |
| 73 | 0 | return xrefViews; |
| 74 | } | |
| 75 | ||
| 76 | 2 | @Override |
| 77 | public void run() | |
| 78 | { | |
| 79 | 2 | final long sttime = System.currentTimeMillis(); |
| 80 | 2 | alignFrame.setProgressBar(MessageManager.formatMessage( |
| 81 | "status.searching_for_sequences_from", new Object[] | |
| 82 | { source }), sttime); | |
| 83 | 2 | try |
| 84 | { | |
| 85 | 2 | AlignmentI alignment = alignFrame.getViewport().getAlignment(); |
| 86 | 2 | AlignmentI dataset = alignment.getDataset() == null ? alignment |
| 87 | : alignment.getDataset(); | |
| 88 | 2 | boolean dna = alignment.isNucleotide(); |
| 89 | 2 | if (_odna != dna) |
| 90 | { | |
| 91 | 0 | System.err |
| 92 | .println("Conflict: showProducts for alignment originally " | |
| 93 | 0 | + "thought to be " + (_odna ? "DNA" : "Protein") |
| 94 | 0 | + " now searching for " + (dna ? "DNA" : "Protein") |
| 95 | + " Context."); | |
| 96 | } | |
| 97 | 2 | AlignmentI xrefs = new CrossRef(sel, dataset) |
| 98 | .findXrefSequences(source, dna); | |
| 99 | 2 | if (xrefs == null) |
| 100 | { | |
| 101 | 0 | return; |
| 102 | } | |
| 103 | ||
| 104 | /* | |
| 105 | * try to look up chromosomal coordinates for nucleotide | |
| 106 | * sequences (if not already retrieved) | |
| 107 | */ | |
| 108 | 2 | findGeneLoci(xrefs.getSequences()); |
| 109 | ||
| 110 | /* | |
| 111 | * get display scheme (if any) to apply to features | |
| 112 | */ | |
| 113 | 2 | FeatureSettingsModelI featureColourScheme = new SequenceFetcher() |
| 114 | .getFeatureColourScheme(source); | |
| 115 | ||
| 116 | 2 | if (dna && AlignmentUtils.looksLikeEnsembl(alignment)) |
| 117 | { | |
| 118 | // override default featureColourScheme so products have Ensembl variant | |
| 119 | // colours | |
| 120 | 2 | featureColourScheme = new SequenceFetcher() |
| 121 | .getFeatureColourScheme(DBRefSource.ENSEMBL); | |
| 122 | } | |
| 123 | ||
| 124 | 2 | AlignmentI xrefsAlignment = makeCrossReferencesAlignment(dataset, |
| 125 | xrefs); | |
| 126 | 2 | if (!dna) |
| 127 | { | |
| 128 | 0 | xrefsAlignment = AlignmentUtils.makeCdsAlignment( |
| 129 | xrefsAlignment.getSequencesArray(), dataset, sel); | |
| 130 | 0 | xrefsAlignment.alignAs(alignment); |
| 131 | } | |
| 132 | ||
| 133 | /* | |
| 134 | * If we are opening a splitframe, make a copy of this alignment (sharing the same dataset | |
| 135 | * sequences). If we are DNA, drop introns and update mappings | |
| 136 | */ | |
| 137 | 2 | AlignmentI copyAlignment = null; |
| 138 | ||
| 139 | 2 | if (Cache.getDefault(Preferences.ENABLE_SPLIT_FRAME, true)) |
| 140 | { | |
| 141 | 2 | copyAlignment = copyAlignmentForSplitFrame(alignment, dataset, dna, |
| 142 | xrefs, xrefsAlignment); | |
| 143 | 2 | if (copyAlignment == null) |
| 144 | { | |
| 145 | 0 | return; // failed |
| 146 | } | |
| 147 | } | |
| 148 | ||
| 149 | /* | |
| 150 | * build AlignFrame(s) according to available alignment data | |
| 151 | */ | |
| 152 | 2 | AlignFrame newFrame = new AlignFrame(xrefsAlignment, |
| 153 | AlignFrame.DEFAULT_WIDTH, AlignFrame.DEFAULT_HEIGHT); | |
