Coverage Report
File Dna.java
Coverage histogram
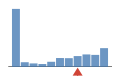
29% of files have more coverage
Classes
Class |
Line # |
Actions |
|||
|---|---|---|---|---|---|
| Dna | 50 | 371 | 138 |
Contributing tests
This file is covered by 16 tests.
.
Source view
| 1 | /* | |
| 2 | * Jalview - A Sequence Alignment Editor and Viewer ($$Version-Rel$$) | |
| 3 | * Copyright (C) $$Year-Rel$$ The Jalview Authors | |
| 4 | * | |
| 5 | * This file is part of Jalview. | |
| 6 | * | |
| 7 | * Jalview is free software: you can redistribute it and/or | |
| 8 | * modify it under the terms of the GNU General Public License | |
| 9 | * as published by the Free Software Foundation, either version 3 | |
| 10 | * of the License, or (at your option) any later version. | |
| 11 | * | |
| 12 | * Jalview is distributed in the hope that it will be useful, but | |
| 13 | * WITHOUT ANY WARRANTY; without even the implied warranty | |
| 14 | * of MERCHANTABILITY or FITNESS FOR A PARTICULAR | |
| 15 | * PURPOSE. See the GNU General Public License for more details. | |
| 16 | * | |
| 17 | * You should have received a copy of the GNU General Public License | |
| 18 | * along with Jalview. If not, see <http://www.gnu.org/licenses/>. | |
| 19 | * The Jalview Authors are detailed in the 'AUTHORS' file. | |
| 20 | */ | |
| 21 | package jalview.analysis; | |
| 22 | ||
| 23 | import jalview.api.AlignViewportI; | |
| 24 | import jalview.datamodel.AlignedCodon; | |
| 25 | import jalview.datamodel.AlignedCodonFrame; | |
| 26 | import jalview.datamodel.Alignment; | |
| 27 | import jalview.datamodel.AlignmentAnnotation; | |
| 28 | import jalview.datamodel.AlignmentI; | |
| 29 | import jalview.datamodel.Annotation; | |
| 30 | import jalview.datamodel.DBRefEntry; | |
| 31 | import jalview.datamodel.DBRefSource; | |
| 32 | import jalview.datamodel.FeatureProperties; | |
| 33 | import jalview.datamodel.GraphLine; | |
| 34 | import jalview.datamodel.Mapping; | |
| 35 | import jalview.datamodel.Sequence; | |
| 36 | import jalview.datamodel.SequenceFeature; | |
| 37 | import jalview.datamodel.SequenceI; | |
| 38 | import jalview.schemes.ResidueProperties; | |
| 39 | import jalview.util.Comparison; | |
| 40 | import jalview.util.DBRefUtils; | |
| 41 | import jalview.util.MapList; | |
| 42 | import jalview.util.ShiftList; | |
| 43 | ||
| 44 | import java.util.ArrayList; | |
| 45 | import java.util.Arrays; | |
| 46 | import java.util.Comparator; | |
| 47 | import java.util.Iterator; | |
| 48 | import java.util.List; | |
| 49 | ||
| 50 | public class Dna | |
| 51 | { | |
| 52 | private static final String STOP_ASTERIX = "*"; | |
| 53 | ||
| 54 | private static final Comparator<AlignedCodon> comparator = new CodonComparator(); | |
| 55 | ||
| 56 | /* | |
| 57 | * 'final' variables describe the inputs to the translation, which should not | |
| 58 | * be modified. | |
| 59 | */ | |
| 60 | private final List<SequenceI> selection; | |
| 61 | ||
| 62 | private final String[] seqstring; | |
| 63 | ||
| 64 | private final Iterator<int[]> contigs; | |
| 65 | ||
| 66 | private final char gapChar; | |
| 67 | ||
| 68 | private final AlignmentAnnotation[] annotations; | |
| 69 | ||
| 70 | private final int dnaWidth; | |
| 71 | ||
| 72 | private final AlignmentI dataset; | |
| 73 | ||
| 74 | private ShiftList vismapping; | |
| 75 | ||
| 76 | private int[] startcontigs; | |
| 77 | ||
| 78 | /* | |
| 79 | * Working variables for the translation. | |
| 80 | * | |
| 81 | * The width of the translation-in-progress protein alignment. | |
| 82 | */ | |
| 83 | private int aaWidth = 0; | |
| 84 | ||
| 85 | /* | |
| 86 | * This array will be built up so that position i holds the codon positions | |
| 87 | * e.g. [7, 9, 10] that match column i (base 0) in the aligned translation. | |
| 88 | * Note this implies a contract that if two codons do not align exactly, their | |
| 89 | * translated products must occupy different column positions. | |
| 90 | */ | |
| 91 | private AlignedCodon[] alignedCodons; | |
| 92 | ||
| 93 | /** | |
| 94 | * Constructor given a viewport and the visible contigs. | |
| 95 | * | |
| 96 | * @param viewport | |
| 97 | * @param visibleContigs | |
| 98 | */ | |
| 99 | 24 |  public Dna(AlignViewportI viewport, Iterator<int[]> visibleContigs) public Dna(AlignViewportI viewport, Iterator<int[]> visibleContigs) |
| 100 | { | |
| 101 | 24 | this.selection = Arrays.asList(viewport.getSequenceSelection()); |
