Coverage Report
File RegexTokenizer.java
Coverage histogram
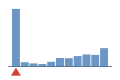
60% of files have more coverage
Classes
Class |
Line # |
Actions |
|||
|---|---|---|---|---|---|
| RegexTokenizer | 24 | 46 | 20 |
Contributing tests
Source view
| 1 | // | |
| 2 | // This software is now distributed according to | |
| 3 | // the Lesser Gnu Public License. Please see | |
| 4 | // http://www.gnu.org/copyleft/lesser.txt for | |
| 5 | // the details. | |
| 6 | // -- Happy Computing! | |
| 7 | // | |
| 8 | package com.stevesoft.pat; | |
| 9 | ||
| 10 | import java.util.Enumeration; | |
| 11 | import java.util.Vector; | |
| 12 | ||
| 13 | /** | |
| 14 | Shareware: package pat | |
| 15 | <a href="copyright.html">Copyright 2001, Steven R. Brandt</a> | |
| 16 | */ | |
| 17 | /** | |
| 18 | * The RegexTokenizer is similar to the StringTokenizer class provided with | |
| 19 | * java, but allows one to tokenize using regular expressions, rather than a | |
| 20 | * simple list of characters. Tokens are any strings between the supplied | |
| 21 | * regular expression, as well as any backreferences (things in parenthesis) | |
| 22 | * contained within the regular expression. | |
| 23 | */ | |
| 24 | public class RegexTokenizer implements Enumeration | |
| 25 | { | |
| 26 | String toParse; | |
| 27 | ||
| 28 | Regex r; | |
| 29 | ||
| 30 | int count = 0; | |
| 31 | ||
| 32 | Vector v = new Vector(); | |
| 33 | ||
| 34 | Vector vi = new Vector(); | |
| 35 | ||
| 36 | int pos = 0; | |
| 37 | ||
| 38 | int offset = 1; | |
| 39 | ||
| 40 | 0 |  void getMore() void getMore() |
| 41 | { | |
| 42 | 0 | String s = r.right(); |
| 43 | 0 | if (r.searchFrom(toParse, pos)) |
| 44 | { | |
| 45 | 0 | v.addElement(r.left().substring(pos)); |
| 46 | 0 | vi.addElement(Integer.valueOf(r.matchFrom() + r.charsMatched())); |
| 47 | 0 | for (int i = 0; i < r.numSubs(); i++) |
| 48 | { | |
| 49 | 0 | if (r.substring() != null) |
| 50 | { | |
| 51 | 0 | v.addElement(r.substring(i + offset)); |
| 52 | 0 | vi.addElement(Integer.valueOf( |
| 53 | r.matchFrom(i + offset) + r.charsMatched(i + offset))); | |
| 54 | } | |
| 55 | } | |
| 56 | 0 | pos = r.matchFrom() + r.charsMatched(); |
| 57 | } | |
| 58 | 0 | else if (s != null) |
| 59 | { | |
| 60 | 0 | v.addElement(s); |
| 61 | } | |
| 62 | } | |
| 63 | ||
| 64 | /** Initialize the tokenizer with a string of text and a pattern */ | |
| 65 | 0 | public RegexTokenizer(String txt, String ptrn) |
| 66 | { | |
| 67 | 0 | toParse = txt; |
| 68 | 0 | r = new Regex(ptrn); |
| 69 | 0 | offset = Regex.BackRefOffset; |
| 70 | 0 | getMore(); |
| 71 | } | |
| 72 | ||
| 73 | /** Initialize the tokenizer with a Regex object. */ | |
| 74 | 0 | public RegexTokenizer(String txt, Regex r) |
| 75 | { | |
| 76 | 0 | toParse = txt; |
| 77 | 0 | this.r = r; |
| 78 | 0 | offset = Regex.BackRefOffset; |
| 79 | 0 | getMore(); |
| 80 | } | |
| 81 | ||
| 82 | /** | |
| 83 | * This should always be cast to a String, as in StringTokenizer, and as in | |
| 84 | * StringTokenizer one can do this by calling nextString(). | |
| 85 | */ | |
| 86 | 0 | public Object nextElement() |
| 87 | { | |
| 88 | 0 | if (count >= v.size()) |
| 89 | { | |
| 90 | 0 | getMore(); |
| 91 | } | |
| 92 | 0 | return v.elementAt(count++); |
| 93 | } | |
| 94 | ||
| 95 | /** This is the equivalent (String)nextElement(). */ | |
| 96 | 0 | public String nextToken() |
| 97 | { | |
| 98 | 0 | return (String) nextElement(); |
| 99 | } | |
| 100 | ||
| 101 | /** | |
| 102 | * This asks for the next token, and changes the pattern being used at the | |
| 103 | * same time. | |
| 104 | */ | |
| 105 | 0 | public String nextToken(String newpat) |
| 106 | { | |
| 107 | 0 | try |
| 108 | { | |
| 109 | 0 | r.compile(newpat); |
| 110 | } catch (RegSyntax r_) | |
| 111 | { | |
| 112 | } | |
| 113 | 0 | return nextToken(r); |
| 114 | } | |
| 115 | ||
| 116 | /** | |
| 117 | * This asks for the next token, and changes the pattern being used at the | |
| 118 | * same time. | |
| 119 | */ | |
| 120 | 0 | public String nextToken(Regex nr) |
| 121 | { | |
| 122 | 0 | r = nr; |
| 123 | 0 | if (vi.size() > count) |
| 124 | { | |
| 125 | 0 | pos = ((Integer) vi.elementAt(count)).intValue(); |
| 126 | 0 | v.setSize(count); |
| 127 | 0 | vi.setSize(count); |
| 128 | } | |
| 129 | 0 | getMore(); |
| 130 | 0 | return nextToken(); |
| 131 | } | |
| 132 | ||
| 133 | /** Tells whether there are more tokens in the pattern. */ | |
| 134 | 0 | public boolean hasMoreElements() |
| 135 | { | |
| 136 | 0 | if (count >= v.size()) |
| 137 | { | |
| 138 | 0 | getMore(); |
| 139 | } | |
| 140 | 0 | return count < v.size(); |
| 141 | } | |
| 142 | ||
| 143 | /** | |
| 144 | * Tells whether there are more tokens in the pattern, but in the fashion of | |
| 145 | * StringTokenizer. | |
| 146 | */ | |
| 147 | 0 | public boolean hasMoreTokens() |
| 148 | { | |
| 149 | 0 | return hasMoreElements(); |
| 150 | } | |
| 151 | ||
| 152 | /** Determines the # of remaining tokens */ | |
| 153 | 0 | public int countTokens() |
| 154 | { | |
| 155 | 0 | int _count = count; |
| 156 | 0 | while (hasMoreTokens()) |
| 157 | { | |
| 158 | 0 | nextToken(); |
| 159 | } | |
| 160 | 0 | count = _count; |
| 161 | 0 | return v.size() - count; |
| 162 | } | |
| 163 | ||
| 164 | /** Returns all tokens in the String */ | |
| 165 | 0 | public String[] allTokens() |
| 166 | { | |
| 167 | 0 | countTokens(); |
| 168 | 0 | String[] ret = new String[v.size()]; |
| 169 | 0 | v.copyInto(ret); |
| 170 | 0 | return ret; |
| 171 | } | |
| 172 | }; |