| 154 | 2 | if (Cache.getDefault("HIDE_INTRONS", true)) |
| 155 | { | |
| 156 | 2 | newFrame.hideFeatureColumns(SequenceOntologyI.EXON, false); |
| 157 | } | |
| 158 | 2 | String newtitle = String.format("%s %s %s", |
| 159 | 2 | dna ? MessageManager.getString("label.proteins") |
| 160 | : MessageManager.getString("label.nucleotides"), | |
| 161 | MessageManager.getString("label.for"), alignFrame.getTitle()); | |
| 162 | 2 | newFrame.setTitle(newtitle); |
| 163 | ||
| 164 | 2 | if (copyAlignment == null) |
| 165 | { | |
| 166 | /* | |
| 167 | * split frame display is turned off in preferences file | |
| 168 | */ | |
| 169 | 0 | Desktop.addInternalFrame(newFrame, newtitle, |
| 170 | AlignFrame.DEFAULT_WIDTH, AlignFrame.DEFAULT_HEIGHT); | |
| 171 | 0 | xrefViews.add(newFrame.alignPanel); |
| 172 | 0 | return; // via finally clause |
| 173 | } | |
| 174 | ||
| 175 | 2 | AlignFrame copyThis = new AlignFrame(copyAlignment, |
| 176 | AlignFrame.DEFAULT_WIDTH, AlignFrame.DEFAULT_HEIGHT); | |
| 177 | 2 | copyThis.setTitle(alignFrame.getTitle()); |
| 178 | ||
| 179 | 2 | boolean showSequenceFeatures = alignFrame.getViewport() |
| 180 | .isShowSequenceFeatures(); | |
| 181 | 2 | newFrame.setShowSeqFeatures(showSequenceFeatures); |
| 182 | 2 | copyThis.setShowSeqFeatures(showSequenceFeatures); |
| 183 | 2 | FeatureRendererModel myFeatureStyling = alignFrame.alignPanel |
| 184 | .getSeqPanel().seqCanvas.getFeatureRenderer(); | |
| 185 | ||
| 186 | /* | |
| 187 | * copy feature rendering settings to split frame | |
| 188 | */ | |
| 189 | 2 | FeatureRendererModel fr1 = newFrame.alignPanel.getSeqPanel().seqCanvas |
| 190 | .getFeatureRenderer(); | |
| 191 | 2 | fr1.transferSettings(myFeatureStyling); |
| 192 | 2 | fr1.findAllFeatures(true); |
| 193 | 2 | FeatureRendererModel fr2 = copyThis.alignPanel.getSeqPanel().seqCanvas |
| 194 | .getFeatureRenderer(); | |
| 195 | 2 | fr2.transferSettings(myFeatureStyling); |
| 196 | 2 | fr2.findAllFeatures(true); |
| 197 | ||
| 198 | /* | |
| 199 | * apply 'database source' feature configuration | |
| 200 | * if any - first to the new splitframe view about to be displayed | |
| 201 | */ | |
| 202 | ||
| 203 | 2 | newFrame.getViewport().applyFeaturesStyle(featureColourScheme); |
| 204 | 2 | copyThis.getViewport().applyFeaturesStyle(featureColourScheme); |
| 205 | ||
| 206 | /* | |
| 207 | * and for JAL-3330 also to original alignFrame view(s) | |
| 208 | * this currently trashes any original settings. | |
| 209 | */ | |
| 210 | 2 | for (AlignmentViewPanel origpanel : alignFrame.getAlignPanels()) |
| 211 | { | |
| 212 | 2 | origpanel.getAlignViewport() |
| 213 | .mergeFeaturesStyle(featureColourScheme); | |
| 214 | } | |
| 215 | ||
| 216 | 2 | SplitFrame sf = new SplitFrame(dna ? copyThis : newFrame, |
| 217 | 2 | dna ? newFrame : copyThis); |
| 218 | ||
| 219 | 2 | newFrame.setVisible(true); |
| 220 | 2 | copyThis.setVisible(true); |
| 221 | 2 | String linkedTitle = MessageManager |
| 222 | .getString("label.linked_view_title"); | |
| 223 | 2 | Desktop.addInternalFrame(sf, linkedTitle, -1, -1); |