| 102 | 24 | this.seqstring = viewport.getViewAsString(true); |
| 103 | 24 | this.contigs = visibleContigs; |
| 104 | 24 | this.gapChar = viewport.getGapCharacter(); |
| 105 | 24 | this.annotations = viewport.getAlignment().getAlignmentAnnotation(); |
| 106 | 24 | this.dnaWidth = viewport.getAlignment().getWidth(); |
| 107 | 24 | this.dataset = viewport.getAlignment().getDataset(); |
| 108 | 24 | initContigs(); |
| 109 | } | |
| 110 | ||
| 111 | /** | |
| 112 | * Initialise contigs used as starting point for translateCodingRegion | |
| 113 | */ | |
| 114 | 24 | private void initContigs() |
| 115 | { | |
| 116 | 24 | vismapping = new ShiftList(); // map from viscontigs to seqstring |
| 117 | // intervals | |
| 118 | ||
| 119 | 24 | int npos = 0; |
| 120 | 24 | int[] lastregion = null; |
| 121 | 24 | ArrayList<Integer> tempcontigs = new ArrayList<>(); |
| 122 | 50 | while (contigs.hasNext()) |
| 123 | { | |
| 124 | 26 | int[] region = contigs.next(); |
| 125 | 26 | if (lastregion == null) |
| 126 | { | |
| 127 | 24 | vismapping.addShift(npos, region[0]); |
| 128 | } | |
| 129 | else | |
| 130 | { | |
| 131 | // hidden region | |
| 132 | 2 | vismapping.addShift(npos, region[0] - lastregion[1] + 1); |
| 133 | } | |
| 134 | 26 | lastregion = region; |
| 135 | 26 | tempcontigs.add(region[0]); |
| 136 | 26 | tempcontigs.add(region[1]); |
| 137 | } | |
| 138 | ||
| 139 | 24 | startcontigs = new int[tempcontigs.size()]; |
| 140 | 24 | int i = 0; |
| 141 | 24 | for (Integer val : tempcontigs) |
| 142 | { | |
| 143 | 52 | startcontigs[i] = val; |
| 144 | 52 | i++; |
| 145 | } | |
| 146 | 24 | tempcontigs = null; |
| 147 | } | |
| 148 | ||
| 149 | /** | |
| 150 | * Test whether codon positions cdp1 should align before, with, or after cdp2. | |
| 151 | * Returns zero if all positions match (or either argument is null). Returns | |
| 152 | * -1 if any position in the first codon precedes the corresponding position | |
| 153 | * in the second codon. Else returns +1 (some position in the second codon | |
| 154 | * precedes the corresponding position in the first). | |
| 155 | * | |
| 156 | * Note this is not necessarily symmetric, for example: | |
| 157 | * <ul> | |
| 158 | * <li>compareCodonPos([2,5,6], [3,4,5]) returns -1</li> | |
| 159 | * <li>compareCodonPos([3,4,5], [2,5,6]) also returns -1</li> | |
| 160 | * </ul> | |
| 161 | * | |
| 162 | * @param ac1 | |
| 163 | * @param ac2 | |
| 164 | * @return | |
| 165 | */ | |
| 166 | 3347 | public static final int compareCodonPos(AlignedCodon ac1, |
| 167 | AlignedCodon ac2) | |
| 168 | { | |
| 169 | 3347 | return comparator.compare(ac1, ac2); |
| 170 | // return jalview_2_8_2compare(ac1, ac2); | |
| 171 | } | |
| 172 | ||
| 173 | /** | |
| 174 | * Codon comparison up to Jalview 2.8.2. This rule is sequence order dependent | |
| 175 | * - see http://issues.jalview.org/browse/JAL-1635 | |
| 176 | * | |
| 177 | * @param ac1 | |
| 178 | * @param ac2 | |
| 179 | * @return | |
| 180 | */ | |
| 181 | 0 | private static int jalview_2_8_2compare(AlignedCodon ac1, |
| 182 | AlignedCodon ac2) | |
| 183 | { | |
| 184 | 0 | if (ac1 == null || ac2 == null || (ac1.equals(ac2))) |
| 185 | { | |
| 186 | 0 | return 0; |
| 187 | } | |
| 188 | 0 | if (ac1.pos1 < ac2.pos1 || ac1.pos2 < ac2.pos2 || ac1.pos3 < ac2.pos3) |
| 189 | { | |
| 190 | // one base in cdp1 precedes the corresponding base in the other codon | |
| 191 | 0 | return -1; |
| 192 | } | |
| 193 | // one base in cdp1 appears after the corresponding base in the other codon. | |
| 194 | 0 | return 1; |
| 195 | } | |
| 196 | ||
| 197 | /** | |
| 198 | * Translates cDNA using the specified code table | |
| 199 | * | |
| 200 | * @return | |
| 201 | */ | |
| 202 | 23 | public AlignmentI translateCdna(GeneticCodeI codeTable) |
| 203 | { | |
| 204 | 23 | AlignedCodonFrame acf = new AlignedCodonFrame(); |
| 205 | ||
| 206 | 23 | alignedCodons = new AlignedCodon[dnaWidth]; |
| 207 | ||
| 208 | 23 | int s; |
| 209 | 23 | int sSize = selection.size(); |
| 210 | 23 | List<SequenceI> pepseqs = new ArrayList<>(); |
| 211 | 240 | for (s = 0; s < sSize; s++) |
| 212 | { | |
| 213 | 217 | SequenceI newseq = translateCodingRegion(selection.get(s), |
| 214 | seqstring[s], acf, pepseqs, codeTable); | |
| 215 | ||
| 216 | 217 | if (newseq != null) |
| 217 | { | |
| 218 | 217 | pepseqs.add(newseq); |
| 219 | 217 | SequenceI ds = newseq; |
| 220 | 217 | if (dataset != null) |
| 221 | { | |
| 222 | 2 | while (ds.getDatasetSequence() != null) |
| 223 | { | |
| 224 | 1 | ds = ds.getDatasetSequence(); |
| 225 | } | |
| 226 | 1 | dataset.addSequence(ds); |
| 227 | } | |
| 228 | } | |
| 229 | } | |
| 230 | ||
| 231 | 23 | SequenceI[] newseqs = pepseqs.toArray(new SequenceI[pepseqs.size()]); |
| 232 | 23 | AlignmentI al = new Alignment(newseqs); |
| 233 | // ensure we look aligned. | |
| 234 | 23 | al.padGaps(); |
| 235 | // link the protein translation to the DNA dataset | |
| 236 | 23 | al.setDataset(dataset); |
| 237 | 23 | translateAlignedAnnotations(al, acf); |
| 238 | 23 | al.addCodonFrame(acf); |
| 239 | 23 | return al; |
| 240 | } | |
| 241 | ||
| 242 | /** | |
| 243 | * fake the collection of DbRefs with associated exon mappings to identify if | |
| 244 | * a translation would generate distinct product in the currently selected | |
| 245 | * region. | |
| 246 | * | |
| 247 | * @param selection | |
| 248 | * @param viscontigs | |
| 249 | * @return | |
| 250 | */ | |
| 251 | 0 | public static boolean canTranslate(SequenceI[] selection, |
| 252 | int viscontigs[]) | |
| 253 | { | |
| 254 | 0 | for (int gd = 0; gd < selection.length; gd++) |
| 255 | { | |
| 256 | 0 | SequenceI dna = selection[gd]; |
| 257 | 0 | List<DBRefEntry> dnarefs = DBRefUtils.selectRefs(dna.getDBRefs(), |
| 258 | jalview.datamodel.DBRefSource.DNACODINGDBS); | |
| 259 | 0 | if (dnarefs != null) |
| 260 | { | |
| 261 | // intersect with pep | |
| 262 | 0 | List<DBRefEntry> mappedrefs = new ArrayList<>(); |
| 263 | 0 | List<DBRefEntry> refs = dna.getDBRefs(); |
| 264 | 0 | for (int d = 0, nd = refs.size(); d < nd; d++) |
| 265 | { | |
| 266 | 0 | DBRefEntry ref = refs.get(d); |
| 267 | 0 | if (ref.getMap() != null && ref.getMap().getMap() != null |
| 268 | && ref.getMap().getMap().getFromRatio() == 3 | |
| 269 | && ref.getMap().getMap().getToRatio() == 1) | |
| 270 | { | |
| 271 | 0 | mappedrefs.add(ref); // add translated protein maps |
| 272 | } | |
| 273 | } | |
| 274 | 0 | dnarefs = mappedrefs;// .toArray(new DBRefEntry[mappedrefs.size()]); |
| 275 | 0 | for (int d = 0, nd = dnarefs.size(); d < nd; d++) |
| 276 | { | |
| 277 | 0 | Mapping mp = dnarefs.get(d).getMap(); |
| 278 | 0 | if (mp != null) |
| 279 | { | |
| 280 | 0 | for (int vc = 0, nv = viscontigs.length; vc < nv; vc += 2) |
| 281 | { | |
| 282 | 0 | int[] mpr = mp.locateMappedRange(viscontigs[vc], |
| 283 | viscontigs[vc + 1]); | |
| 284 | 0 | if (mpr != null) |
| 285 | { | |
| 286 | 0 | return true; |
| 287 | } | |
| 288 | } | |
| 289 | } | |
| 290 | } | |
| 291 | } | |
| 292 | } | |
| 293 | 0 | return false; |
| 294 | } | |
| 295 | ||
| 296 | /** | |
| 297 | * Translate nucleotide alignment annotations onto translated amino acid | |
| 298 | * alignment using codon mapping codons | |
| 299 | * | |
| 300 | * @param al | |
| 301 | * the translated protein alignment | |
| 302 | */ | |
| 303 | 23 | protected void translateAlignedAnnotations(AlignmentI al, |
| 304 | AlignedCodonFrame acf) | |
| 305 | { | |
| 306 | // Can only do this for columns with consecutive codons, or where | |
| 307 | // annotation is sequence associated. | |
| 308 | ||
| 309 | 23 | if (annotations != null) |
| 310 | { | |
| 311 | 23 | for (AlignmentAnnotation annotation : annotations) |
| 312 | { | |
| 313 | /* | |
| 314 | * Skip hidden or autogenerated annotation. Also (for now), RNA | |
| 315 | * secondary structure annotation. If we want to show this against | |
| 316 | * protein we need a smarter way to 'translate' without generating | |
| 317 | * invalid (unbalanced) structure annotation. | |
| 318 | */ | |
| 319 | 318 | if (annotation.autoCalculated || !annotation.visible |
| 320 | || annotation.isRNA()) | |
| 321 | { | |
| 322 | 318 | continue; |
| 323 | } | |
| 324 | ||
| 325 | 0 | int aSize = aaWidth; |
| 326 | 0 | Annotation[] anots = (annotation.annotations == null) ? null |
| 327 | : new Annotation[aSize]; | |
| 328 | 0 | if (anots != null) |
| 329 | { | |
| 330 | 0 | for (int a = 0; a < aSize; a++) |
| 331 | { | |
| 332 | // process through codon map. | |
| 333 | 0 | if (a < alignedCodons.length && alignedCodons[a] != null |
| 334 | && alignedCodons[a].pos1 == (alignedCodons[a].pos3 - 2)) | |
| 335 | { | |
| 336 | 0 | anots[a] = getCodonAnnotation(alignedCodons[a], |
| 337 | annotation.annotations); | |
| 338 | } | |
| 339 | } | |
| 340 | } | |
| 341 | ||
| 342 | 0 | AlignmentAnnotation aa = new AlignmentAnnotation(annotation.label, |
| 343 | annotation.description, anots); | |