| 224 | 2 | sf.adjustInitialLayout(); |
| 225 | ||
| 226 | // finally add the top, then bottom frame to the view list | |
| 227 | 2 | xrefViews.add(dna ? copyThis.alignPanel : newFrame.alignPanel); |
| 228 | 2 | xrefViews.add(!dna ? copyThis.alignPanel : newFrame.alignPanel); |
| 229 | ||
| 230 | } catch (OutOfMemoryError e) | |
| 231 | { | |
| 232 | 0 | new OOMWarning("whilst fetching crossreferences", e); |
| 233 | } catch (Throwable e) | |
| 234 | { | |
| 235 | 0 | Console.error("Error when finding crossreferences", e); |
| 236 | } finally | |
| 237 | { | |
| 238 | 2 | alignFrame.setProgressBar(MessageManager.formatMessage( |
| 239 | "status.finished_searching_for_sequences_from", new Object[] | |
| 240 | { source }), sttime); | |
| 241 | } | |
| 242 | } | |
| 243 | ||
| 244 | /** | |
| 245 | * Tries to add chromosomal coordinates to any nucleotide sequence which does | |
| 246 | * not already have them. Coordinates are retrieved from Ensembl given an | |
| 247 | * Ensembl identifier, either on the sequence itself or on a peptide sequence | |
| 248 | * it has a reference to. | |
| 249 | * | |
| 250 | * <pre> | |
| 251 | * Example (human): | |
| 252 | * - fetch EMBLCDS cross-references for Uniprot entry P30419 | |
| 253 | * - the EMBL sequences do not have xrefs to Ensembl | |
| 254 | * - the Uniprot entry has xrefs to | |
| 255 | * ENSP00000258960, ENSP00000468424, ENST00000258960, ENST00000592782 | |
| 256 | * - either of the transcript ids can be used to retrieve gene loci e.g. | |
| 257 | * http://rest.ensembl.org/map/cds/ENST00000592782/1..100000 | |
| 258 | * Example (invertebrate): | |
| 259 | * - fetch EMBLCDS cross-references for Uniprot entry Q43517 (FER1_SOLLC) | |
| 260 | * - the Uniprot entry has an xref to ENSEMBLPLANTS Solyc10g044520.1.1 | |
| 261 | * - can retrieve gene loci with | |
| 262 | * http://rest.ensemblgenomes.org/map/cds/Solyc10g044520.1.1/1..100000 | |
| 263 | * </pre> | |
| 264 | * | |
| 265 | * @param sequences | |
| 266 | */ | |
| 267 | 2 | public static void findGeneLoci(List<SequenceI> sequences) |
| 268 | { | |
| 269 | 2 | Map<DBRefEntry, GeneLociI> retrievedLoci = new HashMap<>(); |
| 270 | 2 | for (SequenceI seq : sequences) |
| 271 | { | |
| 272 | 22 | findGeneLoci(seq, retrievedLoci); |
| 273 | } | |
| 274 | } | |
| 275 | ||
| 276 | /** | |
| 277 | * Tres to find chromosomal coordinates for the sequence, by searching its | |
| 278 | * direct and indirect cross-references for Ensembl. If the loci have already | |
| 279 | * been retrieved, just reads them out of the map of retrievedLoci; this is | |
| 280 | * the case of an alternative transcript for the same protein. Otherwise calls | |
| 281 | * a REST service to retrieve the loci, and if successful, adds them to the | |
| 282 | * sequence and to the retrievedLoci. | |
| 283 | * | |
| 284 | * @param seq | |
| 285 | * @param retrievedLoci | |
| 286 | */ | |
| 287 | 22 | static void findGeneLoci(SequenceI seq, |
| 288 | Map<DBRefEntry, GeneLociI> retrievedLoci) | |
| 289 | { | |
| 290 | /* | |
| 291 | * don't replace any existing chromosomal coordinates | |
| 292 | */ | |
| 293 | 22 | if (seq == null || seq.isProtein() || seq.getGeneLoci() != null |
| 294 | || seq.getDBRefs() == null) | |
| 295 | { | |
| 296 | 22 | return; |
| 297 | } | |
| 298 | ||
| 299 | 0 | Set<String> ensemblDivisions = new EnsemblInfo().getDivisions(); |
| 300 | ||
| 301 | /* | |
| 302 | * first look for direct dbrefs from sequence to Ensembl | |
| 303 | */ | |
| 304 | 0 | String[] divisionsArray = ensemblDivisions |
| 305 | .toArray(new String[ensemblDivisions.size()]); | |
| 306 | 0 | List<DBRefEntry> seqRefs = seq.getDBRefs(); |
| 307 | 0 | List<DBRefEntry> directEnsemblRefs = DBRefUtils.selectRefs(seqRefs, |
| 308 | divisionsArray); | |
| 309 | 0 | if (directEnsemblRefs != null) |
| 310 | { | |
| 311 | 0 | for (DBRefEntry ensemblRef : directEnsemblRefs) |
| 312 | { | |
| 313 | 0 | if (fetchGeneLoci(seq, ensemblRef, retrievedLoci)) |
| 314 | { | |
| 315 | 0 | return; |
| 316 | } | |
| 317 | } | |
| 318 | } | |
| 319 | ||
| 320 | /* | |
| 321 | * else look for indirect dbrefs from sequence to Ensembl | |
| 322 | */ | |
| 323 | 0 | for (DBRefEntry dbref : seq.getDBRefs()) |
| 324 | { | |
| 325 | 0 | if (dbref.getMap() != null && dbref.getMap().getTo() != null) |
| 326 | { | |
| 327 | 0 | List<DBRefEntry> dbrefs = dbref.getMap().getTo().getDBRefs(); |
| 328 | 0 | List<DBRefEntry> indirectEnsemblRefs = DBRefUtils.selectRefs(dbrefs, |
| 329 | divisionsArray); | |
| 330 | 0 | if (indirectEnsemblRefs != null) |
| 331 | { | |
| 332 | 0 | for (DBRefEntry ensemblRef : indirectEnsemblRefs) |
| 333 | { | |
| 334 | 0 | if (fetchGeneLoci(seq, ensemblRef, retrievedLoci)) |
| 335 | { | |
| 336 | 0 | return; |
| 337 | } | |
| 338 | } | |
| 339 | } | |
| 340 | } | |
| 341 | } | |
| 342 | } | |
| 343 | ||
| 344 | /** | |
| 345 | * Retrieves chromosomal coordinates for the Ensembl (or EnsemblGenomes) | |
| 346 | * identifier in dbref. If successful, and the sequence length matches gene | |
| 347 | * loci length, then add it to the sequence, and to the retrievedLoci map. | |
| 348 | * Answers true if successful, else false. | |
| 349 | * | |
| 350 | * @param seq | |
| 351 | * @param dbref | |
| 352 | * @param retrievedLoci | |
| 353 | * @return | |
| 354 | */ | |
| 355 | 0 | static boolean fetchGeneLoci(SequenceI seq, DBRefEntry dbref, |
| 356 | Map<DBRefEntry, GeneLociI> retrievedLoci) | |
| 357 | { | |
| 358 | 0 | String accession = dbref.getAccessionId(); |
| 359 | 0 | String division = dbref.getSource(); |
| 360 | ||
| 361 | /* | |
| 362 | * hack: ignore cross-references to Ensembl protein ids | |
| 363 | * (or use map/translation perhaps?) | |
| 364 | * todo: is there an equivalent in EnsemblGenomes? | |
| 365 | */ | |
| 366 | 0 | if (accession.startsWith("ENSP")) |
| 367 | { | |
| 368 | 0 | return false; |
| 369 | } | |
| 370 | 0 | EnsemblMap mapper = new EnsemblMap(); |
| 371 | ||
| 372 | /* | |
| 373 | * try CDS mapping first | |
| 374 | */ | |
| 375 | 0 | GeneLociI geneLoci = mapper.getCdsMapping(division, accession, 1, |
| 376 | seq.getLength()); | |
| 377 | 0 | if (geneLoci != null) |