| 344 | 0 | aa.graph = annotation.graph; |
| 345 | 0 | aa.graphGroup = annotation.graphGroup; |
| 346 | 0 | aa.graphHeight = annotation.graphHeight; |
| 347 | 0 | if (annotation.getThreshold() != null) |
| 348 | { | |
| 349 | 0 | aa.setThreshold(new GraphLine(annotation.getThreshold())); |
| 350 | } | |
| 351 | 0 | if (annotation.hasScore) |
| 352 | { | |
| 353 | 0 | aa.setScore(annotation.getScore()); |
| 354 | } | |
| 355 | ||
| 356 | 0 | final SequenceI seqRef = annotation.sequenceRef; |
| 357 | 0 | if (seqRef != null) |
| 358 | { | |
| 359 | 0 | SequenceI aaSeq = acf.getAaForDnaSeq(seqRef); |
| 360 | 0 | if (aaSeq != null) |
| 361 | { | |
| 362 | // aa.compactAnnotationArray(); // throw away alignment annotation | |
| 363 | // positioning | |
| 364 | 0 | aa.setSequenceRef(aaSeq); |
| 365 | // rebuild mapping | |
| 366 | 0 | aa.createSequenceMapping(aaSeq, aaSeq.getStart(), true); |
| 367 | 0 | aa.adjustForAlignment(); |
| 368 | 0 | aaSeq.addAlignmentAnnotation(aa); |
| 369 | } | |
| 370 | } | |
| 371 | 0 | al.addAnnotation(aa); |
| 372 | } | |
| 373 | } | |
| 374 | } | |
| 375 | ||
| 376 | 0 | private static Annotation getCodonAnnotation(AlignedCodon is, |
| 377 | Annotation[] annotations) | |
| 378 | { | |
| 379 | // Have a look at all the codon positions for annotation and put the first | |
| 380 | // one found into the translated annotation pos. | |
| 381 | 0 | int contrib = 0; |
| 382 | 0 | Annotation annot = null; |
| 383 | 0 | for (int p = 1; p <= 3; p++) |
| 384 | { | |
| 385 | 0 | int dnaCol = is.getBaseColumn(p); |
| 386 | 0 | if (annotations[dnaCol] != null) |
| 387 | { | |
| 388 | 0 | if (annot == null) |
| 389 | { | |
| 390 | 0 | annot = new Annotation(annotations[dnaCol]); |
| 391 | 0 | contrib = 1; |
| 392 | } | |
| 393 | else | |
| 394 | { | |
| 395 | // merge with last | |
| 396 | 0 | Annotation cpy = new Annotation(annotations[dnaCol]); |
| 397 | 0 | if (annot.colour == null) |
| 398 | { | |
| 399 | 0 | annot.colour = cpy.colour; |
| 400 | } | |
| 401 | 0 | if (annot.description == null || annot.description.length() == 0) |
| 402 | { | |
| 403 | 0 | annot.description = cpy.description; |
| 404 | } | |
| 405 | 0 | if (annot.displayCharacter == null) |
| 406 | { | |
| 407 | 0 | annot.displayCharacter = cpy.displayCharacter; |
| 408 | } | |
| 409 | 0 | if (annot.secondaryStructure == 0) |
| 410 | { | |
| 411 | 0 | annot.secondaryStructure = cpy.secondaryStructure; |
| 412 | } | |
| 413 | 0 | annot.value += cpy.value; |
| 414 | 0 | contrib++; |
| 415 | } | |
| 416 | } | |
| 417 | } | |
| 418 | 0 | if (contrib > 1) |
| 419 | { | |
| 420 | 0 | annot.value /= contrib; |
| 421 | } | |
| 422 | 0 | return annot; |
| 423 | } | |
| 424 | ||
| 425 | /** | |
| 426 | * Translate a na sequence | |
| 427 | * | |
| 428 | * @param selection | |
| 429 | * sequence displayed under viscontigs visible columns | |
| 430 | * @param seqstring | |
| 431 | * ORF read in some global alignment reference frame | |
| 432 | * @param acf | |
| 433 | * Definition of global ORF alignment reference frame | |
| 434 | * @param proteinSeqs | |
| 435 | * @param codeTable | |
| 436 | * @return sequence ready to be added to alignment. | |
| 437 | */ | |
| 438 | 217 | protected SequenceI translateCodingRegion(SequenceI selection, |
| 439 | String seqstring, AlignedCodonFrame acf, | |
| 440 | List<SequenceI> proteinSeqs, GeneticCodeI codeTable) | |
| 441 | { | |
| 442 | 217 | List<int[]> skip = new ArrayList<>(); |
| 443 | 217 | int[] skipint = null; |
| 444 | ||
| 445 | 217 | int npos = 0; |
| 446 | 217 | int vc = 0; |
| 447 | ||
| 448 | 217 | int[] scontigs = new int[startcontigs.length]; |
| 449 | 217 | System.arraycopy(startcontigs, 0, scontigs, 0, startcontigs.length); |
| 450 | ||
| 451 | // allocate a roughly sized buffer for the protein sequence | |
| 452 | 217 | StringBuilder protein = new StringBuilder(seqstring.length() / 2); |
| 453 | 217 | String seq = seqstring.replace('U', 'T').replace('u', 'T'); |
| 454 | 217 | char codon[] = new char[3]; |
| 455 | 217 | int cdp[] = new int[3]; |
| 456 | 217 | int rf = 0; |
| 457 | 217 | int lastnpos = 0; |
| 458 | 217 | int nend; |
| 459 | 217 | int aspos = 0; |
| 460 | 217 | int resSize = 0; |
| 461 | 6275 | for (npos = 0, nend = seq.length(); npos < nend; npos++) |
| 462 | { | |
| 463 | 6058 | if (!Comparison.isGap(seq.charAt(npos))) |
| 464 | { | |
| 465 | 6028 | cdp[rf] = npos; // store position |
| 466 | 6028 | codon[rf++] = seq.charAt(npos); // store base |
| 467 | } | |
| 468 | 6058 | if (rf == 3) |
| 469 | { | |
| 470 | /* | |
| 471 | * Filled up a reading frame... | |
| 472 | */ | |
| 473 | 1888 | AlignedCodon alignedCodon = new AlignedCodon(cdp[0], cdp[1], |
| 474 | cdp[2]); | |
| 475 | 1888 | String aa = codeTable.translate(new String(codon)); |
| 476 | 1888 | rf = 0; |
| 477 | 1888 | final String gapString = String.valueOf(gapChar); |
| 478 | 1888 | if (aa == null) |
| 479 | { | |
| 480 | 1 | aa = gapString; |
| 481 | 1 | if (skipint == null) |
| 482 | { | |
| 483 | 1 | skipint = new int[] { alignedCodon.pos1, |
| 484 | alignedCodon.pos3 /* | |
| 485 | * cdp[0], | |
| 486 | * cdp[2] | |
| 487 | */ }; | |
| 488 | } | |
| 489 | 1 | skipint[1] = alignedCodon.pos3; // cdp[2]; |
| 490 | } | |
| 491 | else | |
| 492 | { | |
| 493 | 1887 | if (skipint != null) |
| 494 | { | |
| 495 | // edit scontigs | |
| 496 | 1 | skipint[0] = vismapping.shift(skipint[0]); |
| 497 | 1 | skipint[1] = vismapping.shift(skipint[1]); |
| 498 | 2 | for (vc = 0; vc < scontigs.length;) |
| 499 | { | |
| 500 | 1 | if (scontigs[vc + 1] < skipint[0]) |
| 501 | { | |
| 502 | // before skipint starts | |
| 503 | 0 | vc += 2; |
| 504 | 0 | continue; |
| 505 | } | |
| 506 | 1 | if (scontigs[vc] > skipint[1]) |
| 507 | { | |
| 508 | // finished editing so | |
| 509 | 0 | break; |
| 510 | } | |
| 511 | // Edit the contig list to include the skipped region which did | |
| 512 | // not translate | |
| 513 | 1 | int[] t; |
| 514 | // from : s1 e1 s2 e2 s3 e3 | |
| 515 | // to s: s1 e1 s2 k0 k1 e2 s3 e3 | |
| 516 | // list increases by one unless one boundary (s2==k0 or e2==k1) | |
| 517 | // matches, and decreases by one if skipint intersects whole | |
| 518 | // visible contig | |
| 519 | 1 | if (scontigs[vc] <= skipint[0]) |
| 520 | { | |
| 521 | 1 | if (skipint[0] == scontigs[vc]) |
| 522 | { | |
| 523 | // skipint at start of contig | |
| 524 | // shift the start of this contig | |
| 525 | 0 | if (scontigs[vc + 1] > skipint[1]) |
| 526 | { | |
| 527 | 0 | scontigs[vc] = skipint[1]; |
| 528 | 0 | vc += 2; |
| 529 | } | |
| 530 | else | |
| 531 | { | |
| 532 | 0 | if (scontigs[vc + 1] == skipint[1]) |
| 533 | { | |
| 534 | // remove the contig | |
| 535 | 0 | t = new int[scontigs.length - 2]; |
| 536 | 0 | if (vc > 0) |
| 537 | { | |
| 538 | 0 | System.arraycopy(scontigs, 0, t, 0, vc - 1); |
| 539 | } | |
| 540 | 0 | if (vc + 2 < t.length) |
| 541 | { | |
| 542 | 0 | System.arraycopy(scontigs, vc + 2, t, vc, |
| 543 | t.length - vc + 2); | |
| 544 | } | |
| 545 | 0 | scontigs = t; |
| 546 | } | |
| 547 | else | |
| 548 | { | |
| 549 | // truncate contig to before the skipint region | |
| 550 | 0 | scontigs[vc + 1] = skipint[0] - 1; |
| 551 | 0 | vc += 2; |
| 552 | } | |
| 553 | } | |
| 554 | } | |
| 555 | else | |
| 556 | { | |
| 557 | // scontig starts before start of skipint | |
| 558 | 1 | if (scontigs[vc + 1] < skipint[1]) |
| 559 | { | |
| 560 | // skipint truncates end of scontig | |
| 561 | 0 | scontigs[vc + 1] = skipint[0] - 1; |
| 562 | 0 | vc += 2; |
| 563 | } | |
| 564 | else | |
| 565 | { | |
| 566 | // divide region to new contigs | |
| 567 | 1 | t = new int[scontigs.length + 2]; |
| 568 | 1 | System.arraycopy(scontigs, 0, t, 0, vc + 1); |
| 569 | 1 | t[vc + 1] = skipint[0]; |
| 570 | 1 | t[vc + 2] = skipint[1]; |
| 571 | 1 | System.arraycopy(scontigs, vc + 1, t, vc + 3, |
| 572 | scontigs.length - (vc + 1)); | |
| 573 | 1 | scontigs = t; |
| 574 | 1 | vc += 4; |
| 575 | } | |
| 576 | } | |
| 577 | } | |
| 578 | } | |
| 579 | 1 | skip.add(skipint); |
| 580 | 1 | skipint = null; |
| 581 | } | |
| 582 | 1887 | if (aa.equals(ResidueProperties.STOP)) |
| 583 | { | |
| 584 | 0 | aa = STOP_ASTERIX; |
| 585 | } | |
| 586 | 1887 | resSize++; |
| 587 | } | |
| 588 | 1888 | boolean findpos = true; |
| 589 | 5150 | while (findpos) |
| 590 | { | |
| 591 | /* | |
| 592 | * Compare this codon's base positions with those currently aligned to | |
| 593 | * this column in the translation. | |
| 594 | */ | |
| 595 | 3262 | final int compareCodonPos = compareCodonPos(alignedCodon, |
| 596 | alignedCodons[aspos]); | |
| 597 | 3262 | switch (compareCodonPos) |
| 598 | { | |
| 599 | 178 | case -1: |
| 600 | ||
| 601 | /* | |
| 602 | * This codon should precede the mapped positions - need to insert a | |
| 603 | * gap in all prior sequences. | |
| 604 | */ | |
| 605 | 178 | insertAAGap(aspos, proteinSeqs); |
| 606 | 178 | findpos = false; |
| 607 | 178 | break; |