| 378 | { | |
| 379 | 0 | MapList map = geneLoci.getMapping(); |
| 380 | 0 | int mappedFromLength = MappingUtils.getLength(map.getFromRanges()); |
| 381 | 0 | if (mappedFromLength == seq.getLength()) |
| 382 | { | |
| 383 | 0 | seq.setGeneLoci(geneLoci.getSpeciesId(), geneLoci.getAssemblyId(), |
| 384 | geneLoci.getChromosomeId(), map); | |
| 385 | 0 | retrievedLoci.put(dbref, geneLoci); |
| 386 | 0 | return true; |
| 387 | } | |
| 388 | } | |
| 389 | ||
| 390 | /* | |
| 391 | * else try CDNA mapping | |
| 392 | */ | |
| 393 | 0 | geneLoci = mapper.getCdnaMapping(division, accession, 1, |
| 394 | seq.getLength()); | |
| 395 | 0 | if (geneLoci != null) |
| 396 | { | |
| 397 | 0 | MapList map = geneLoci.getMapping(); |
| 398 | 0 | int mappedFromLength = MappingUtils.getLength(map.getFromRanges()); |
| 399 | 0 | if (mappedFromLength == seq.getLength()) |
| 400 | { | |
| 401 | 0 | seq.setGeneLoci(geneLoci.getSpeciesId(), geneLoci.getAssemblyId(), |
| 402 | geneLoci.getChromosomeId(), map); | |
| 403 | 0 | retrievedLoci.put(dbref, geneLoci); |
| 404 | 0 | return true; |
| 405 | } | |
| 406 | } | |
| 407 | ||
| 408 | 0 | return false; |
| 409 | } | |
| 410 | ||
| 411 | /** | |
| 412 | * @param alignment | |
| 413 | * @param dataset | |
| 414 | * @param dna | |
| 415 | * @param xrefs | |
| 416 | * @param xrefsAlignment | |
| 417 | * @return | |
| 418 | */ | |
| 419 | 2 | protected AlignmentI copyAlignmentForSplitFrame(AlignmentI alignment, |
| 420 | AlignmentI dataset, boolean dna, AlignmentI xrefs, | |
| 421 | AlignmentI xrefsAlignment) | |
| 422 | { | |
| 423 | 2 | AlignmentI copyAlignment; |
| 424 | 2 | boolean copyAlignmentIsAligned = false; |
| 425 | 2 | if (dna) |
| 426 | { | |
| 427 | 2 | copyAlignment = AlignmentUtils.makeCdsAlignment(sel, dataset, |
| 428 | xrefsAlignment.getSequencesArray()); | |
| 429 | 2 | if (copyAlignment.getHeight() == 0) |
| 430 | { | |
| 431 | 0 | JvOptionPane.showMessageDialog(alignFrame, |
| 432 | MessageManager.getString("label.cant_map_cds"), | |
| 433 | MessageManager.getString("label.operation_failed"), | |
| 434 | JvOptionPane.OK_OPTION); | |
| 435 | 0 | jalview.bin.Console.errPrintln("Failed to make CDS alignment"); |
| 436 | 0 | return null; |
| 437 | } | |
| 438 | ||
| 439 | /* | |
| 440 | * pending getting Embl transcripts to 'align', | |
| 441 | * we are only doing this for Ensembl | |
| 442 | */ | |
| 443 | // TODO proper criteria for 'can align as cdna' | |
| 444 | 2 | if (DBRefSource.ENSEMBL.equalsIgnoreCase(source) |
| 445 | || AlignmentUtils.looksLikeEnsembl(alignment)) | |
| 446 | { | |
| 447 | 2 | copyAlignment.alignAs(alignment); |
| 448 | 2 | copyAlignmentIsAligned = true; |
| 449 | } | |
| 450 | } | |
| 451 | else | |
| 452 | { | |
| 453 | 0 | copyAlignment = AlignmentUtils.makeCopyAlignment(sel, |
| 454 | xrefs.getSequencesArray(), dataset); | |
| 455 | } | |
| 456 | 2 | copyAlignment.setGapCharacter(alignFrame.viewport.getGapCharacter()); |
| 457 | ||
| 458 | 2 | StructureSelectionManager ssm = StructureSelectionManager |
| 459 | .getStructureSelectionManager(Desktop.instance); | |