| 608 | ||
| 609 | 1374 | case +1: |
| 610 | ||
| 611 | /* | |
| 612 | * This codon belongs after the aligned codons at aspos. Prefix it | |
| 613 | * with a gap and try the next position. | |
| 614 | */ | |
| 615 | 1374 | aa = gapString + aa; |
| 616 | 1374 | aspos++; |
| 617 | 1374 | break; |
| 618 | ||
| 619 | 1710 | case 0: |
| 620 | ||
| 621 | /* | |
| 622 | * Exact match - codon 'belongs' at this translated position. | |
| 623 | */ | |
| 624 | 1710 | findpos = false; |
| 625 | } | |
| 626 | } | |
| 627 | 1888 | protein.append(aa); |
| 628 | 1888 | lastnpos = npos; |
| 629 | 1888 | if (alignedCodons[aspos] == null) |
| 630 | { | |
| 631 | // mark this column as aligning to this aligned reading frame | |
| 632 | 466 | alignedCodons[aspos] = alignedCodon; |
| 633 | } | |
| 634 | 1422 | else if (!alignedCodons[aspos].equals(alignedCodon)) |
| 635 | { | |
| 636 | 0 | throw new IllegalStateException( |
| 637 | "Tried to coalign " + alignedCodons[aspos].toString() | |
| 638 | + " with " + alignedCodon.toString()); | |
| 639 | } | |
| 640 | 1888 | if (aspos >= aaWidth) |
| 641 | { | |
| 642 | // update maximum alignment width | |
| 643 | 449 | aaWidth = aspos; |
| 644 | } | |
| 645 | // ready for next translated reading frame alignment position (if any) | |
| 646 | 1888 | aspos++; |
| 647 | } | |
| 648 | } | |
| 649 | 217 | if (resSize > 0) |
| 650 | { | |
| 651 | 217 | SequenceI newseq = new Sequence(selection.getName(), |
| 652 | protein.toString()); | |
| 653 | 217 | if (rf != 0) |
| 654 | { | |
| 655 | 188 | final String errMsg = "trimming contigs for incomplete terminal codon."; |
| 656 | 188 | jalview.bin.Console.errPrintln(errMsg); |
| 657 | // map and trim contigs to ORF region | |
| 658 | 188 | vc = scontigs.length - 1; |
| 659 | 188 | lastnpos = vismapping.shift(lastnpos); // place npos in context of |
| 660 | // whole dna alignment (rather | |
| 661 | // than visible contigs) | |
| 662 | // incomplete ORF could be broken over one or two visible contig | |
| 663 | // intervals. | |
| 664 | 376 | while (vc >= 0 && scontigs[vc] > lastnpos) |
| 665 | { | |
| 666 | 188 | if (vc > 0 && scontigs[vc - 1] > lastnpos) |
| 667 | { | |
| 668 | 0 | vc -= 2; |
| 669 | } | |
| 670 | else | |
| 671 | { | |
| 672 | // correct last interval in list. | |
| 673 | 188 | scontigs[vc] = lastnpos; |
| 674 | } | |
| 675 | } | |
| 676 | ||
| 677 | 188 | if (vc > 0 && (vc + 1) < scontigs.length) |
| 678 | { | |
| 679 | // truncate map list to just vc elements | |
| 680 | 0 | int t[] = new int[vc + 1]; |
| 681 | 0 | System.arraycopy(scontigs, 0, t, 0, vc + 1); |
| 682 | 0 | scontigs = t; |
| 683 | } | |
| 684 | 188 | if (vc <= 0) |
| 685 | { | |
| 686 | 0 | scontigs = null; |
| 687 | } | |
| 688 | } | |
| 689 | 217 | if (scontigs != null) |
| 690 | { | |
| 691 | 217 | npos = 0; |
| 692 | // map scontigs to actual sequence positions on selection | |
| 693 | 412 | for (vc = 0; vc < scontigs.length; vc += 2) |
| 694 | { | |
| 695 | 220 | scontigs[vc] = selection.findPosition(scontigs[vc]); // not from 1! |
| 696 | 220 | scontigs[vc + 1] = selection.findPosition(scontigs[vc + 1]); // exclusive |
| 697 | 220 | if (scontigs[vc + 1] == selection.getEnd()) |
| 698 | { | |
| 699 | 25 | break; |
| 700 | } | |
| 701 | } | |
| 702 | // trim trailing empty intervals. | |
| 703 | 217 | if ((vc + 2) < scontigs.length) |
| 704 | { | |
| 705 | 0 | int t[] = new int[vc + 2]; |
| 706 | 0 | System.arraycopy(scontigs, 0, t, 0, vc + 2); |
| 707 | 0 | scontigs = t; |
| 708 | } | |
| 709 | /* | |
| 710 | * delete intervals in scontigs which are not translated. 1. map skip | |
| 711 | * into sequence position intervals 2. truncate existing ranges and add | |
| 712 | * new ranges to exclude untranslated regions. if (skip.size()>0) { | |
| 713 | * Vector narange = new Vector(); for (vc=0; vc<scontigs.length; vc++) { | |
| 714 | * narange.addElement(new int[] {scontigs[vc]}); } int sint=0,iv[]; vc = | |
| 715 | * 0; while (sint<skip.size()) { skipint = (int[]) skip.elementAt(sint); | |
| 716 | * do { iv = (int[]) narange.elementAt(vc); if (iv[0]>=skipint[0] && | |
| 717 | * iv[0]<=skipint[1]) { if (iv[0]==skipint[0]) { // delete beginning of | |
| 718 | * range } else { // truncate range and create new one if necessary iv = | |
| 719 | * (int[]) narange.elementAt(vc+1); if (iv[0]<=skipint[1]) { // truncate | |
| 720 | * range iv[0] = skipint[1]; } else { } } } else if (iv[0]<skipint[0]) { | |
| 721 | * iv = (int[]) narange.elementAt(vc+1); } } while (iv[0]) } } | |
| 722 | */ | |
| 723 | 217 | MapList map = new MapList(scontigs, new int[] { 1, resSize }, 3, 1); |
| 724 | ||
| 725 | 217 | transferCodedFeatures(selection, newseq, map); |
| 726 | ||
| 727 | /* | |
| 728 | * Construct a dataset sequence for our new peptide. | |
| 729 | */ | |
| 730 | 217 | SequenceI rseq = newseq.deriveSequence(); |
| 731 | ||
| 732 | /* | |
| 733 | * Store a mapping (between the dataset sequences for the two | |
| 734 | * sequences). | |
| 735 | */ | |
| 736 | // SIDE-EFFECT: acf stores the aligned sequence reseq; to remove! | |
| 737 | 217 | acf.addMap(selection, rseq, map); |
| 738 | 217 | return rseq; |
| 739 | } | |
| 740 | } | |
| 741 | // register the mapping somehow | |
| 742 | // | |
| 743 | 0 | return null; |
| 744 | } | |
| 745 | ||
| 746 | /** | |
| 747 | * Insert a gap into the aligned proteins and the codon mapping array. | |
| 748 | * | |
| 749 | * @param pos | |
| 750 | * @param proteinSeqs | |
| 751 | * @return | |
| 752 | */ | |
| 753 | 178 | protected void insertAAGap(int pos, List<SequenceI> proteinSeqs) |
| 754 | { | |
| 755 | 178 | aaWidth++; |
| 756 | 178 | for (SequenceI seq : proteinSeqs) |
| 757 | { | |
| 758 | 598 | seq.insertCharAt(pos, gapChar); |
| 759 | } | |
| 760 | ||
| 761 | 178 | checkCodonFrameWidth(); |
| 762 | 178 | if (pos < aaWidth) |
| 763 | { | |
| 764 | 178 | aaWidth++; |
| 765 | ||
| 766 | /* | |
| 767 | * Shift from [pos] to the end one to the right, and null out [pos] | |
| 768 | */ | |
| 769 | 178 | System.arraycopy(alignedCodons, pos, alignedCodons, pos + 1, |
| 770 | alignedCodons.length - pos - 1); | |
| 771 | 178 | alignedCodons[pos] = null; |
| 772 | } | |
| 773 | } | |
| 774 | ||
| 775 | /** | |
| 776 | * Check the codons array can accommodate a single insertion, if not resize | |
| 777 | * it. | |
| 778 | */ | |
| 779 | 178 | protected void checkCodonFrameWidth() |
| 780 | { | |
| 781 | 178 | if (alignedCodons[alignedCodons.length - 1] != null) |
| 782 | { | |
| 783 | /* | |
| 784 | * arraycopy insertion would bump a filled slot off the end, so expand. | |
| 785 | */ | |
| 786 | 0 | AlignedCodon[] c = new AlignedCodon[alignedCodons.length + 10]; |
| 787 | 0 | System.arraycopy(alignedCodons, 0, c, 0, alignedCodons.length); |
| 788 | 0 | alignedCodons = c; |
| 789 | } | |
| 790 | } | |
| 791 | ||
| 792 | /** | |
| 793 | * Given a peptide newly translated from a dna sequence, copy over and set any | |
| 794 | * features on the peptide from the DNA. | |
| 795 | * | |
| 796 | * @param dna | |
| 797 | * @param pep | |
| 798 | * @param map | |
| 799 | */ | |
| 800 | 217 | private static void transferCodedFeatures(SequenceI dna, SequenceI pep, |
| 801 | MapList map) | |
| 802 | { | |
| 803 | // BH 2019.01.25 nop? | |
| 804 | // List<DBRefEntry> dnarefs = DBRefUtils.selectRefs(dna.getDBRefs(), | |
| 805 | // DBRefSource.DNACODINGDBS); | |
| 806 | // if (dnarefs != null) | |
| 807 | // { | |
| 808 | // // intersect with pep | |
| 809 | // for (int d = 0, nd = dnarefs.size(); d < nd; d++) | |
| 810 | // { | |
| 811 | // Mapping mp = dnarefs.get(d).getMap(); | |
| 812 | // if (mp != null) | |
| 813 | // { | |
| 814 | // } | |
| 815 | // } | |
| 816 | // } | |
| 817 | 217 | for (SequenceFeature sf : dna.getFeatures().getAllFeatures()) |
| 818 | { | |
| 819 | 0 | if (FeatureProperties.isCodingFeature(null, sf.getType())) |
| 820 | { | |
| 821 | // if (map.intersectsFrom(sf[f].begin, sf[f].end)) | |
| 822 | { | |
| 823 | ||
| 824 | } | |
| 825 | } | |
| 826 | } | |
| 827 | } | |
| 828 | ||
| 829 | /** | |
| 830 | * Returns an alignment consisting of the reversed (and optionally | |
| 831 | * complemented) sequences set in this object's constructor | |
| 832 | * | |
| 833 | * @param complement | |
| 834 | * @return | |
| 835 | */ | |
| 836 | 1 | public AlignmentI reverseCdna(boolean complement) |
| 837 | { | |
| 838 | 1 | int sSize = selection.size(); |
| 839 | 1 | List<SequenceI> reversed = new ArrayList<>(); |
| 840 | 2 | for (int s = 0; s < sSize; s++) |
| 841 | { | |
| 842 | 1 | SequenceI newseq = reverseSequence(selection.get(s).getName(), |
| 843 | seqstring[s], complement); | |
| 844 | ||
| 845 | 1 | if (newseq != null) |
| 846 | { | |
| 847 | 1 | reversed.add(newseq); |
| 848 | } | |
| 849 | } | |
| 850 | ||
| 851 | 1 | SequenceI[] newseqs = reversed.toArray(new SequenceI[reversed.size()]); |
| 852 | 1 | AlignmentI al = new Alignment(newseqs); |