| 460 | ||
| 461 | /* | |
| 462 | * register any new mappings for sequence mouseover etc | |
| 463 | * (will not duplicate any previously registered mappings) | |
| 464 | */ | |
| 465 | 2 | ssm.registerMappings(dataset.getCodonFrames()); |
| 466 | ||
| 467 | 2 | if (copyAlignment.getHeight() <= 0) |
| 468 | { | |
| 469 | 0 | jalview.bin.Console |
| 470 | .errPrintln("No Sequences generated for xRef type " + source); | |
| 471 | 0 | return null; |
| 472 | } | |
| 473 | ||
| 474 | /* | |
| 475 | * align protein to dna | |
| 476 | */ | |
| 477 | 2 | if (dna && copyAlignmentIsAligned) |
| 478 | { | |
| 479 | 2 | xrefsAlignment.alignAs(copyAlignment); |
| 480 | } | |
| 481 | else | |
| 482 | { | |
| 483 | /* | |
| 484 | * align cdna to protein - currently only if | |
| 485 | * fetching and aligning Ensembl transcripts! | |
| 486 | */ | |
| 487 | // TODO: generalise for other sources of locus/transcript/cds data | |
| 488 | 0 | if (dna && DBRefSource.ENSEMBL.equalsIgnoreCase(source)) |
| 489 | { | |
| 490 | 0 | copyAlignment.alignAs(xrefsAlignment); |
| 491 | } | |
| 492 | } | |
| 493 | ||
| 494 | 2 | return copyAlignment; |
| 495 | } | |
| 496 | ||
| 497 | /** | |
| 498 | * Makes an alignment containing the given sequences, and adds them to the | |
| 499 | * given dataset, which is also set as the dataset for the new alignment | |
| 500 | * | |
| 501 | * TODO: refactor to DatasetI method | |
| 502 | * | |
| 503 | * @param dataset | |
| 504 | * @param seqs | |
| 505 | * @return | |
| 506 | */ | |
| 507 | 2 | protected AlignmentI makeCrossReferencesAlignment(AlignmentI dataset, |
| 508 | AlignmentI seqs) | |
| 509 | { | |
| 510 | 2 | SequenceI[] sprods = new SequenceI[seqs.getHeight()]; |
| 511 | 24 | for (int s = 0; s < sprods.length; s++) |
| 512 | { | |
| 513 | 22 | sprods[s] = (seqs.getSequenceAt(s)).deriveSequence(); |
| 514 | 22 | if (dataset.getSequences() == null || !dataset.getSequences() |
| 515 | .contains(sprods[s].getDatasetSequence())) | |
| 516 | { | |
| 517 | 0 | dataset.addSequence(sprods[s].getDatasetSequence()); |
| 518 | } | |
| 519 | 22 | sprods[s].updatePDBIds(); |
| 520 | } | |
| 521 | 2 | Alignment al = new Alignment(sprods); |
| 522 | 2 | al.setDataset(dataset); |
| 523 | 2 | return al; |
| 524 | } | |
| 525 | ||
| 526 | /** | |
| 527 | * Constructor | |
| 528 | * | |
| 529 | * @param af | |
| 530 | * @param seqs | |
| 531 | * @param fromDna | |
| 532 | * @param dbSource | |
| 533 | */ | |
| 534 | 2 | CrossRefAction(AlignFrame af, SequenceI[] seqs, boolean fromDna, |
| 535 | String dbSource) | |
| 536 | { | |
| 537 | 2 | this.alignFrame = af; |
| 538 | 2 | this.sel = seqs; |
| 539 | 2 | this._odna = fromDna; |
| 540 | 2 | this.source = dbSource; |
| 541 | } | |
| 542 | ||
| 543 | 2 | public static CrossRefAction getHandlerFor(final SequenceI[] sel, |
| 544 | final boolean fromDna, final String source, | |
| 545 | final AlignFrame alignFrame) | |
| 546 | { | |
| 547 | 2 | return new CrossRefAction(alignFrame, sel, fromDna, source); |
| 548 | } | |
| 549 | ||
| 550 | } |