| 853 | 1 | ((Alignment) al).createDatasetAlignment(); |
| 854 | 1 | return al; |
| 855 | } | |
| 856 | ||
| 857 | /** | |
| 858 | * Returns a reversed, and optionally complemented, sequence. The new | |
| 859 | * sequence's name is the original name with "|rev" or "|revcomp" appended. | |
| 860 | * aAcCgGtT and DNA ambiguity codes are complemented, any other characters are | |
| 861 | * left unchanged. | |
| 862 | * | |
| 863 | * @param seq | |
| 864 | * @param complement | |
| 865 | * @return | |
| 866 | */ | |
| 867 | 3 | public static SequenceI reverseSequence(String seqName, String sequence, |
| 868 | boolean complement) | |
| 869 | { | |
| 870 | 3 | String newName = seqName + "|rev" + (complement ? "comp" : ""); |
| 871 | 3 | char[] originalSequence = sequence.toCharArray(); |
| 872 | 3 | int length = originalSequence.length; |
| 873 | 3 | char[] reversedSequence = new char[length]; |
| 874 | 3 | int bases = 0; |
| 875 | 63 | for (int i = 0; i < length; i++) |
| 876 | { | |
| 877 | 60 | char c = complement ? getComplement(originalSequence[i]) |
| 878 | : originalSequence[i]; | |
| 879 | 60 | reversedSequence[length - i - 1] = c; |
| 880 | 60 | if (!Comparison.isGap(c)) |
| 881 | { | |
| 882 | 45 | bases++; |
| 883 | } | |
| 884 | } | |
| 885 | 3 | SequenceI reversed = new Sequence(newName, reversedSequence, 1, bases); |
| 886 | 3 | return reversed; |
| 887 | } | |
| 888 | ||
| 889 | /** | |
| 890 | * Answers the reverse complement of the input string | |
| 891 | * | |
| 892 | * @see #getComplement(char) | |
| 893 | * @param s | |
| 894 | * @return | |
| 895 | */ | |
| 896 | 36 | public static String reverseComplement(String s) |
| 897 | { | |
| 898 | 36 | StringBuilder sb = new StringBuilder(s.length()); |
| 899 | 76 | for (int i = s.length() - 1; i >= 0; i--) |
| 900 | { | |
| 901 | 40 | sb.append(Dna.getComplement(s.charAt(i))); |
| 902 | } | |
| 903 | 36 | return sb.toString(); |
| 904 | } | |
| 905 | ||
| 906 | /** | |
| 907 | * Returns dna complement (preserving case) for aAcCgGtTuU. Ambiguity codes | |
| 908 | * are treated as on http://reverse-complement.com/. Anything else is left | |
| 909 | * unchanged. | |
| 910 | * | |
| 911 | * @param c | |
| 912 | * @return | |
| 913 | */ | |
| 914 | 106 | public static char getComplement(char c) |
| 915 | { | |
| 916 | 106 | char result = c; |
| 917 | 106 | switch (c) |
| 918 | { | |
| 919 | 7 | case '-': |
| 920 | 0 | case '.': |
| 921 | 0 | case ' ': |
| 922 | 7 | break; |
| 923 | 2 | case 'a': |
| 924 | 2 | result = 't'; |
| 925 | 2 | break; |
| 926 | 13 | case 'A': |
| 927 | 13 | result = 'T'; |
| 928 | 13 | break; |
| 929 | 3 | case 'c': |
| 930 | 3 | result = 'g'; |
| 931 | 3 | break; |
| 932 | 22 | case 'C': |
| 933 | 22 | result = 'G'; |
| 934 | 22 | break; |
| 935 | 3 | case 'g': |
| 936 | 3 | result = 'c'; |
| 937 | 3 | break; |
| 938 | 17 | case 'G': |
| 939 | 17 | result = 'C'; |
| 940 | 17 | break; |
| 941 | 3 | case 't': |
| 942 | 3 | result = 'a'; |
| 943 | 3 | break; |
| 944 | 6 | case 'T': |
| 945 | 6 | result = 'A'; |
| 946 | 6 | break; |
| 947 | 1 | case 'u': |
| 948 | 1 | result = 'a'; |
| 949 | 1 | break; |
| 950 | 2 | case 'U': |
| 951 | 2 | result = 'A'; |
| 952 | 2 | break; |
| 953 | 2 | case 'r': |
| 954 | 2 | result = 'y'; |
| 955 | 2 | break; |
| 956 | 1 | case 'R': |
| 957 | 1 | result = 'Y'; |
| 958 | 1 | break; |
| 959 | 1 | case 'y': |
| 960 | 1 | result = 'r'; |
| 961 | 1 | break; |
| 962 | 2 | case 'Y': |
| 963 | 2 | result = 'R'; |
| 964 | 2 | break; |
| 965 | 2 | case 'k': |
| 966 | 2 | result = 'm'; |
| 967 | 2 | break; |
| 968 | 1 | case 'K': |
| 969 | 1 | result = 'M'; |
| 970 | 1 | break; |
| 971 | 1 | case 'm': |
| 972 | 1 | result = 'k'; |
| 973 | 1 | break; |
| 974 | 2 | case 'M': |
| 975 | 2 | result = 'K'; |
| 976 | 2 | break; |
| 977 | 2 | case 'b': |
| 978 | 2 | result = 'v'; |
| 979 | 2 | break; |
| 980 | 1 | case 'B': |
| 981 | 1 | result = 'V'; |
| 982 | 1 | break; |
| 983 | 1 | case 'v': |
| 984 | 1 | result = 'b'; |
| 985 | 1 | break; |
| 986 | 2 | case 'V': |
| 987 | 2 | result = 'B'; |
| 988 | 2 | break; |
| 989 | 2 | case 'd': |
| 990 | 2 | result = 'h'; |
| 991 | 2 | break; |
| 992 | 1 | case 'D': |
| 993 | 1 | result = 'H'; |
| 994 | 1 | break; |
| 995 | 1 | case 'h': |
| 996 | 1 | result = 'd'; |
| 997 | 1 | break; |
| 998 | 2 | case 'H': |
| 999 | 2 | result = 'D'; |
| 1000 | 2 | break; |
| 1001 | } | |
| 1002 | ||
| 1003 | 106 | return result; |
| 1004 | } | |
| 1005 | } |